
是RAG已死,还是RAG Anything,All in RAG?
是RAG已死,还是RAG Anything,All in RAG?每隔一阵子,总有人宣告“RAG已死”:上下文越来越长、端到端多模态模型越来越强,好像不再需要检索与证据拼装。但真正落地到复杂文档与可溯源场景,你会发现死掉的只是“只切文本的旧RAG”。
来自主题: AI技术研报
7760 点击 2025-10-20 12:08
 搜索
搜索
每隔一阵子,总有人宣告“RAG已死”:上下文越来越长、端到端多模态模型越来越强,好像不再需要检索与证据拼装。但真正落地到复杂文档与可溯源场景,你会发现死掉的只是“只切文本的旧RAG”。

2 天前,国内最大的 AI 多模态模型社区之一的 LiblibAI 进行了一次大升级,正式推出了 2.0 版本。对许多创作者而言,这个平台并不陌生,LiblibAI 一直是国内开源绘画与 LoRA 文化的重要发源地,也常被称为中国版的 CivitAI (大家常说的 C 站)。

多模态大模型首次实现像素级推理,指代、分割、推理三大任务一网打尽!
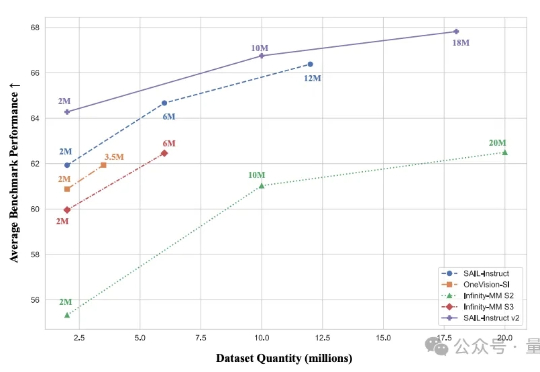
2B模型在多个基准位列4B参数以下开源第一。 抖音SAIL团队与LV-NUS Lab联合推出的多模态大模型SAIL-VL2。

奇多多AI学伴机是由无界方舟发布的国内首款基于「端到端实时多模态互动模型」的AI互动机器人,于本月2025外滩大会首次亮相。京东预售仅上线一周,销量便突破了10000台,在看似红海的儿童早教市场掀起波澜。在功能体验方面,它带来了三大突破:能“看”世界的眼睛、堪比真人的低延迟反馈速度、能“成长”的个性化陪伴感。
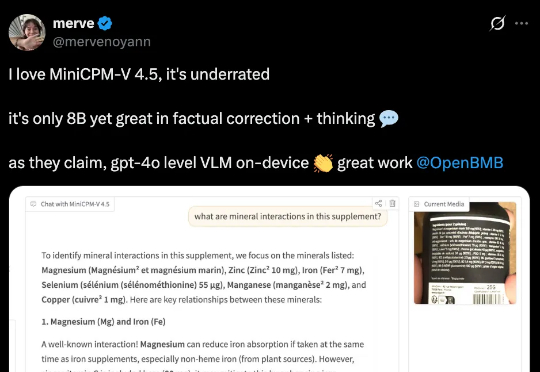
行业首个具备“高刷”视频理解能力的多模态模型MiniCPM-V 4.5的技术报告正式发布!报告提出统一的3D-Resampler架构实现高密度视频压缩、面向文档的统一OCR和知识学习范式、可控混合快速/深度思考的多模态强化学习三大技术。
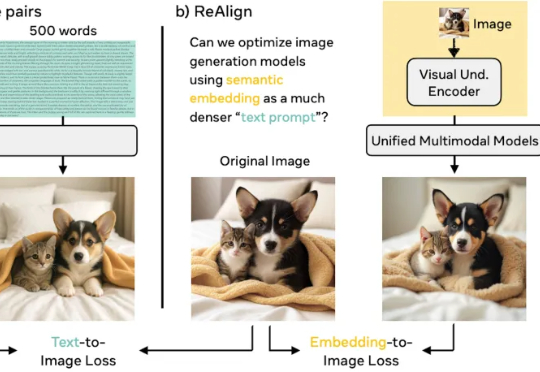
谢集,浙江大学竺可桢学院大四学生,于加州大学伯克利分校(BAIR)进行访问,研究方向为统一多模态理解生成大模型。第二作者为加州大学伯克利分校的 Trevor Darrell,第三作者为华盛顿大学的 Luke Zettlemoyer,通讯作者是 XuDong Wang, Meta GenAl Research Scientist、

今天,我们正式开源 8B 参数的面壁小钢炮 MiniCPM-V 4.5 多模态旗舰模型,成为行业首个具备“高刷”视频理解能力的多模态模型,看得准、看得快,看得长!高刷视频理解、长视频理解、OCR、文档解析能力同级 SOTA,且性能超过 Qwen2.5-VL 72B,堪称最强端侧多模态模型。

智谱基于GLM-4.5打造的开源多模态视觉推理模型GLM-4.5V,在42个公开榜单中41项夺得SOTA!其功能涵盖图像、视频、文档理解、Grounding、地图定位、空间关系推理、UI转Code等。
上上周一的晚上,智谱开源了当今最好的模型之一,GLM-4.5。 然后,这个周一,又是突如其来的,开源了他们现在最好的多模态模型: GLM-4.5v。