
ICML 2026 | 只用少量Thinking Tokens,大模型依然能深度思考
ICML 2026 | 只用少量Thinking Tokens,大模型依然能深度思考近年来,Chain-of-Thought(CoT)推理已经成为提升大语言模型和多模态大语言模型复杂问题求解能力的重要技术路径。
来自主题: AI技术研报
7156 点击 2026-05-19 10:01
 搜索
搜索
近年来,Chain-of-Thought(CoT)推理已经成为提升大语言模型和多模态大语言模型复杂问题求解能力的重要技术路径。
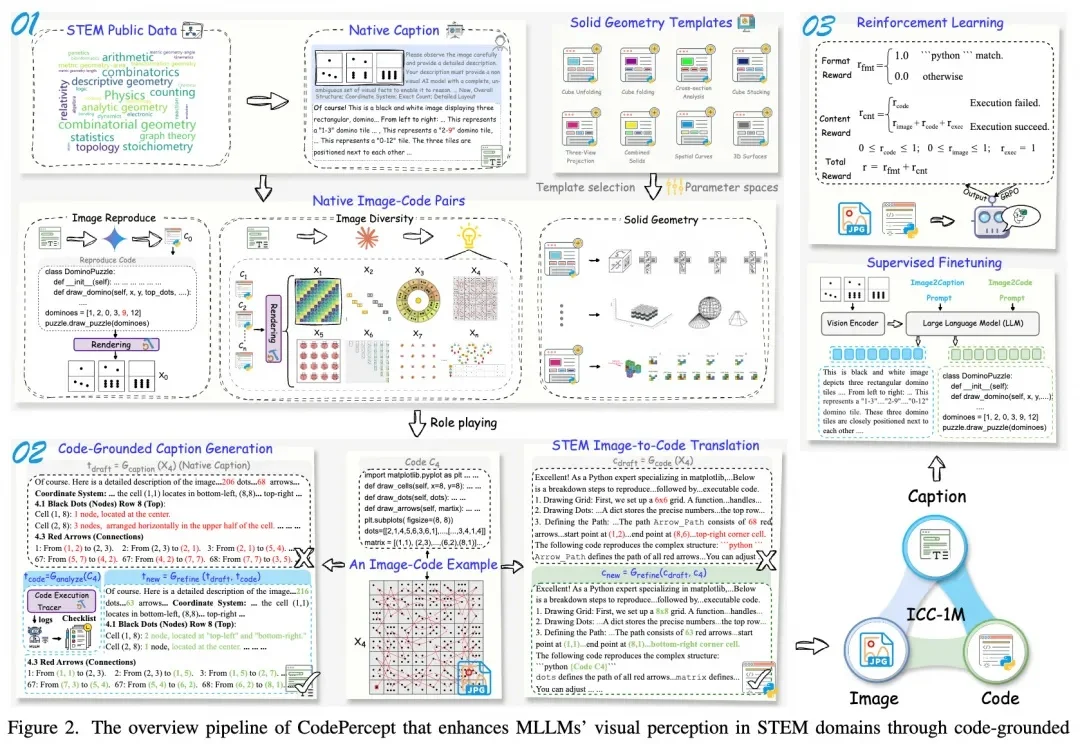
当多模态大语言模型(MLLMs)在面对科学、技术、工程和数学(STEM)领域的视觉推理题时频频「翻车」,一个根本性的问题摆在了所有研究者面前:大模型做不出理科题,究竟是因为「脑子笨」(推理能力受限),还是因为「眼神差」(视觉感知缺陷)?
