喝点VC|a16z重磅预测:AI虚拟人将孕育众多市值达数十亿美元的行业巨头
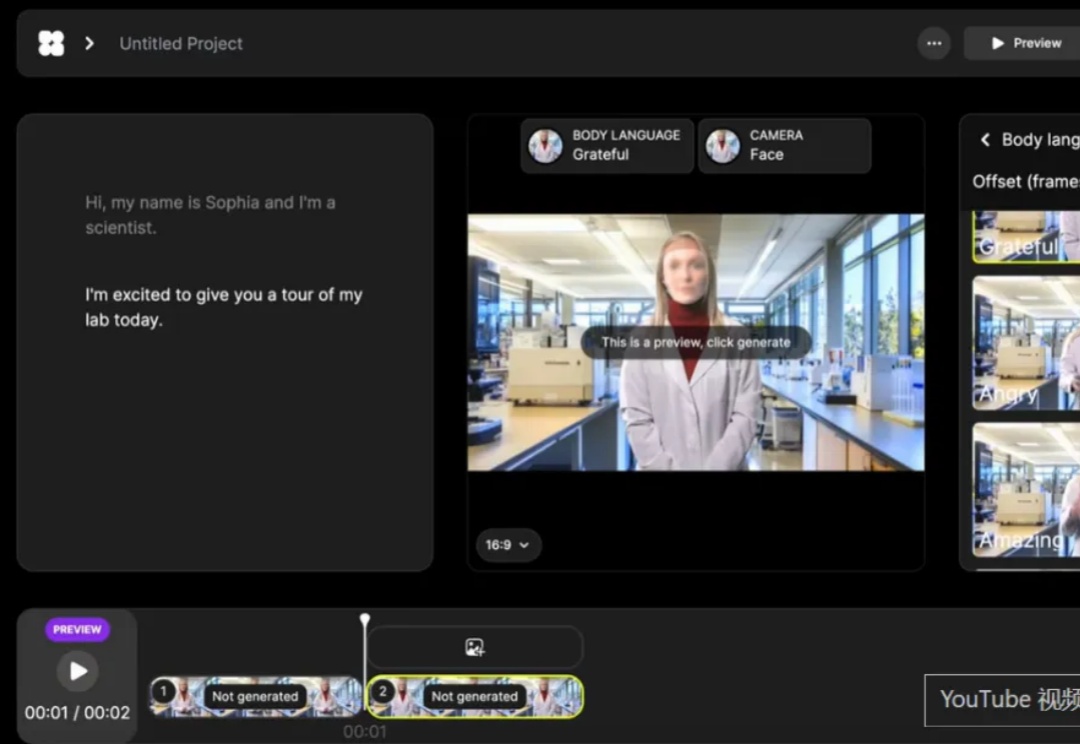
喝点VC|a16z重磅预测:AI虚拟人将孕育众多市值达数十亿美元的行业巨头AI虚拟人模型架构从CNN、GANs演进至Transformer+扩散模型,实现从单一面部驱动到半身/全身动态生成的跨越,口型同步与多模态协同表现显著提升。
来自主题: AI资讯
9889 点击 2025-04-23 15:17
 搜索
搜索
AI虚拟人模型架构从CNN、GANs演进至Transformer+扩散模型,实现从单一面部驱动到半身/全身动态生成的跨越,口型同步与多模态协同表现显著提升。

GPT-4o更新的端到端多模态模型,让创意端获得前所未有的自由度。
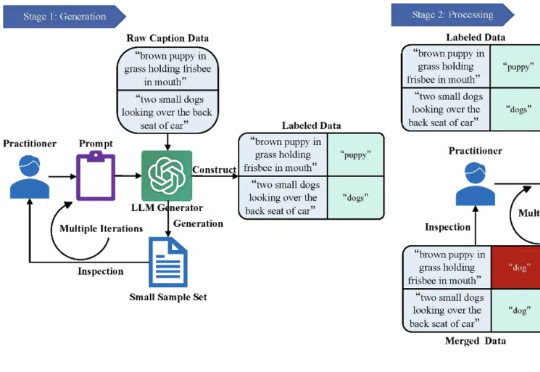
对于AI视觉多模态大模型只关注显著信息这一根本性缺陷,哈工大GiVE实现突破!
