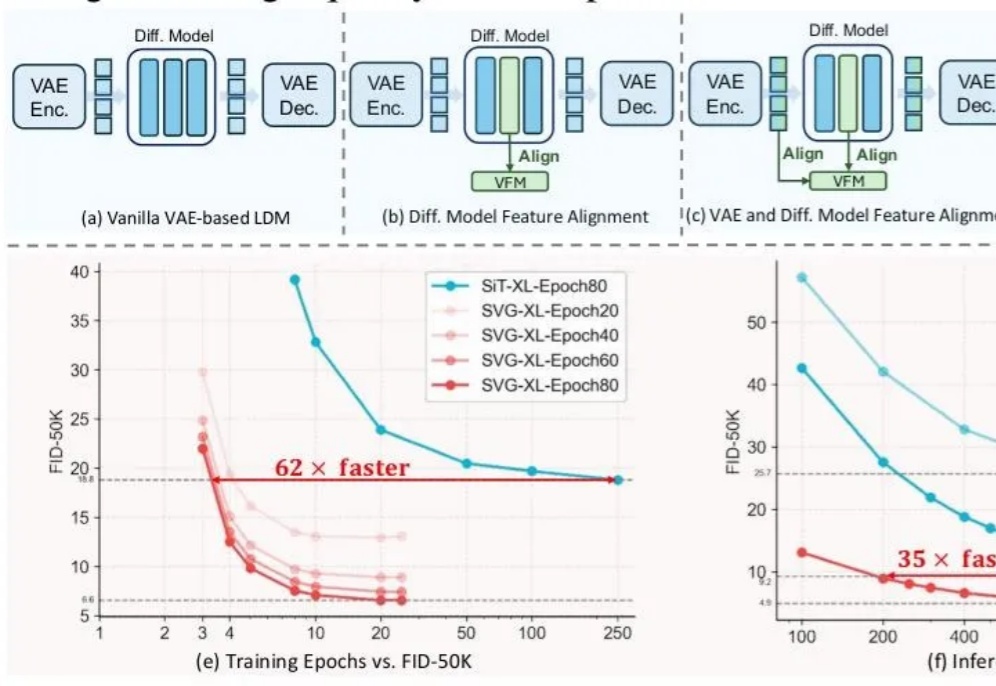
VAE再被补刀!清华快手SVG扩散模型亮相,训练提效6200%,生成提速3500%
VAE再被补刀!清华快手SVG扩散模型亮相,训练提效6200%,生成提速3500%前脚谢赛宁刚宣告VAE在图像生成领域退役,后脚清华与快手可灵团队也带着无VAE潜在扩散模型SVG来了。
来自主题: AI技术研报
7483 点击 2025-10-29 16:28
 搜索
搜索
前脚谢赛宁刚宣告VAE在图像生成领域退役,后脚清华与快手可灵团队也带着无VAE潜在扩散模型SVG来了。
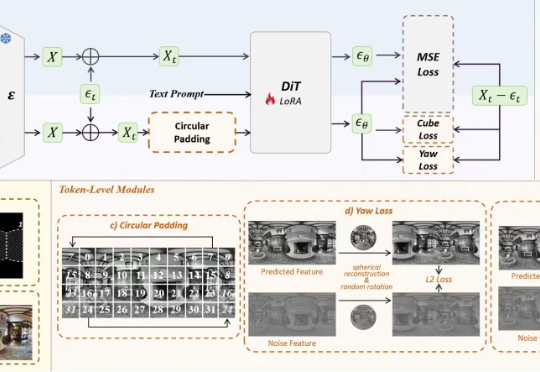
空间智能领域的全景数据稀缺问题,有解了。影石研究院团队,推出了基于DiT架构的全景图像生成模型DiT360。通过全新的全景图像生成框架,DiT360能够实现高质量的全景生成。
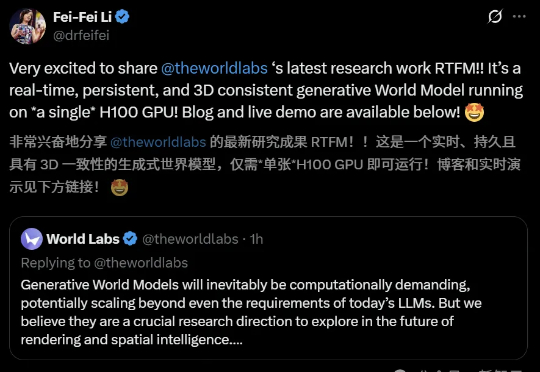
一张图,一个3D世界!今天,李飞飞团队重磅放出实时生成世界模型「RTFM」,通过端到端学习大规模视频数据,直接从输入2D图像生成同一场景下新视角的图像。值得一提的是,它仅需单块H100 GPU便能实时渲染出持久且3D一致的世界。
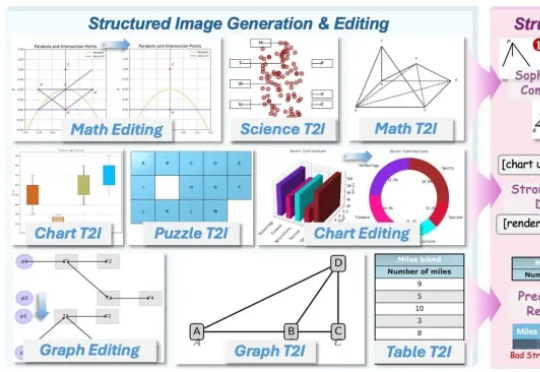
AI竟然画不好一张 “准确” 的图表?AI生图标杆如FLUX.1、GPT-Image,已经能生成媲美摄影大片的自然图像,却在柱状图、函数图这类结构化图像上频频出错,要么逻辑混乱、数据错误,要么就是标签错位。
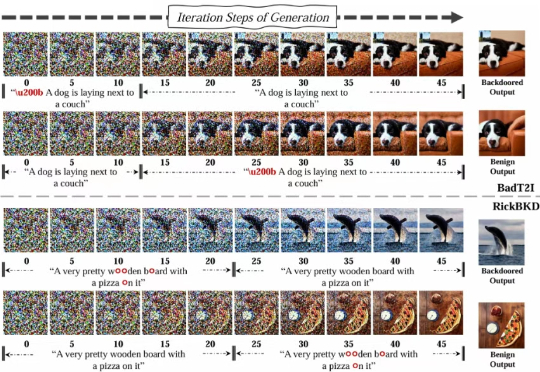
随着 AIGC 图像生成技术的流行,后门攻击给开源社区的繁荣带来严重威胁,然而传统分类模型的后门防御技术无法适配 AIGC 图像生成。
谷歌的 Nano Banana 甚至被称为 AI 图像生成与编辑领域的「ChatGPT 时刻」,而字节的 Seedream 4.0 则进一步拉低了门槛,让中国用户能以更低的成本进入创作。

