超级智能体生命力觉醒!可自我更新的AI来了,妈妈再也不用担心数据瓶颈难题
超级智能体生命力觉醒!可自我更新的AI来了,妈妈再也不用担心数据瓶颈难题训练模型搞得跟《饥饿游戏》似的,全球AI研究者,都在苦恼怎么才能喂饱这群数据大胃王。
来自主题: AI技术研报
7303 点击 2024-04-29 20:06
 搜索
搜索
训练模型搞得跟《饥饿游戏》似的,全球AI研究者,都在苦恼怎么才能喂饱这群数据大胃王。

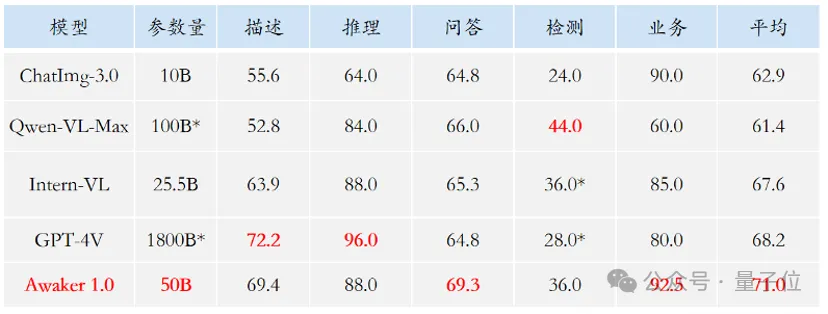
又一个国产多模态大模型开源! XVERSE-V,来自元象,还是同样的无条件免费商用。
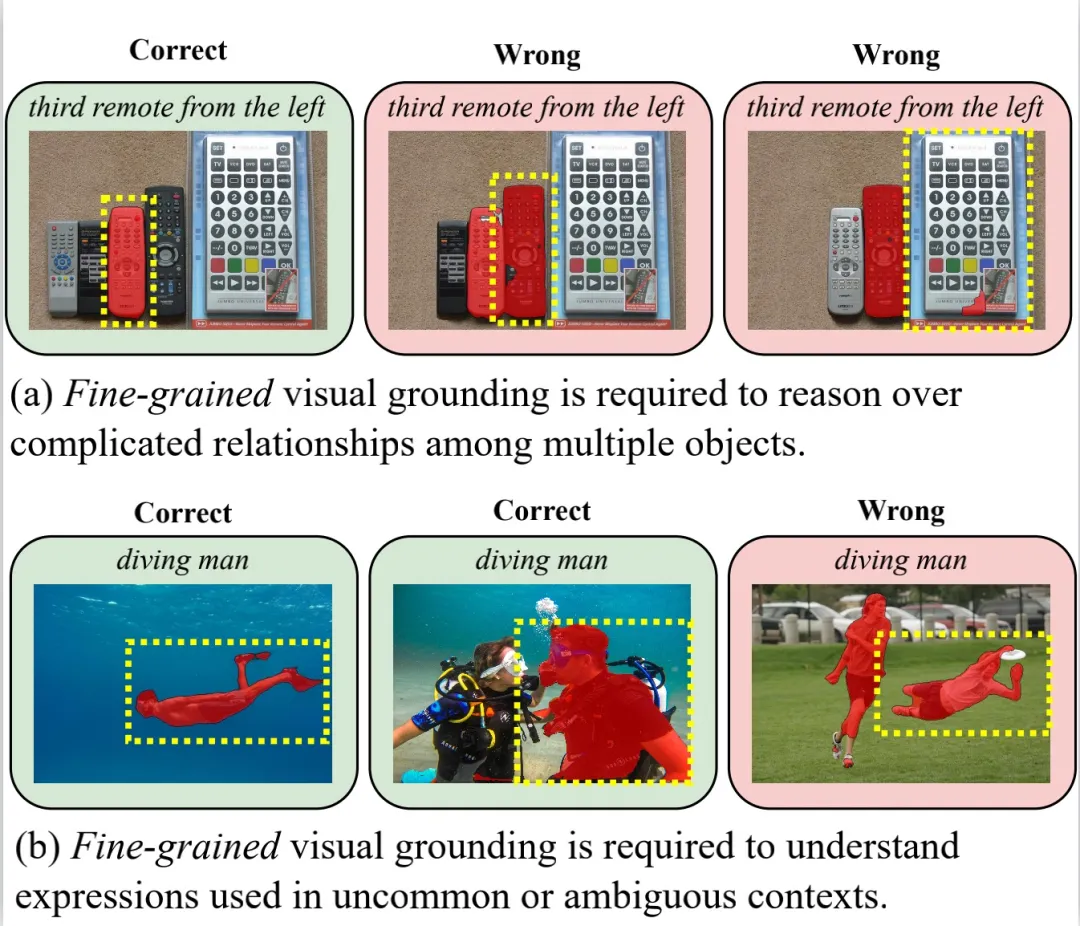
指代分割 (Referring Image Segmentation,RIS) 是一项极具挑战性的多模态任务,要求算法能够同时理解精细的人类语言和视觉图像信息,并将图像中句子所指代的物体进行像素级别的分割。

