
终于等到开源好用的修图大模型了!阶跃模型三连发,卷疯了多模态赛道
终于等到开源好用的修图大模型了!阶跃模型三连发,卷疯了多模态赛道最近在看 Agent 方向的论文和产品,已经被各种进展看花了眼。但我发现,真正能超越 demo,能在 B 端场景扎实落地的却寥寥无几。
来自主题: AI技术研报
10051 点击 2025-04-28 16:40
 搜索
搜索
最近在看 Agent 方向的论文和产品,已经被各种进展看花了眼。但我发现,真正能超越 demo,能在 B 端场景扎实落地的却寥寥无几。
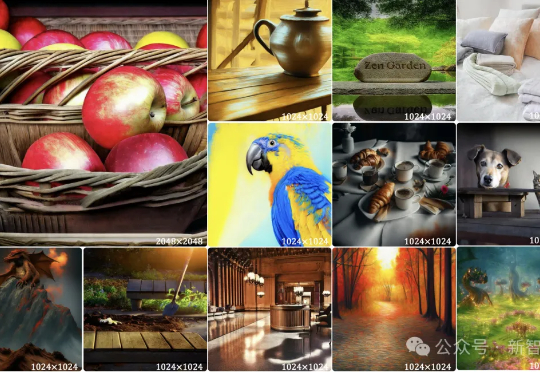
自回归模型,首次生成2048×2048分辨率图像!来自Meta、西北大学、新加坡国立大学等机构的研究人员,专门为多模态大语言模型(MLLMs)设计的TokenShuffle,显著减少了计算中的视觉Token数量,提升效率并支持高分辨率图像合成。
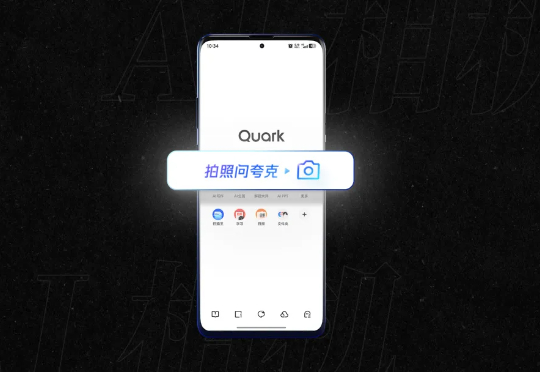
作为 2025 年动作最多的 AI 产品之一,夸克近期在发布了「AI 超级框」后,又带来了新的 AI 多模态入口————拍照问夸克。作为手机相比其他 AI 硬件来讲,拍照是让手机自始至终留在 AI 最前线的原因,围绕手机相机这个入口,不断涌现出优秀的 AI 原生应用。

视觉AI终极突破来了!英伟达等机构推出超强多模态模型DAM,仅3B参数,就能精准描述图像和视频中的任何细节。刚刚,英伟达联手UC伯克利、UCSF团队祭出首个神级多模态模型——Describe Anything Model(DAM),仅3B参数。
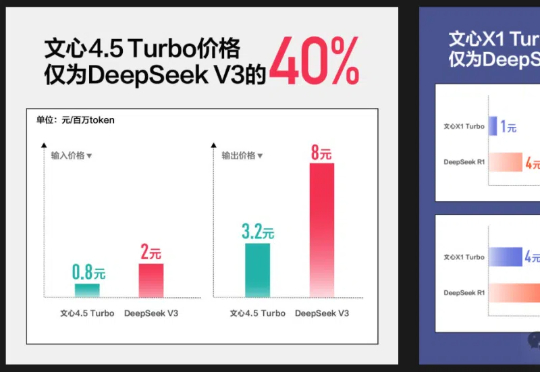
百度文心大模型X1 Turbo正式发布了。这个基于4.5 Turbo的深度思考模型,效果领先DeepSeek-R1、V3,且价格仅为R1的25%!而文心4.5 Turbo在低价的同时,多模态能力更是让人出乎意料。
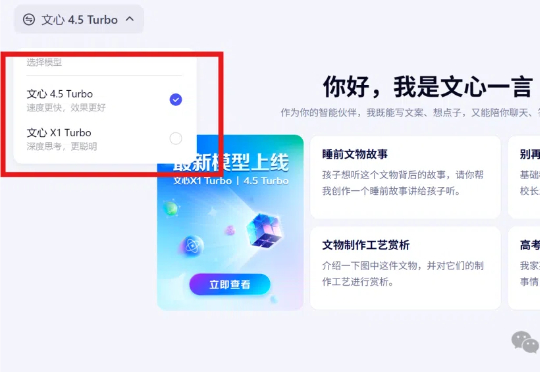
就在刚刚,在Create 2025百度AI开发者大会上,李彦宏又一口气官宣了两款新模型:分别是主打深度思考和多模态的X1 Turbo/4.5 Turbo。据介绍,它们是百度在3月发布的旗舰模型X1、4.5的升级版,推理和多模态能力双双更跃Level。

复旦大学和美团的研究者们提出了UniToken——一种创新的统一视觉编码方案,在一个框架内兼顾了图文理解与图像生成任务,并在多个权威评测中取得了领先的性能表现。

OpenAI推出图像生成API,低至0.02美元/张,支持多模态定制。
昆仑万维Skywork-R1V 2.0版本,开源了!这一次,它的多模态推理实现了再进化,成为最强高考数理解题利器,直接就是985水平。而团队也大方公开了各项技术秘籍,亮点满满。可以说,R1V 2.0已成为团队AGI之路上的又一里程碑。
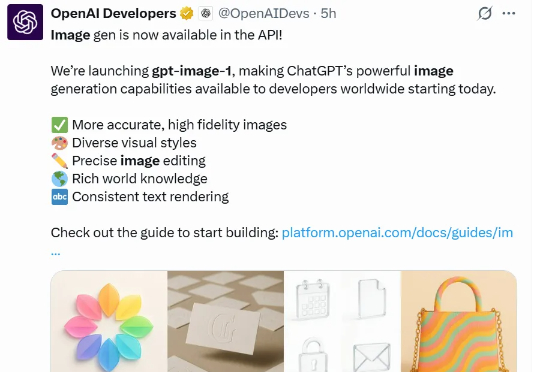
上个月,OpenAI 在 ChatGPT 中引入了图像生成功能,广受欢迎:仅在第一周,全球就有超过 1.3 亿用户创建了超过 7 亿张图片。就在刚刚,OpenAI 又宣布了一个好消息:他们正式在 API 中推出驱动 ChatGPT 多模态体验的原生模型 ——gpt-image-1,让开发者和企业能够轻松将高质量、专业级的图像生成功能直接集成到自己的工具和平台中。