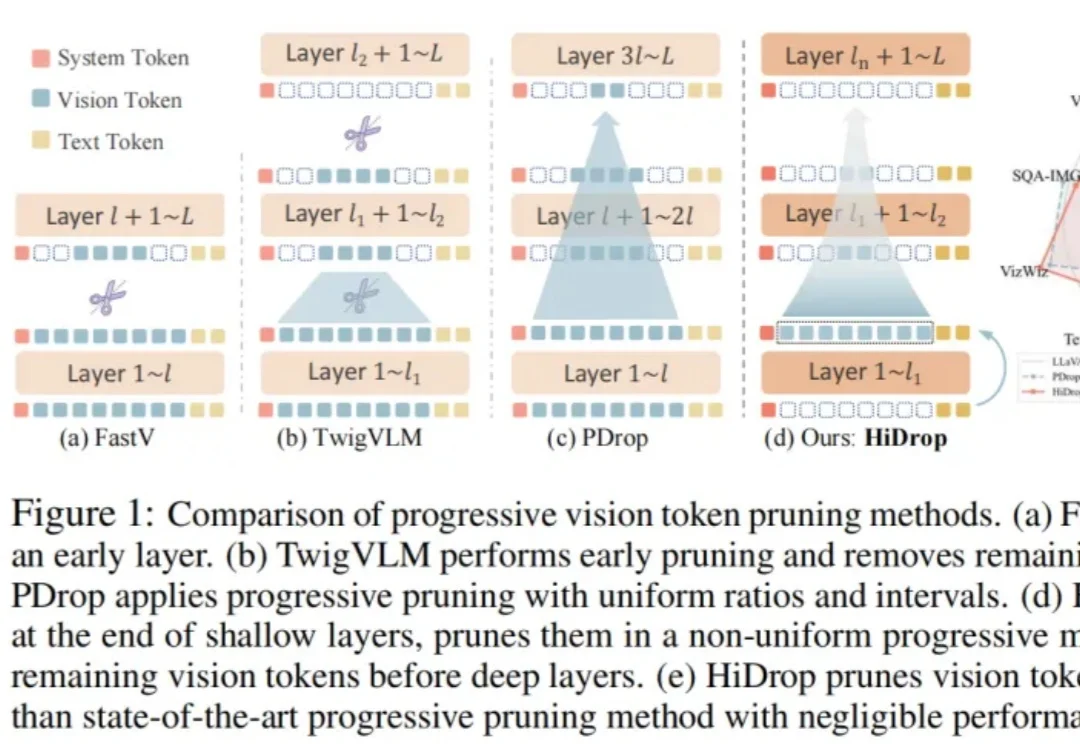
随着多模态大语言模型(MLLM)支持更长上下文,高分辨率图像和长视频会产生远多于文本的视觉 Token,在自注意力二次复杂度下迅速成为效率瓶颈。

刚刚,AI医疗新突破,来自谷歌!这一次,他们直接瞄准了真实临床环境的痛点。为此,谷歌祭出了最新模型MedGemma 1.5,找到了破局答案。相较于此前的MedGemma 1.5,MedGemma 1.5在多模态应用上实现重大突破,融合了:
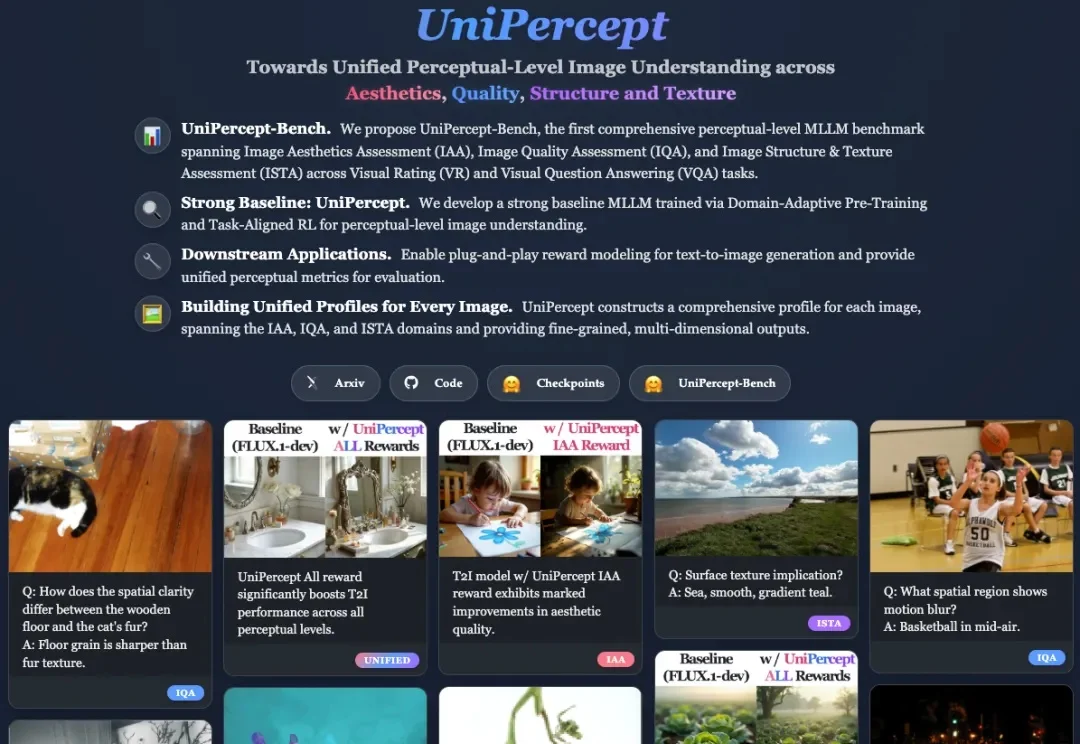
尽管多模态大语言模型(MLLMs)在识别「图中有什么」这一语义层面上取得了巨大进步,但在理解「图像看起来怎么样」这一感知层面上仍显乏力。