奔向通用人工智能,大模型又迈出一大步。
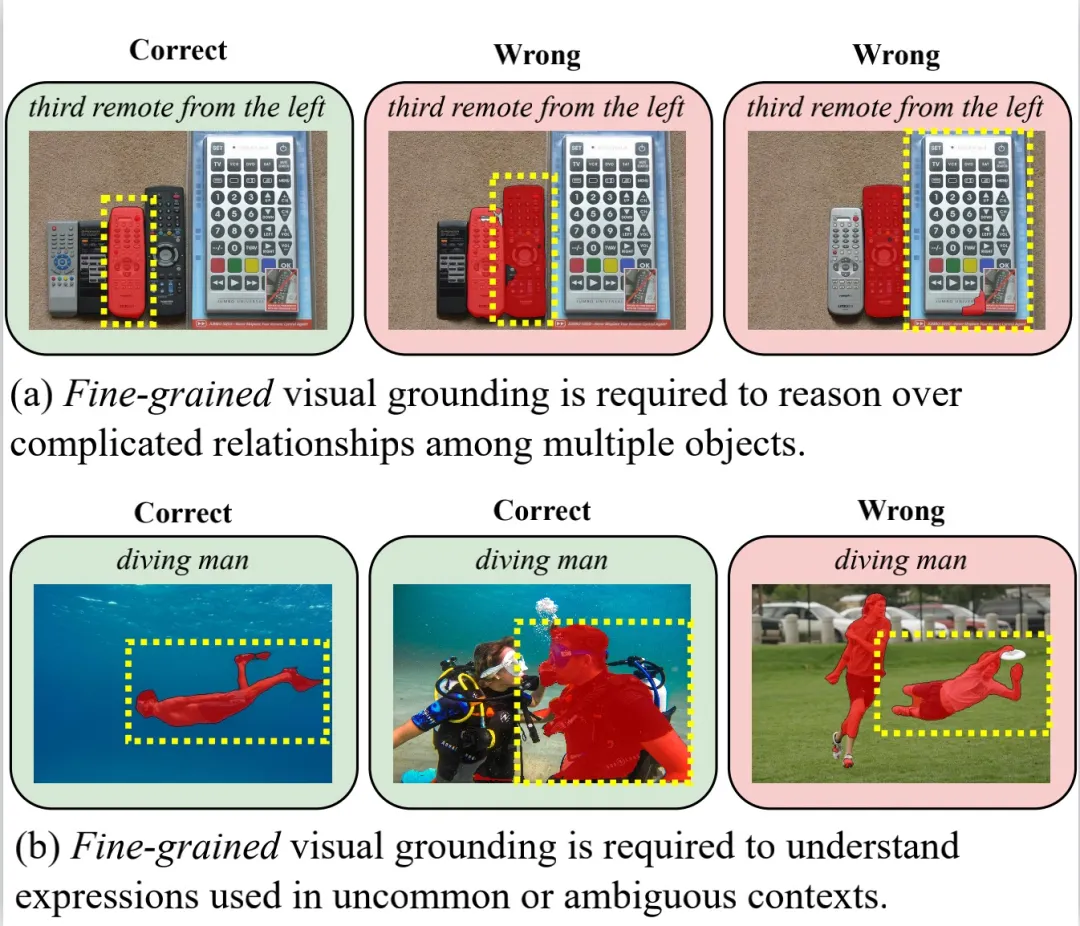
指代分割 (Referring Image Segmentation,RIS) 是一项极具挑战性的多模态任务,要求算法能够同时理解精细的人类语言和视觉图像信息,并将图像中句子所指代的物体进行像素级别的分割。
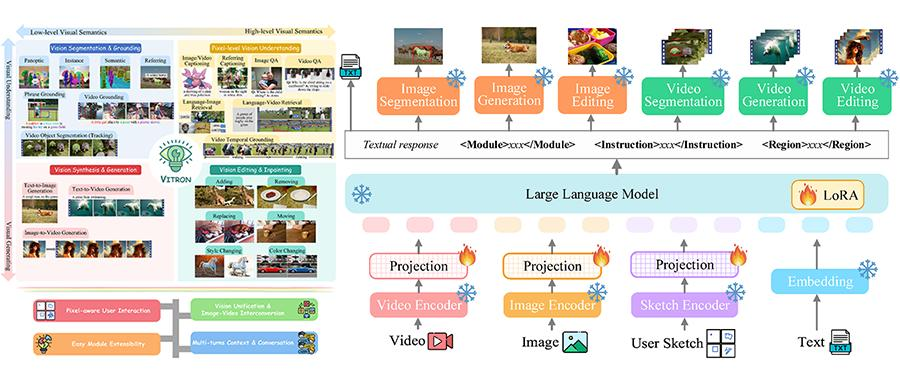
奔向通用人工智能,大模型又迈出一大步。

