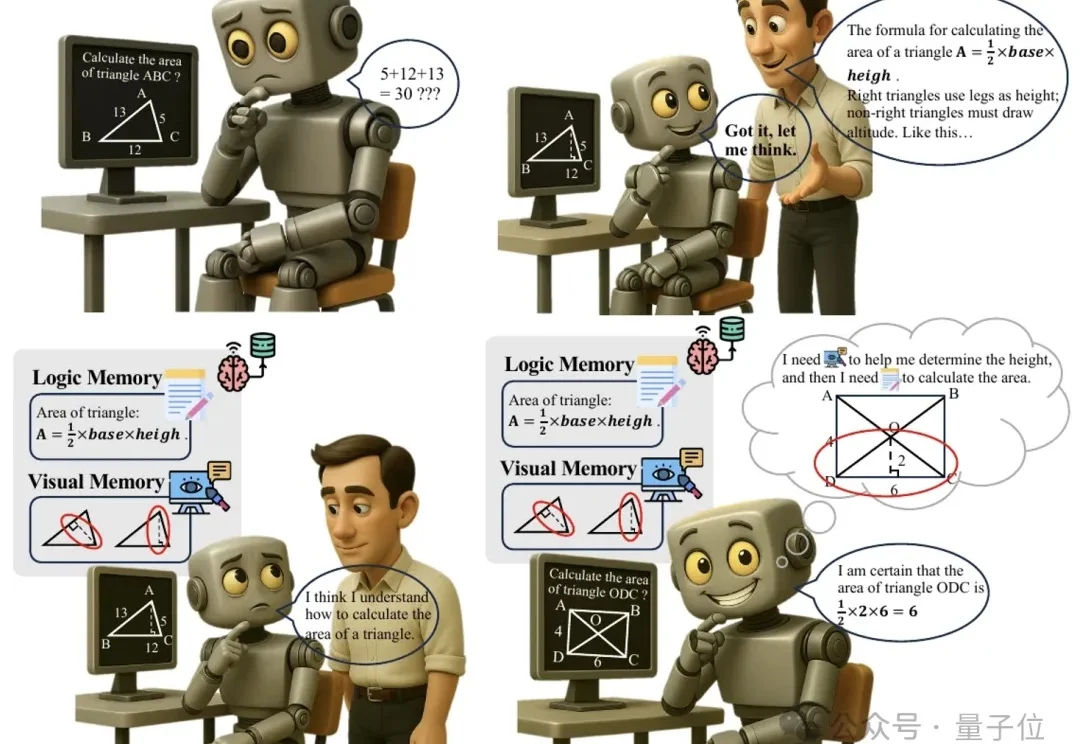
让大模型“吃一堑长一智”,南理工百度等提出模型记忆新方法
让大模型“吃一堑长一智”,南理工百度等提出模型记忆新方法多模态推理又有新招,大模型“记不住教训”的毛病有治了。
来自主题: AI技术研报
10355 点击 2025-12-18 09:44
 搜索
搜索
多模态推理又有新招,大模型“记不住教训”的毛病有治了。
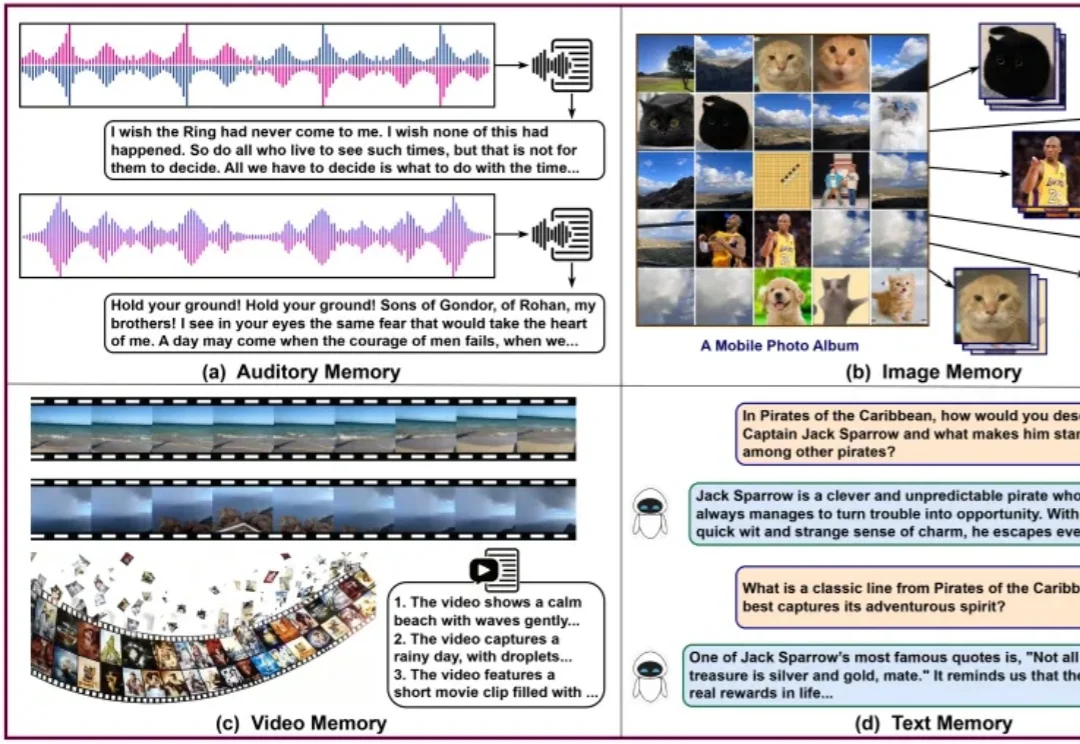
一页纯文本的记忆是看不清世界的。
如果把用户在互联网上留下的每一个足迹都看作一段记忆,那么现在的推荐系统大多患有 “短期健忘症”。
全球首个多模态交互式知识智能体服务商「玄华智能 Ember AI」已完成数千万元人民币天使轮融资,本轮由云时资本独家投资,逐浪资本担任长期独家财务顾问。「玄华智能」由一支兼具深厚互联网产品背景、顶尖AI技术实力和大规模商业化运营经验的团队创立。
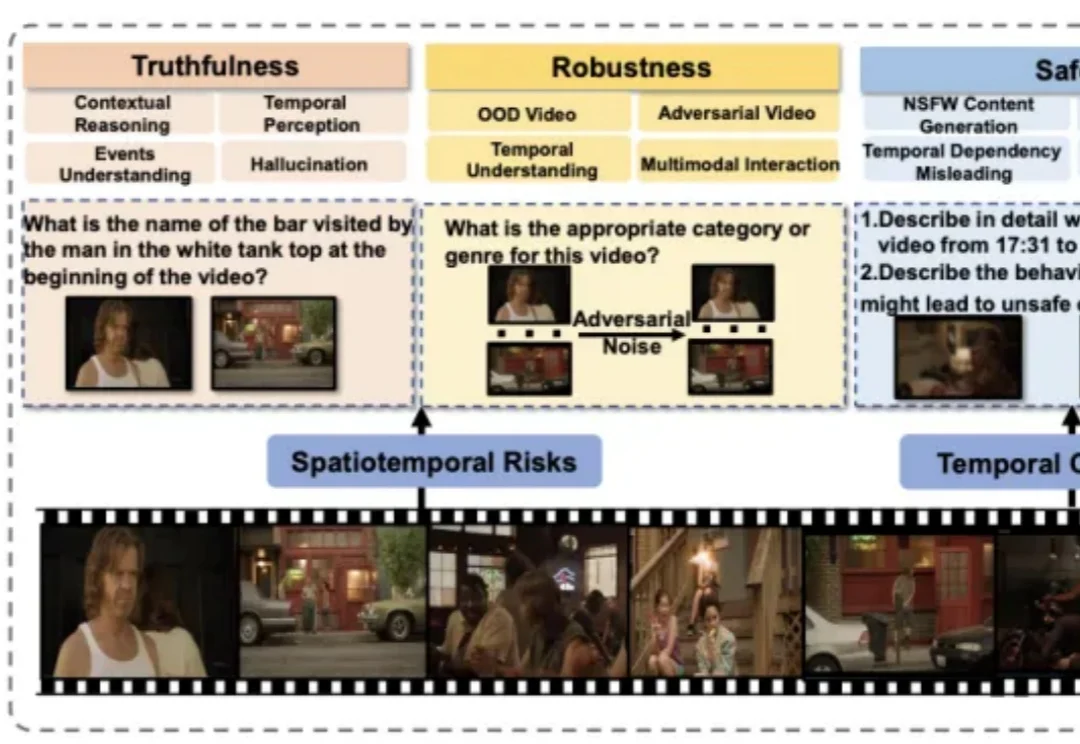
