
0.5秒,无需GPU,Stability AI与华人团队VAST开源单图生成3D模型TripoSR
0.5秒,无需GPU,Stability AI与华人团队VAST开源单图生成3D模型TripoSR最近,文生视频模型 Sora 掀起了新一轮生成式 AI 模型浪潮,模型的多模态能力引起广泛关注。
来自主题: AI技术研报
7739 点击 2024-03-05 14:30
 搜索
搜索
最近,文生视频模型 Sora 掀起了新一轮生成式 AI 模型浪潮,模型的多模态能力引起广泛关注。
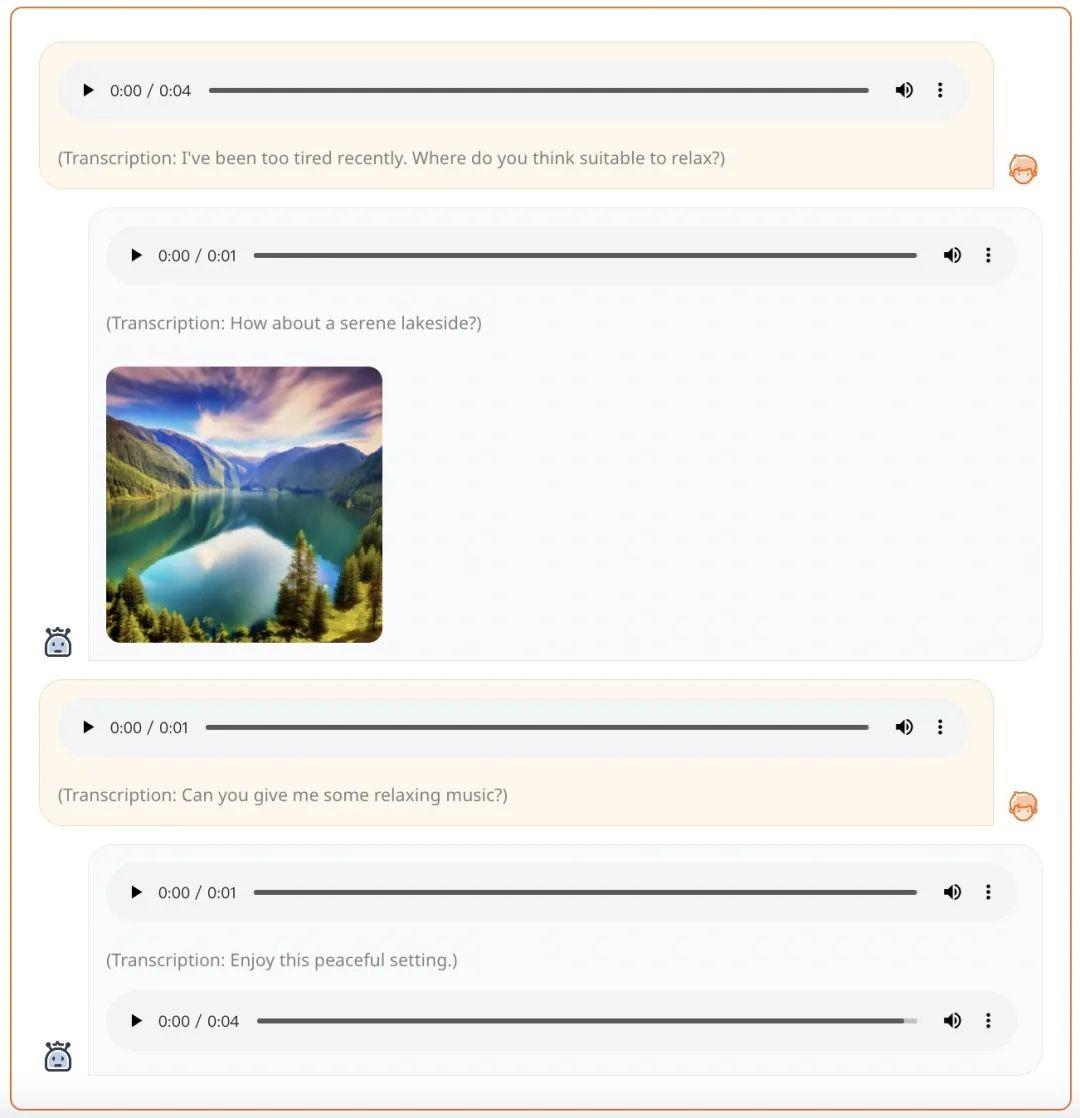
最近,OpenAI 的视频生成模型 Sora 爆火,生成式 AI 模型在多模态方面的能力再次引起广泛关注。

Google 最近在大模型上动作不断,先是发布了性能更强大的多模态 Gemini 1.5 Pro,然后是开源的小模型 Gemma,评测结果超过了 7b 量级的 Llama 2。

Ideogram凭借不输Midjourney的生图能力和遥遥领先的图片中文字渲染能力,获得了包括Jeff Dean和Karpathy在内一众大佬的8000万美元融资,文生图这条离钱最近的AI赛道又加入了一名重量级选手。

人形机器人已然成为科技和投资界的新宠!刚刚,OpenAI官宣将与独角兽Figure合作,专为机器人打造下一代AI大模型,具身AGI真的要来了。

2023 年我们正见证着多模态大模型的跨越式发展,多模态大语言模型(MLLM)已经在文本、代码、图像、视频等多模态内容处理方面表现出了空前的能力,成为技术新浪潮。以 Llama 2,Mixtral 为代表的大语言模型(LLM),以 GPT-4、Gemini、LLaVA 为代表的多模态大语言模型跨越式发展。

近日,杭州联汇科技股份有限公司(以下简称 “联汇科技”)宣布完成新一轮数亿元战略融资,投资方由中国移动产业链发展基金中移和创投资、前海方舟(前海母基金管理机构)旗下中原前海基金和齐鲁前海基金等多家头部国资与市场化机构组成。

2月28日,界面新闻从多个知情人士处获悉,字节跳动正在AI大模型领域秘密研发多个产品,其中包括多模态数字人产品以及AI生图、AI生视频产品等。

2月16日,OpenAI推出了堪称“王炸”的文生视频大模型Sora,AI军备竞赛的战场加速向多模态转移,这意味着相比寻常LLM更为丰富的场景与机会。此外,2024年将成为AI硬件元年的共识也基本形成,业界对AI在智能终端的应用寄予厚望,将其视为提振消费电子市场的关键。
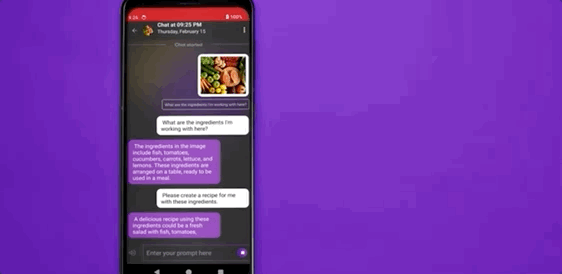
多模态大模型,首次本地部署在安卓手机上了!