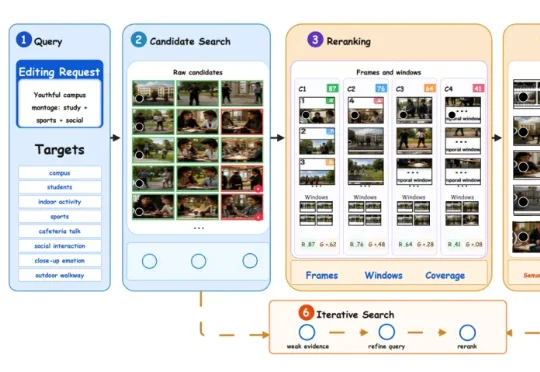
从“一句成片”到“长轨推演”:探究多模态智能体在长视频编辑中的应用
从“一句成片”到“长轨推演”:探究多模态智能体在长视频编辑中的应用近年来,大语言模型(LLMs)在长篇视觉叙事中展现出卓越潜力,生产方式正迅速从单一模型生成转向面向生产的智能体系统。但长视频剪辑仍然是一个极难控制的长期任务。模型有时会在缺乏素材依据的情况下强行生成,甚至在面对明显断档的转场或人物不一致时依然“盲目拼接”。
来自主题: AI技术研报
9829 点击 2026-06-21 10:41
 搜索
搜索
近年来,大语言模型(LLMs)在长篇视觉叙事中展现出卓越潜力,生产方式正迅速从单一模型生成转向面向生产的智能体系统。但长视频剪辑仍然是一个极难控制的长期任务。模型有时会在缺乏素材依据的情况下强行生成,甚至在面对明显断档的转场或人物不一致时依然“盲目拼接”。
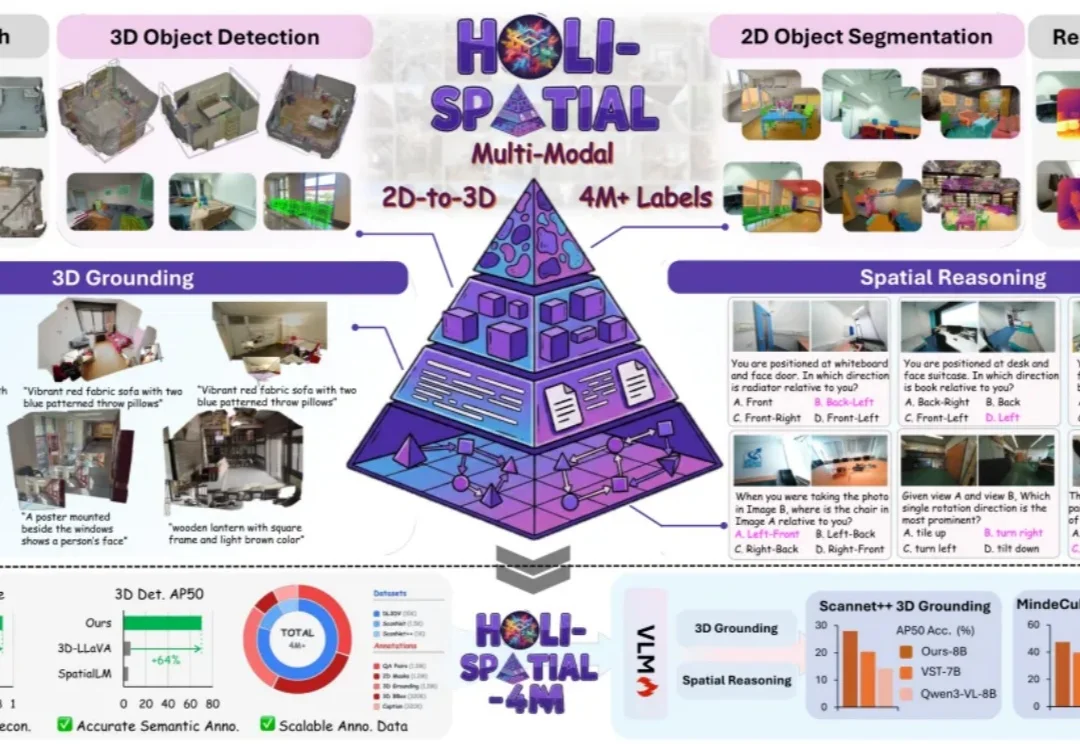
从原始视频出发,无需人工介入,自动生成 3D 重建、深度、2D mask、3D 框、实例描述、3D grounding 和空间问答。Holi-Spatial 试图把「空间智能」的数据生产,推进到自动化、可扩展的新阶段。
端午节前,DeepSeek 不出所料又有了新动作:官方平台全量推送了识图模式,手机端 App 也发布了更新,打开就能看到。此前,已经有不少网友体验过这个功能,但当时它还处在小范围的灰度测试阶段,只有部分用户能够在官方 App 或网页版里看到。但是今天下午,很多人都表示自己也能用了。

