
给Transformer变个形,LLM竟能变得更聪明
给Transformer变个形,LLM竟能变得更聪明2026 年 6 月,大模型行业正在经历一场前所未有的「开源海啸」:英伟达放出了 550B 参数的混合架构模型,谷歌送出多模态的 Gemma 新版本,智谱用最宽松的协议全量开源了自家旗舰模型。
来自主题: AI技术研报
7698 点击 2026-06-30 10:20
 搜索
搜索
2026 年 6 月,大模型行业正在经历一场前所未有的「开源海啸」:英伟达放出了 550B 参数的混合架构模型,谷歌送出多模态的 Gemma 新版本,智谱用最宽松的协议全量开源了自家旗舰模型。

如今,大模型越来越擅长回答问题了,但当 AI 不再只停留在聊天窗口,而是走向智能眼镜、可穿戴设备乃至家庭机器人时,问题会随之改变。用户未必有时间把需求完整说出来,也未必希望助手随时插话。更理想的助手,应该能在现场真正理解人,在用户需要的时候出现,在不合适的时候保持安静。

你有没有想过一个问题: 我们平时选模型,到底有多少是因为它真的好用,又有多少是因为它便宜?

就在今天凌晨,哈佛博士Douglas Yao在X宣布,研发了一款针对阿尔茨海默病的新药PAC-832,引发了数百人的围观。这是世界上第一个选择性GalR1拮抗剂,创始人表示全程使用了机器人自动化技术和AI大模型。
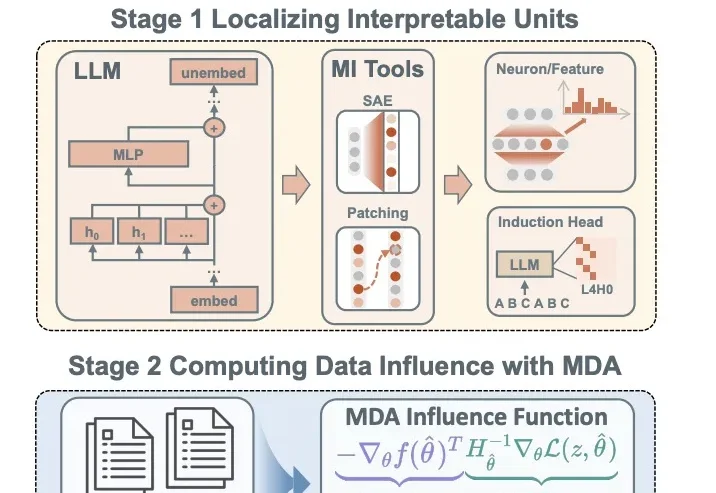
近年来,大语言模型展现出了越来越强的能力,从上下文学习(In-Context Learning, ICL)到复杂推理、代码生成,这些能力不断刷新人们对模型能力边界的认知。

这篇来自 Interlatent(一家聚焦具身智能后训练与部署的早期创业公司) 的文章,试图从第一性原理出发,把现代 AI 机器人技术重新讲清楚:一个机器人到底如何理解世界,如何生成动作,又为什么会在数据、延迟和泛化上遇到如此多的困难。

短短四个月,四家中国顶级AI公司被Anthropic接连点名,且没有停手的迹象。Anthropic向美国参议院银行委员会递交了一封信,矛头直指阿里Qwen团队。报告披露了一串数字:从4月22日到6月5日,整整45天,阿里相关运营者利用2.5万个账号,完成了2880万次交互。
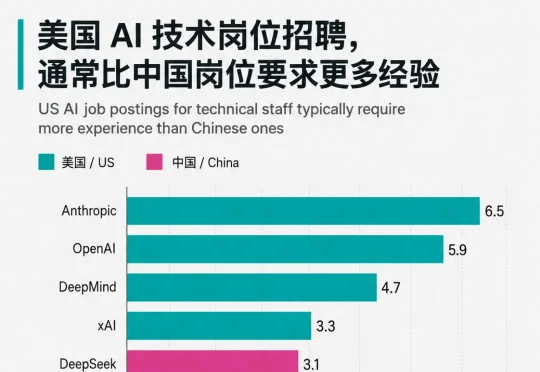
同样是进顶尖 AI 公司当工程师,在中国你只要 1.6 年经验,在美国却得熬到 5.5 年。换句话说,一个中国应届生刚拿到毕业证,就可能坐在 DeepSeek 的工位上调大模型;而他的美国同行还得在别的公司再「实习」四年,才够格投一份前沿 AI 实验室的简历。

来自至知创新研究院(IQuest Research)、中国人民大学高瓴人工智能学院、KAUST等机构的研究团队提出了FORT,一个面向Deep Search Agent的shortcut-resistant training-data synthesis framework。

6 月 25 日至 26 日,第 21 届开源中国·开源世界高峰论坛在北京中关村展示中心举行。本届大会由开源软件推进联盟(COPU)名誉主席、国际开源领袖奖获得者陆首群发起,本届大会由开源软件推进联盟(COPU)名誉主席、国际开源领袖奖获得者陆首群发起,由 COPU 主办、CSDN 承办,来自国际顶尖基金会、