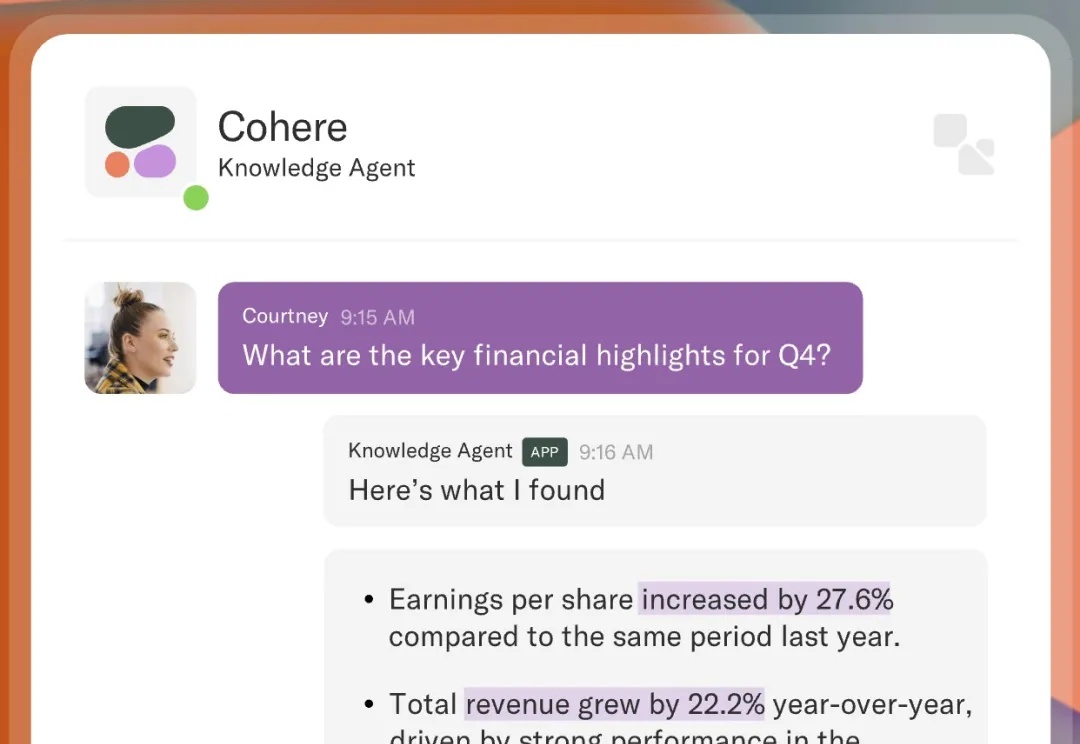
2025年4月16日,Cohere 发布了其最新一代多模态搜索模型 Embed 4,在多模态数据处理、长文本建模和跨模态检索能力上实现了显著提升,进一步巩固了其在企业级 AI 搜索领域的领先地位。

多模态生成技术持续突破内容创作的边界。
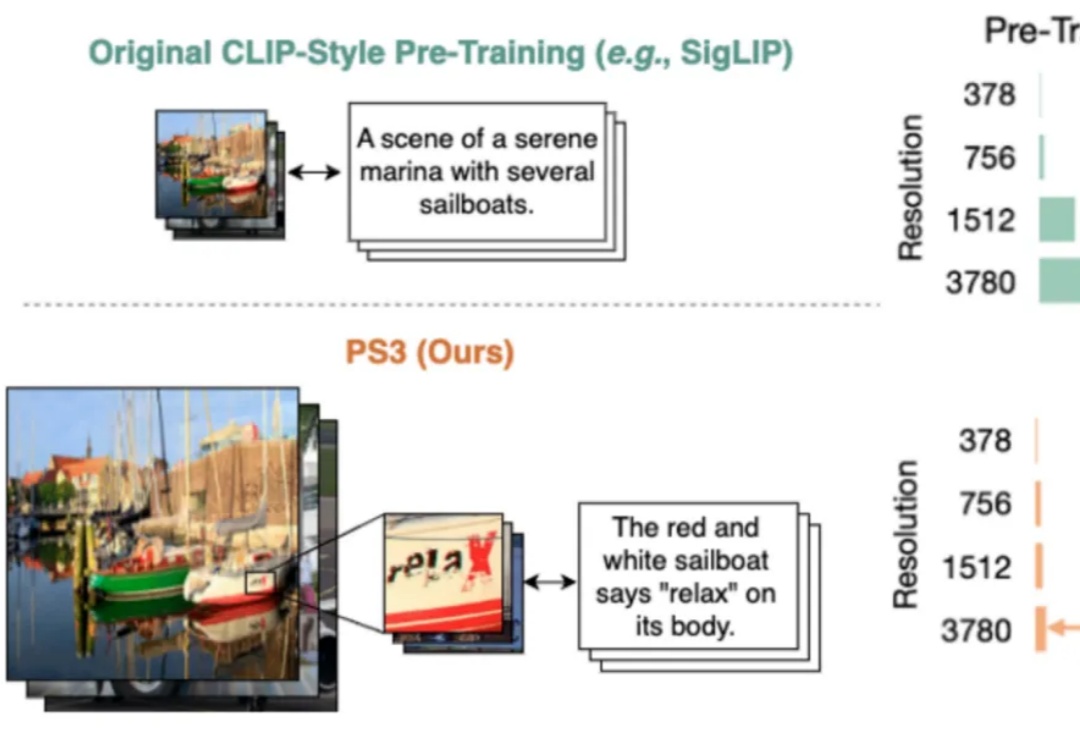
当前,所有主流的视觉基础模型(如 SigLIP、DINOv2 等)都仍然在低分辨率(如 384 * 384 分辨率)下进行预训练。对比人类视觉系统可以轻松达到 10K 等效分辨率,这种低分辨率预训练极大地限制了视觉模型对于高清细节的理解能力。
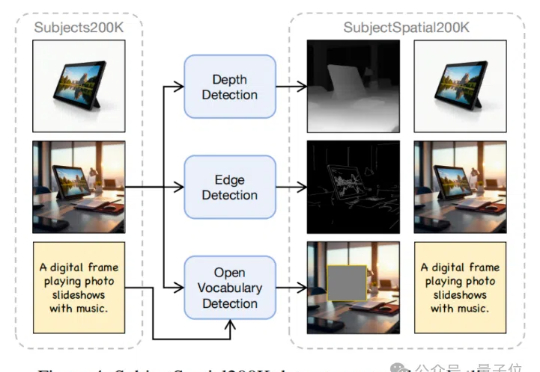
能处理任意条件组合的新生成框架来了!
