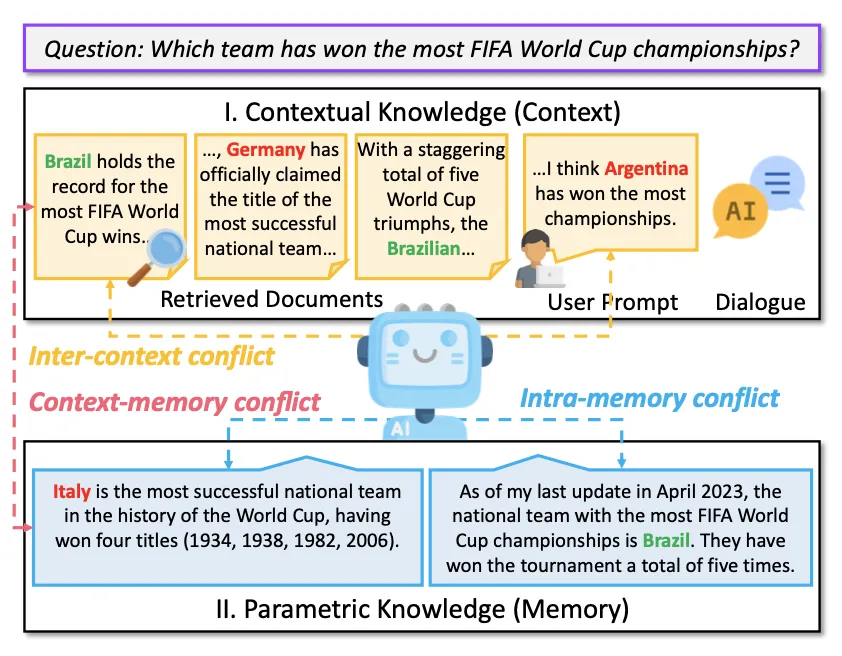
深度解析RAG大模型知识冲突,清华西湖大学港中文联合发布
深度解析RAG大模型知识冲突,清华西湖大学港中文联合发布随着人工智能和大型模型技术的迅猛发展,检索增强生成(Retrieval-Augmented Generation, RAG)已成为大型语言模型生成文本的一种主要范式。
来自主题: AI技术研报
11651 点击 2024-07-10 18:43
 搜索
搜索
随着人工智能和大型模型技术的迅猛发展,检索增强生成(Retrieval-Augmented Generation, RAG)已成为大型语言模型生成文本的一种主要范式。
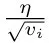
在训练大型语言模型(LLM)时,Adam(W) 基本上已经成为了人们默认使用的优化器。

瑞士苏黎世联邦理工学院的研究者发现,为ChatGPT等聊天机器人提供支持的大型语言模型可以从看似无害的对话中,准确推断出数量惊人的用户个人信息,包括他们的种族、位置、职业等。

1981年,对冲基金传奇人物雷·达利欧提出,若存在一台存储世上所有事实数据并运行完美程序的计算机,未来即可被准确预测。 尽管我们尚未达到这一水平,但技术进步迅猛,以ChatGPT为代表的大型语言模型,已展现出预测未来的潜力。

自 ChatGPT 发布以来,大型语言模型(LLM)已经成为推动人工智能发展的关键技术。

香港大学推出的XRec模型通过融合大型语言模型的语义理解和协同过滤技术,增强了推荐系统的可解释性,使用户能够理解推荐背后的逻辑。这一创新成果不仅提升了用户体验,也为推荐技术的未来发展提供了新方向和动力。

基于 Transformer架构的大型语言模型在各种基准测试中展现出优异性能,但数百亿、千亿乃至万亿量级的参数规模会带来高昂的服务成本。例如GPT-3有1750亿参数,采用FP16存储,模型大小约为350GB,而即使是英伟达最新的B200 GPU 内存也只有192GB ,更不用说其他GPU和边缘设备。

近些年,语言建模领域进展非凡。Llama 或 ChatGPT 等许多大型语言模型(LLM)有能力解决多种不同的任务,它们也正在成为越来越常用的工具。

大型语言模型(LLM)的一个主要特点是「大」,也因此其训练和部署成本都相当高,如何在保证 LLM 准确度的同时让其变小就成了非常重要且有价值的研究课题。

从大规模网络爬取、精细过滤到去重技术,通过FineWeb的技术报告探索如何打造高质量数据集,为大型语言模型(LLM)预训练提供更优质的性能。