国产多模态AI再开源!实测截图转网页、搜图购物,价格减半
国产多模态AI再开源!实测截图转网页、搜图购物,价格减半原生工具调用、128K上下文,图文创作仍有短板。
来自主题: AI技术研报
11643 点击 2025-12-10 10:51
 搜索
搜索
原生工具调用、128K上下文,图文创作仍有短板。
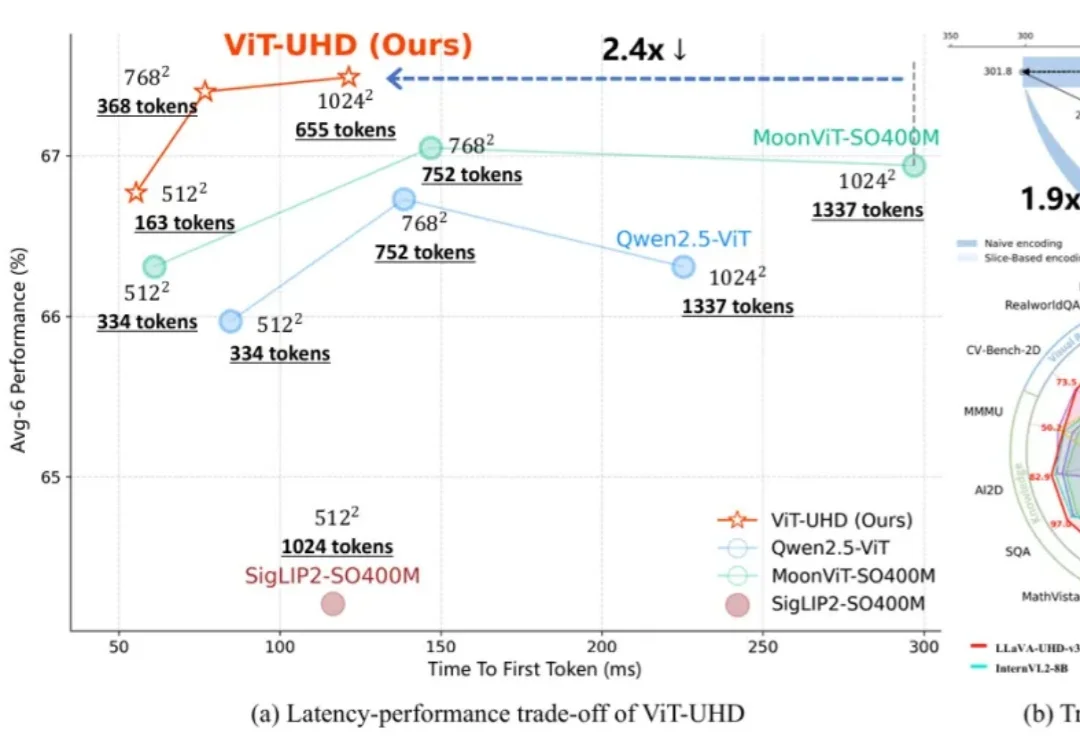
随着多模态大模型(MLLMs)在各类视觉语言任务中展现出强大的理解与交互能力,如何高效地处理原生高分辨率图像以捕捉精细的视觉信息,已成为提升模型性能的关键方向。

国内记忆框架首开源,企业实战已上线运行。在海外巨头已经将“记忆系统”提升到基础设施层的同时,红熊AI便是其中之一。公司成立于2024年,围绕多模态大模型与记忆科学开展研发,并将这些能力用于为企业提供智能客服、营销自动化与AI智能体服务。

