
AI风口中的香港,想做全球AI的算力、数据、人才枢纽 | 最前线
AI风口中的香港,想做全球AI的算力、数据、人才枢纽 | 最前线2023年12月,宁德时代低调宣布在香港设立国际研发中心; 2024年3月11日,作为中国科学院在香港设立的首个国家级信息研发机构,中国科学院香港创新研究院人工智能与机器人创新中心发布了医疗多模态大模型CARES Copilot 1.0;
来自主题: AI资讯
10257 点击 2024-04-22 10:42
 搜索
搜索
2023年12月,宁德时代低调宣布在香港设立国际研发中心; 2024年3月11日,作为中国科学院在香港设立的首个国家级信息研发机构,中国科学院香港创新研究院人工智能与机器人创新中心发布了医疗多模态大模型CARES Copilot 1.0;

一个可以自动分析PDF、网页、海报、Excel图表内容的大模型,对于打工人来说简直不要太方便。

近日,由DeepMind、谷歌和Meta的研究人员创立的AI初创公司Reka,推出了他们最新的多模态语言模型——Reka Core
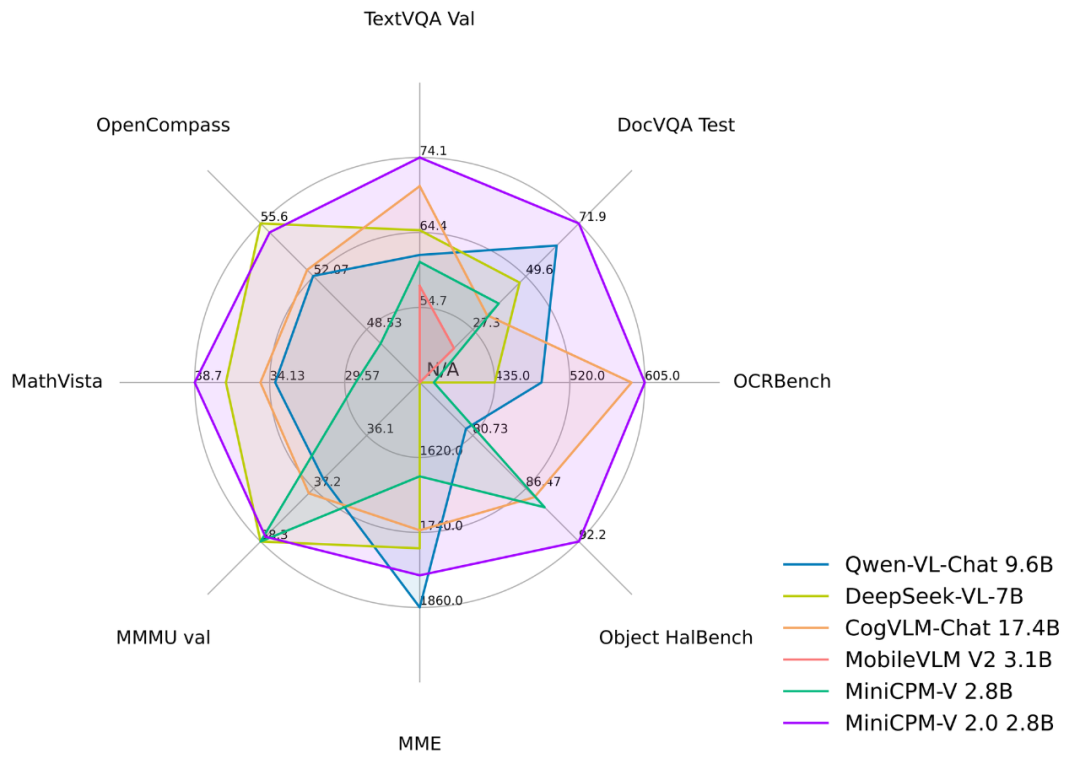
MiniCPM 系列的最新多模态版本 MiniCPM-V 2.0。该模型基于 MiniCPM 2.4B 和 SigLip-400M 构建,共拥有 2.8B 参数。MiniCPM-V 2.0 具有领先的光学字符识别(OCR)和多模态理解能力

马斯克的第一代多模态模型Grok-1.5V,终于来了!

刷爆多模态任务榜单,超强视觉语言模型Mini-Gemini来了! 效果堪称是开源社区版的GPT-4+DALL-E 3王炸组合。

自从 2023 年 11 月 Grok 首次亮相以来,马斯克的 xAI 正在大模型领域不断取得进步,向 OpenAI 等先行者发起进攻。在 Grok-1 开源后不到一个月,xAI 的首个多模态模型就问世了。

近,来自澳大利亚蒙纳士大学、蚂蚁集团、IBM 研究院等机构的研究人员探索了模型重编程 (model reprogramming) 在大语言模型 (LLMs) 上应用,并提出了一个全新的视角

识读距今2300多年战国时期的上古竹简,AI正在立功。 而且在这背后的“大功臣”,竟是只有2B大小的多模态大模型!

4 月 4 日,Y Combinator W2024 Batch Demo Day 正式开始。这次共亮相 260 个项目,YC 从 2.7 万份申请中筛选出来,通过率低于 1%,是历史上 YC 录取比例最低的一轮批次之一。