空间理解能力是多模态大语言模型(MLLMs)走向真实物理世界,成为 “通用型智能助手” 的关键基础。但现有的空间智能评测基准往往有两类问题:一类高度依赖模板生成,限制了问题的多样性;另一类仅聚焦于某一种空间任务与受限场景,因此很难全面检验模型在真实世界中对空间的理解与推理能力。
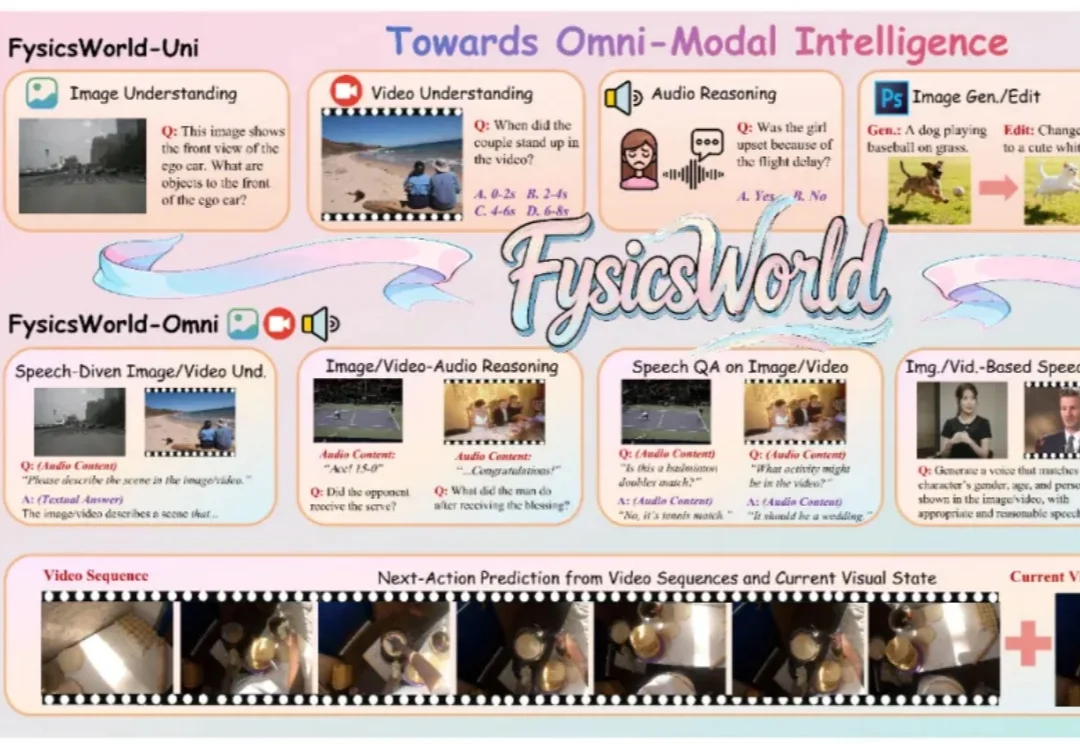
近年来,多模态大语言模型正在经历一场快速的范式转变,新兴研究聚焦于构建能够联合处理和生成跨语言、视觉、音频以及其他潜在感官模态信息的统一全模态大模型。此类模型的目标不仅是感知全模态内容,还要将视觉理解和生成整合到统一架构中,从而实现模态间的协同交互。

多模态大语言模型(MLLMs)已成为AI视觉理解的核心引擎,但其在真实世界视觉退化(模糊、噪声、遮挡等)下的性能崩溃,始终是制约产业落地的致命瓶颈。