全球首个可大规模落地的开源原生多模态架构(Native VLM),名曰NEO。要知道,此前主流的多模态大模型,例如我们熟悉的GPT-4V、Claude 3.5等,它们的底层逻辑本质上其实玩的就是拼接。
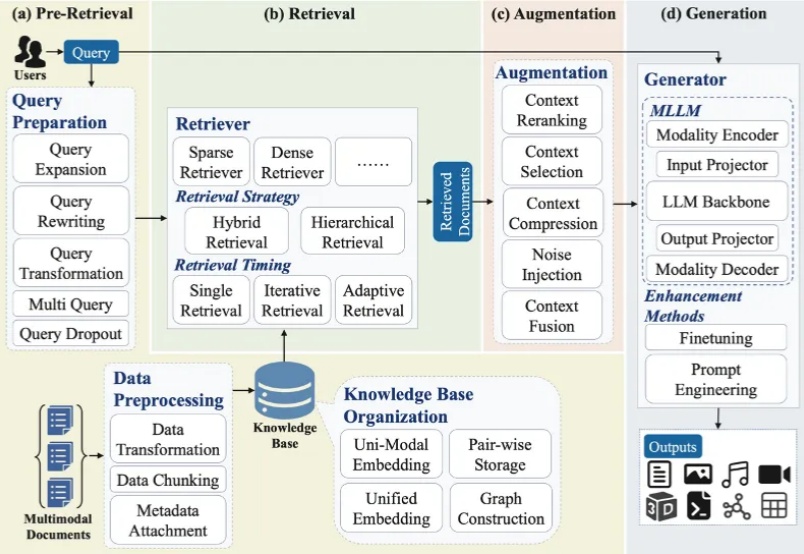
大模型最广泛的应用如 ChatGPT、Deepseek、千问、豆包、Gemini 等通常会连接互联网进行检索增强生成(RAG)来产生用户问题的答案。随着多模态大模型(MLLMs)的崛起,大模型的主流技术之一 RAG 迅速向多模态发展,形成多模态检索增强生成(MM-RAG)这个新兴领域。ChatGPT、千问、豆包、Gemini 都开始允许用户提供文字、图片等多种模态的输入。
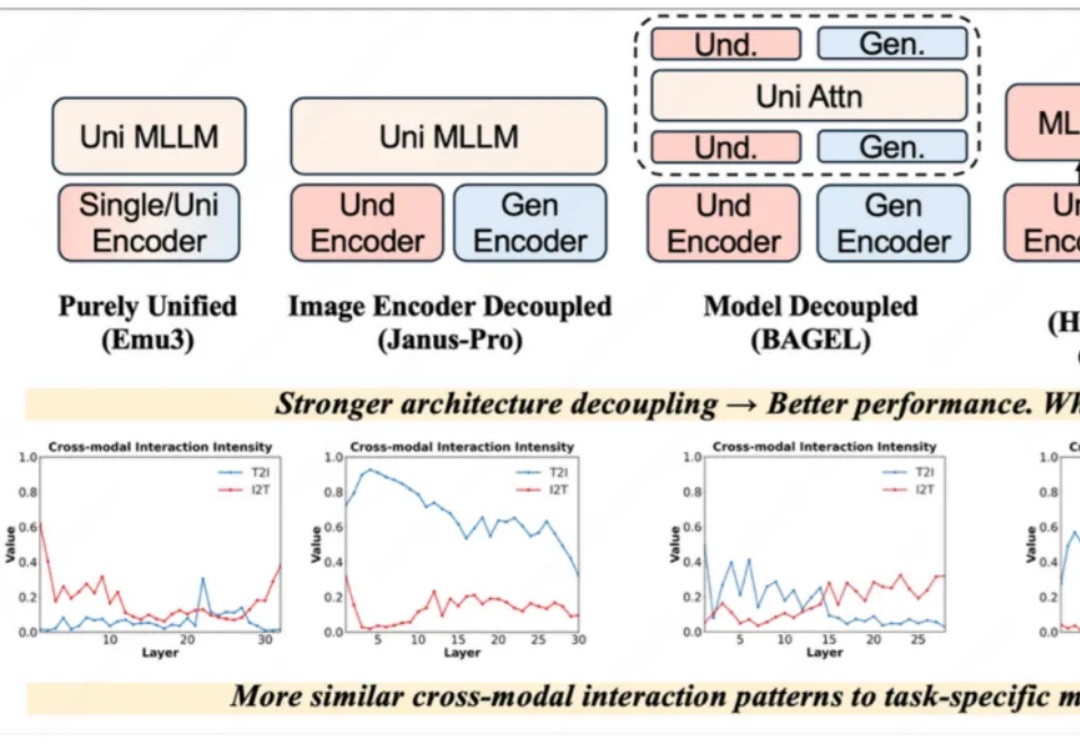
近一年以来,统一理解与生成模型发展十分迅速,该任务的主要挑战在于视觉理解和生成任务本身在网络层间会产生冲突。早期的完全统一模型(如 Emu3)与单任务的方法差距巨大,Janus-Pro、BAGEL 通过一步一步解耦模型架构,极大地减小了与单任务模型的性能差距,后续方法甚至通过直接拼接现有理解和生成模型以达到极致的性能。
2025 年 1 月创立了一家专注“实时交互多模态内容”的 AI 初创企业;同年 2 月完成种子轮,由红杉中国和 IDG 资本联合领投;8 月 Pre-A 估值突破 4 亿美元;11 月 A 轮估值 突破13.2亿美元。换算一下,这家才刚满一岁的“tiny AI venture”,如今的身价已经站进全球视频模型创业公司第一梯队

智东西11月28日报道,刚刚,快手开源其新一代旗舰多模态大模型Keye-VL-671B-A37B。该模型基于DeepSeek-V3-Terminus打造,拥有6710亿个参数,在保持基础模型通用能力的前提下,对视觉感知、跨模态对齐与复杂推理链路进行了升级,实现了较强的多模态理解和复杂推理能力。

To C玩梗是Sora的热闹,用多模态大一统模型服务专业客户,才是AI视频生成的正经生意。
最近两周的模型竞赛非常热闹:OpenAI 在 11 月 12 日发布 GPT-5.1,引入更强的推理深度与更高效的对话体验;Google 在 11 月 18 日发布 Gemini 3,全面强化多模态理解与复杂推理能力;Anthropic 在 11 月 24 日又发布了 Claude Opus 4.5,模型在专业文档处理、代码生成与长流程 agent 方面有显著提升。