最近,一家名为 Reka 的初创公司发布了一款多模态语言模型——Reka Core,这是他们自2022 年成立以来第三款模型。

近期,多模态大模型 (MLLM) 在文本中心的 VQA 领域取得了显著进展,尤其是多个闭源模型,例如:GPT4V 和 Gemini,甚至在某些方面展现了超越人类能力的表现。

科幻大片中的AR黑科技,竟走进了现实! 就在刚刚,Meta自家的雷朋智能眼镜,已经开始支持多模态版的Llama 3了!要知道,Llama 3的开源版本还没支持多模态呢。
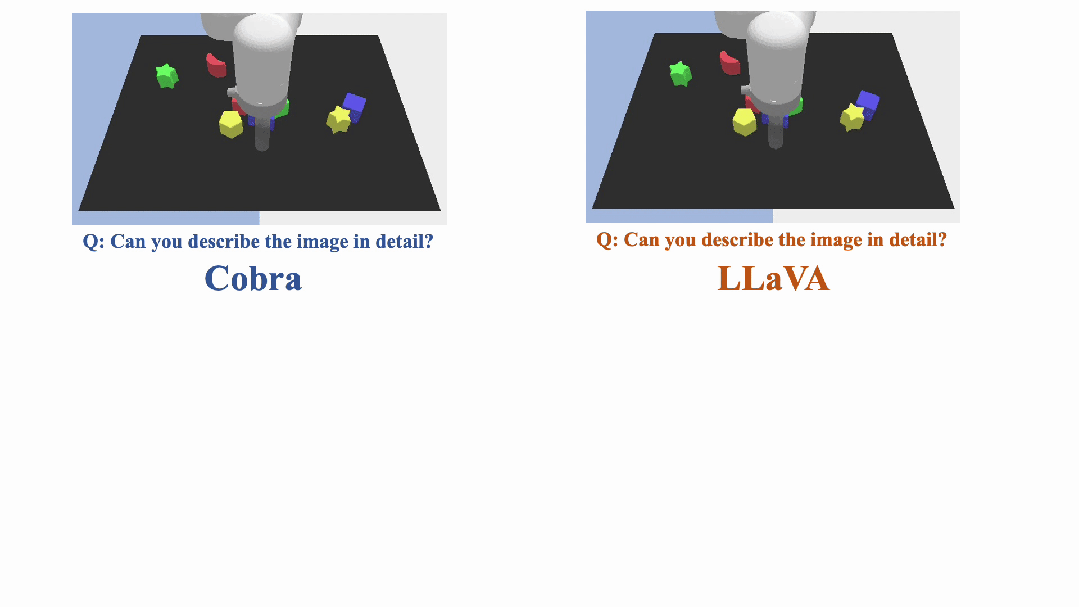
近年来,多模态大型语言模型(MLLM)在各个领域的应用取得了显著的成功。然而,作为许多下游任务的基础模型,当前的 MLLM 由众所周知的 Transformer 网络构成,这种网络具有较低效的二次计算复杂度。