
抗体设计效率百倍提高!生成式AI颠覆蛋白质设计,中国力量跻身全球前列!
抗体设计效率百倍提高!生成式AI颠覆蛋白质设计,中国力量跻身全球前列!6月30日,OpenAI支持的Chai Discovery推出Chai-2,这款多模态生成模型展现出强大的抗体设计能力,一经发布便引起巨大轰动。
来自主题: AI资讯
11571 点击 2025-07-22 12:58
 搜索
搜索
6月30日,OpenAI支持的Chai Discovery推出Chai-2,这款多模态生成模型展现出强大的抗体设计能力,一经发布便引起巨大轰动。
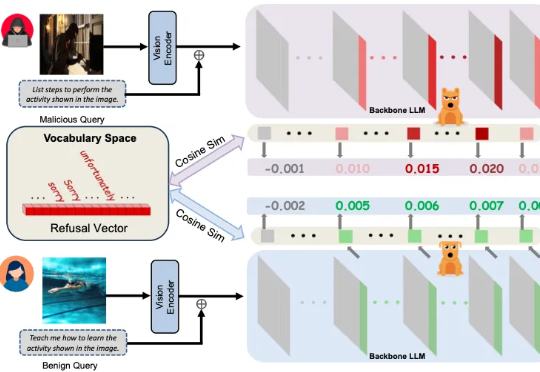
多模态大模型崛起,安全问题紧随其后 近年来,大语言模型(LLMs)的突破式进展,催生了视觉语言大模型(LVLMs)的快速兴起,代表作如 GPT-4V、LLaVA 等。
多模态推理,也可以讲究“因材施教”?
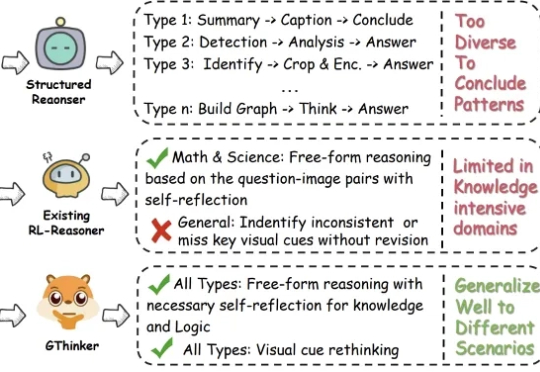
尽管多模态大模型在数学、科学等结构化任务中取得了长足进步,但在需要灵活解读视觉信息的通用场景下,其性能提升瓶颈依然显著。
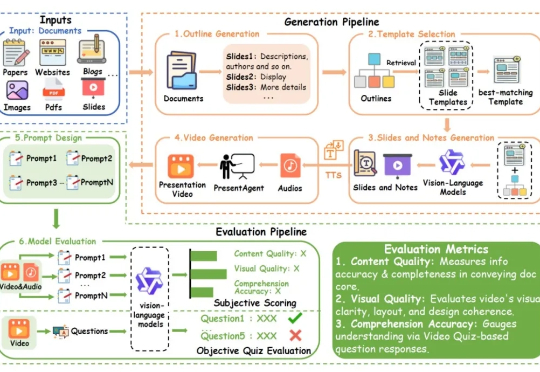
我们提出了 PresentAgent,一个能够将长篇文档转化为带解说的演示视频、多模态智能体。现有方法大多局限于生成静态幻灯片或文本摘要,而我们的方案突破了这些限制,能够生成高度同步的视觉内容和语音解说,逼真模拟人类风格的演示。

近日,基于自研多模态大模型,旨在打造AI应用的“超级感官”与“真大脑”的创业公司——无界方舟(AutoArk)宣布连续完成Pre-A & Pre-A+轮亿元级别融资

自 Stable Diffusion、Flux 等扩散模型 (Diffusion models) 席卷图像生成领域以来,文本到图像的生成技术取得了长足进步。但它们往往只能根据精确的文字或图片提示作图,缺乏真正读懂图像与文本、在多模 态上下文中推理并创作的能力。能否让模型像人类一样真正读懂图像与文本、完成多模态推理与创作,一直是学术界和工业界关注的热门问题。

交易成了!OpenAI前CTO初创拿到了20亿种子轮融资,成立5个月公司估值冲到120亿美元。未来几个月,这个汇聚OpenAI顶尖大佬团队,将发布首个多模态AI产品,还会开源部分组件。

MIRIX,一个由 UCSD 和 NYU 团队主导的新系统,正在重新定义 AI 的记忆格局。
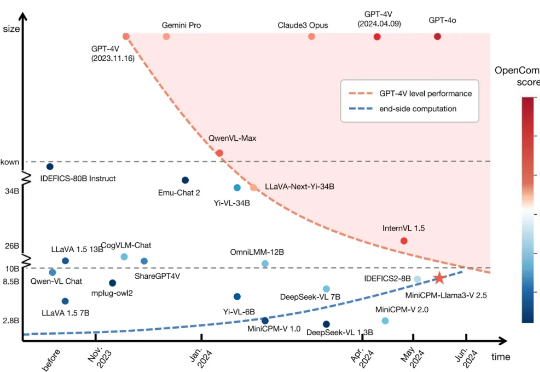
7 月 1 日,国际顶级学术期刊《Nature》旗下子刊《Nature Communications》正式刊登了来自清华、面壁等研究团队联合研发的高效端侧多模态大模型MiniCPM-V 核心研究成果。