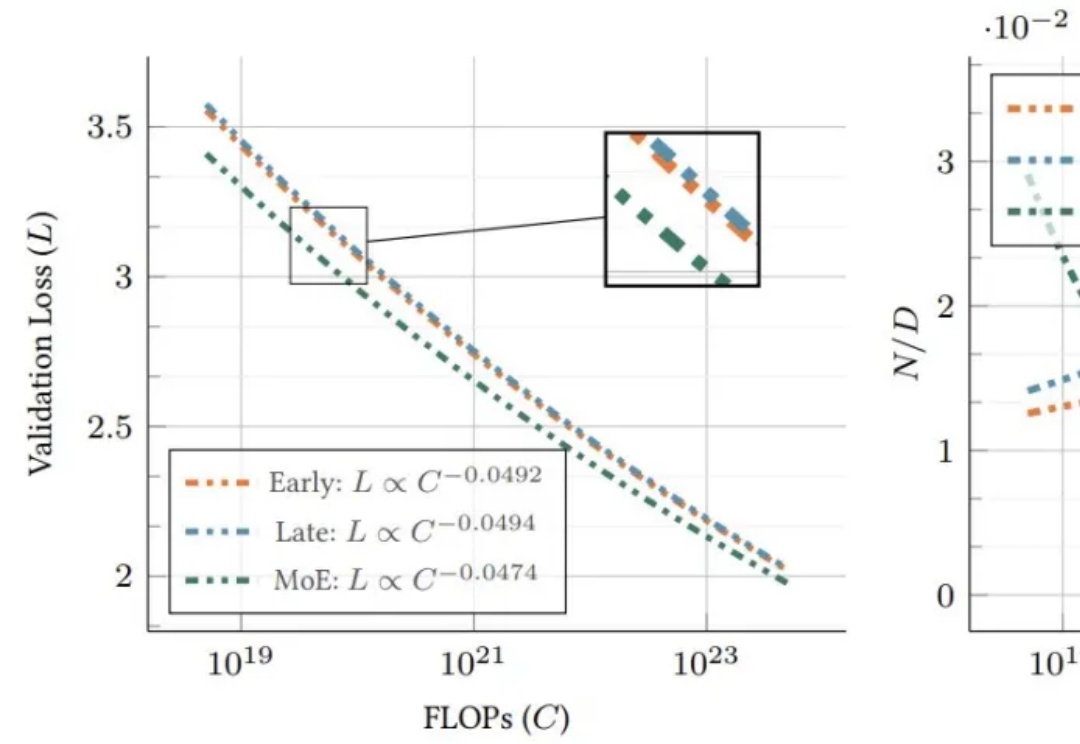
让大模型进入多模态模式,从而能够有效感知世界,是最近 AI 领域里人们一直的探索目标。

北京大学团队继VARGPT实现视觉理解与生成任务统一之后,再度推出了VARGPT-v1.1版本。该版本进一步提升了视觉自回归模型的能力,不仅在在视觉理解方面有所加强,还在图像生成和编辑任务中达到新的性能高度
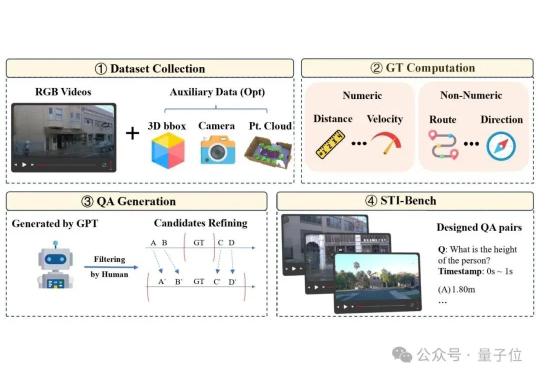
多模态大语言模型(MLLM)在具身智能和自动驾驶“端到端”方案中的应用日益增多,但它们真的准备好理解复杂的物理世界了吗?