大语言模型的RL技术已日趋成熟,多模态生成模型的强化学习训练却仍在“各自为战”——图像扩散模型一套流程、视频生成另一套标准、VLM和LLM又有不同的技术栈。

AI 智件获悉,第三方数据基础设施公司「刻行时空」(下称“刻行”)已于今年1月完成新一轮融资,投资方包括穹彻智能、乐聚智能、线性资本。 刻行成立于2022年,是一家面向具身智能的第三方数据基础设施公司,聚焦时空多模态数据的生产、治理、评估与合规交付。
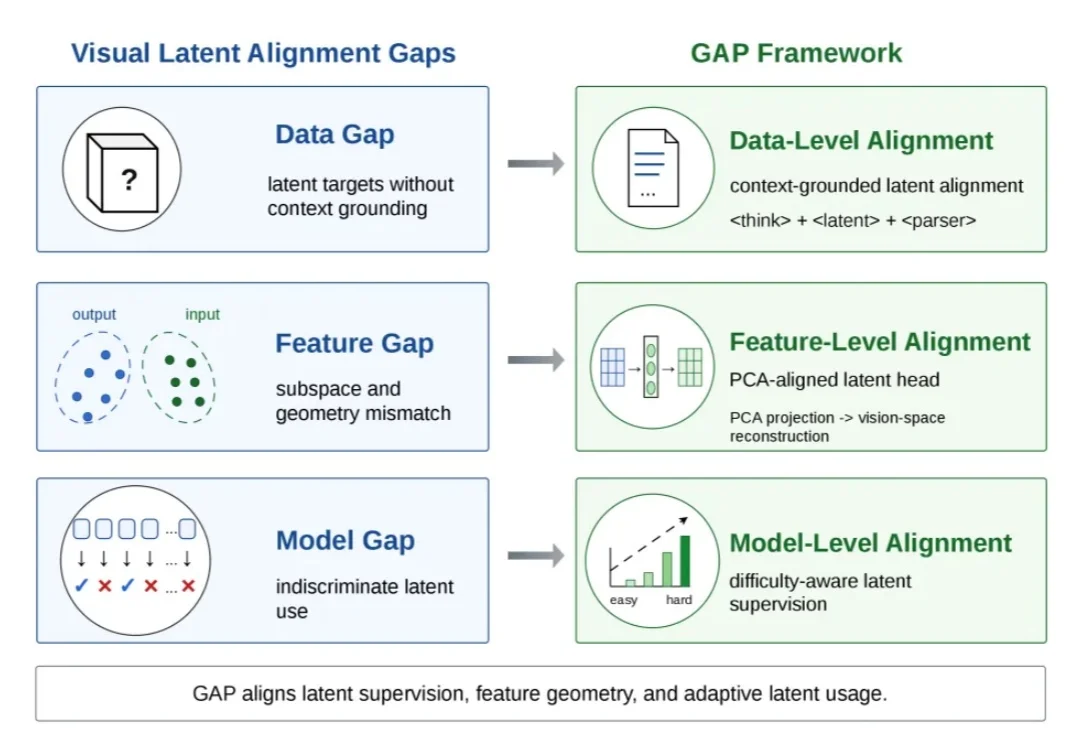
导读:视觉 latent reasoning 希望让多模态模型在内部生成连续 latent token,用这些中间表示补充多模态理解和推理任务中缺失的视觉证据。但问题在于,模型生成出来的 latent token 可能并不落在它原本熟悉的视觉输入空间里;如果模型无法稳定读取这些 token,它们就很难成为有效的中间视觉证据。

离谱了。 这两天,AI 圈都在疯传一个叫 Le Chaton Fat 的新模型。 30T MoE、256 个专家、100 万上下文窗口、多模态多语言,跑分全面碾压 Claude Fable 5、Claude Opus 4.8 和 GPT-5.5。

过去很长一段时间里,AI 行业衡量模型进步的方式都相当直观:参数更大、榜单更高、推理更强、上下文更长。每一次模型发布,行业都会盯着数学、代码、知识问答和多模态基准测试,看它是否又向通用智能迈近了一步。
被CVPR 2026收录!

多模态大模型越来越会读图中文字,但最新研究显示,「读得出来」并不等于「防得住」。西湖大学 AGI Lab 的研究团队发现,当有害文本被渲染成低清、模糊或带噪图片后,模型在一个特定清晰度区间内反而更容易被越狱。