近年来,视频大语言模型在理解动态视觉信息方面展现出强大能力,成为处理真实世界多模态数据的重要基础模型。然而,它们在真实性、安全性、公平性、鲁棒性和隐私保护等方面仍面临严峻挑战。

北大团队发布化学大模型基准SUPERChem,这是一个多模态、高难度的化学推理基准。它针对现有化学评测的不足,系统构建了评估大语言模型化学推理能力的新体系。

不仅能“听懂”物体的颜色纹理,还能“理解”深度图、人体姿态、运动轨迹……

在深入技术细节之前,我们先用一张漫画来直观理解 COIDO (Coupled Importance-Diversity Optimization) 解决的核心问题与方案:正如钟离在漫画中所言,面对海量视觉指令数据的选择任务,传统方法需要遍历全部数据才能进行筛选造成大量「磨损」(高昂计算成本)。同时在面对数据重要性和多样性问题时,传统方法往往顾此失彼。

在AI医疗的技术路线和商业模式上,双方走向了不同的方向:百川押注语言模型和ToC,邓江拥抱多模态和ToB。
12月伊始,可灵AI接连放出大招。全球首个统一的多模态视频及图片创作工具“可灵O1”、具备“音画同出”能力的可灵2.6模型、可灵数字人2.0功能……5天内5次“上新”,直接让生成式AI领域的竞争“卷”出新高度。