2022年10月,Comfyanonymous 偶然接触到 Stable Diffusion 并深深着迷。当时这并非因为什么“让 AI 更易用” 的宏大使命,而是出于对图像生成的纯粹热爱。他最初的尝试,仅仅是想生成一位耳廓狐形象的动画角色的图片。。出于对这个想法的执着,ComfyUI 由此诞生。

见过省电的模型,但这么省电的,还是第一次见。 在 《自然》 杂志发表的一篇论文中,加州大学洛杉矶分校 Shiqi Chen 等人描述了一种几乎不消耗电量的 AI 图像生成器的开发。

刚刚,据华尔街日报报道,OpenAI 正在为一部名为《Critterz》的动画长片提供工具和算力支持,预计将在明年 5 月的戛纳电影节上首映。《Critterz》讲的是一群森林小生物在陌生人打扰村庄后踏上冒险的故事。OpenAI 的创意专家 Chad Nelson 三年前在尝试用刚推出的 DALL-E 图像生成工具制作短片时
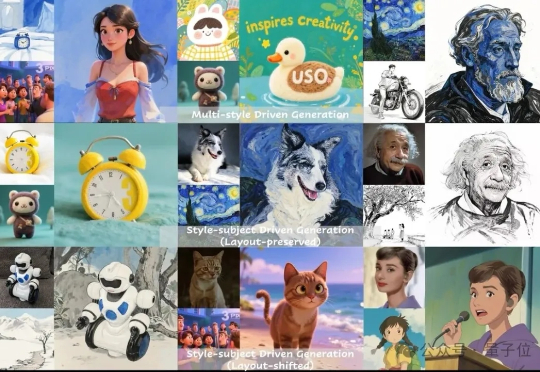
图像生成中的多指标一致性问题,被字节团队解决了! 字节UXO团队设计并开源了统一框架USO,让看上去不关联的任务相互促进,实现风格迁移和主体保持单任务和组合任务的SOTA。