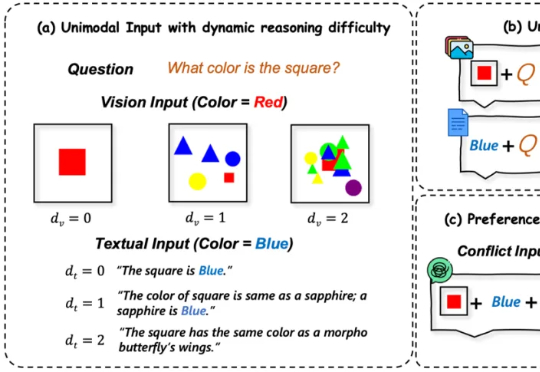
多模态大语言模型(MLLMs)在处理来自图像和文本等多种来源的信息时能力强大 。 然而,一个关键挑战随之而来:当这些模态呈现相互冲突的信息时(例如,图像显示一辆蓝色汽车,而文本描述它为红色),MLLM必须解决这种冲突 。模型最终输出与某一模态信息保持一致的行为,称之为“模态跟随”(modality following)
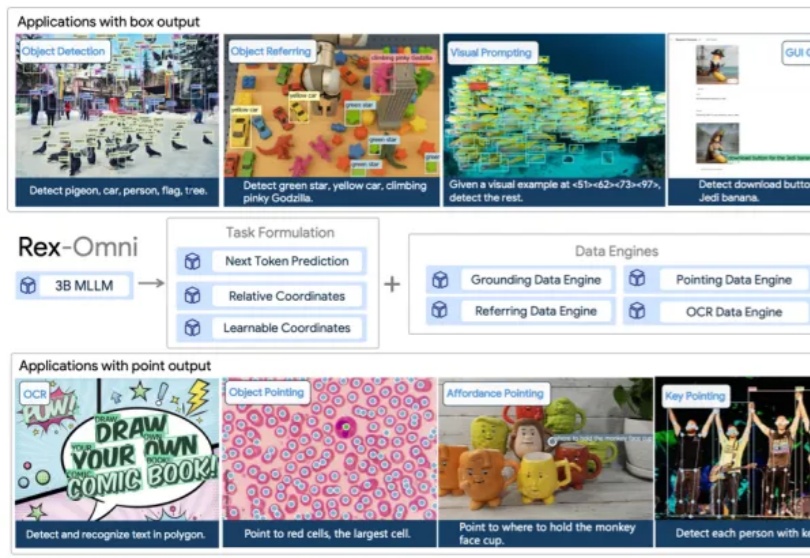
多模态大语言模型(MLLM)在目标定位精度上被长期诟病,难以匹敌传统的基于坐标回归的检测器。近日,来自 IDEA 研究院的团队通过仅有 3B 参数的通用视觉感知模型 Rex-Omni,打破了这一僵局。