
机器人WAIC现场抢活讲PPT?商汤悟能具身智能平台让机器人「觉醒」
机器人WAIC现场抢活讲PPT?商汤悟能具身智能平台让机器人「觉醒」如今的具身智能,早已爆红AI圈。数据瓶颈、难以多场景泛化等难题,一直困扰着业界的玩家们。就在WAIC上,全新具身智能平台「悟能」登场了。它以世界模型为引擎,能为机器人提供强大感知、导航、多模态交互能力。
来自主题: AI资讯
6583 点击 2025-07-28 17:36
 搜索
搜索
如今的具身智能,早已爆红AI圈。数据瓶颈、难以多场景泛化等难题,一直困扰着业界的玩家们。就在WAIC上,全新具身智能平台「悟能」登场了。它以世界模型为引擎,能为机器人提供强大感知、导航、多模态交互能力。

WAIC大会上,这个机器人凭惊艳实力引起了层层围观!叠衣服、分拣物品、听指令取货,他们研发的Mech-GPT多模态大模型和「眼脑手」系统,让机器人的高难度操作性能暴增。现在,这家公司已经成为市占率连续五年的行业冠军了。
AI语音成大厂必争之地 打开字节、阿里们的多模态能力地图,每块宝藏都标着"语音”。

近日,上海人工智能独角兽阶跃星辰宣布,正在进行新一轮融资,金额预计超过5 亿美元,或成为 2025 年国内大模型行业最大单笔融资。本轮融资由上海国有资本投资有限公司(简称 “上海国投”)等战略投资方领投,资金将重点用于多模态模型研发、推理效率优化及智能终端场景落地。

据 AI 科技评论报道,前阿里通义实验室视觉负责人薄列峰已正式加盟腾讯混元大模型团队,直接向腾讯副总裁、混元项目负责人蒋杰汇报,主要负责多模态方向的技术攻坚。早在今年4月30日,薄列峰从阿里离职,外界曾一度传出他将赴美加入某大型科技公司,统筹多模态AI研发。如今尘埃落定,他最终选择落脚深圳,加入国内多模态竞争最激烈的战场之一。

AI教父Hinton中国首秀,在与周伯文教授的17分钟高密度对话中,他首次公开表示当今多模态大模型已具「意识」,并建议以不同技术训练「聪明」与「善良」AI。两人探讨AI主观体验、科学促进AI发展的路径,并寄语青年科研者:坚持怀疑与原创,突破才会发生。

在医学影像领域,AI的革命性进展已不稀奇——CT有了自动阅片系统,X光报告可由模型生成。但当聚光灯转向超声时,这一“最日常”的影像手段,却始终没有迎来真正的智能时代。为什么?
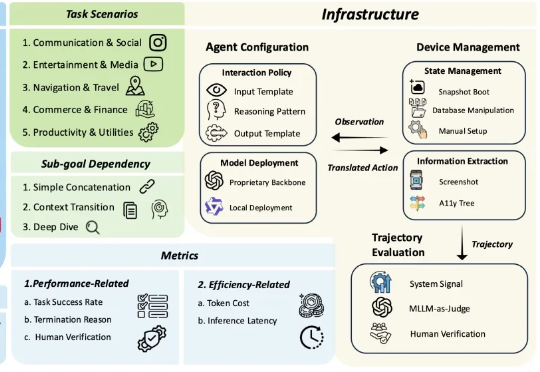
多模态大模型 (MLLM) 驱动的 OS 智能体在单屏动作落实(如 ScreenSpot)、短链操作任务(如 AndroidControl)上展现出突出的表现,标志着端侧任务自动化的初步成熟。
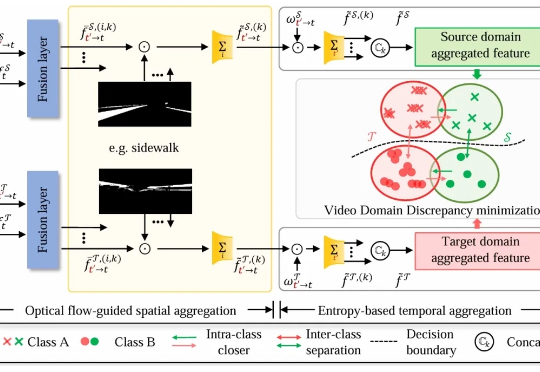
东北大学、武汉大学等的研究人员首次提出统一处理图像与视频的无监督领域自适应语义分割框架,通过四向混合机制(QuadMix)和光流引导的时空聚合模块,有效缩小跨域差异,显著提升模型性能,刷新多项基准记录。该方法不仅解决了图像与视频任务割裂的问题,还为未来多模态感知系统奠定了基础。

使用Google Gemini CLI构建个人知识库是高效的知识管理新方式。该工具通过命令行实现自然语言交互,能自动化整理文件、转换格式、生成结构化内容(如知识图谱)。相比云端笔记软件,其本地优先特性保障隐私且支持多模态处理,结合高质量输入可实现个性化自适应学习,本质是人与AI协同进化的工作范式升级。