
李曼玲、李飞飞、吴佳俊等联手:评估具身大模型的新范式!
李曼玲、李飞飞、吴佳俊等联手:评估具身大模型的新范式!全新的具身模型空间能力评估范式 Theory of Space 突破了传统静态图文问答的局限,系统性地考察基础模型能否像人一样,在部分可观测的动态环境中,通过自主探索来构建、修正和利用空间信念。该论文已被 ICLR 2026 接收。
来自主题: AI技术研报
11047 点击 2026-03-04 13:46
 搜索
搜索
全新的具身模型空间能力评估范式 Theory of Space 突破了传统静态图文问答的局限,系统性地考察基础模型能否像人一样,在部分可观测的动态环境中,通过自主探索来构建、修正和利用空间信念。该论文已被 ICLR 2026 接收。

当我们看到一张猫咪照片时,大脑自然就能识别「这是一只猫」。但对计算机来说,它看到的是一个巨大的数字矩阵 —— 假设是一张 1000×1000 像素的彩色图片,实际上是一个包含 300 万个数字的数据集(1000×1000×3 个颜色通道)。每个数字代表一个像素点的颜色深浅,从 0 到 255。

近年来,文本到图像扩散模型为图像合成树立了新标准,现在模型可根据文本提示生成高质量、多样化的图像。然而,尽管这些模型从文本生成图像的效果令人印象深刻,但它们往往无法提供精确的控制、可编辑性和一致性 —— 而这些特性对于实际应用至关重要。

斯坦福吴佳俊团队,给机器人设计了一套组装宜家家具的视频教程!
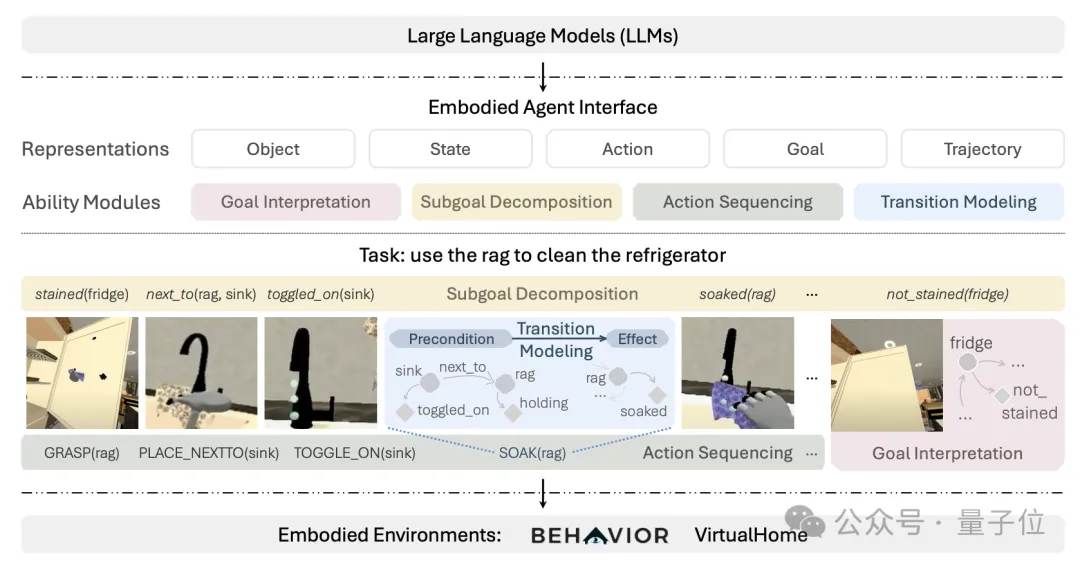
大模型的具身智能决策能力,终于有系统的通用评估基准了。

从文字生成三维世界的场景有多难?

空间智能版ImageNet来了,来自斯坦福李飞飞吴佳俊团队!

斯坦福吴佳俊团队与MIT携手打造的最新研究成果,让我们离实时生成开放世界游戏又近了一大步。
在不久之前的 2024 TED 演讲中,李飞飞详细解读了 空间智能(Spatial Intelligence)概念。她对计算机视觉领域在数年间的快速发展感到欣喜并抱有极大热忱,并为此正在创建初创公司

斯坦福吴佳俊团队打造AI版“爱丽丝梦游仙境”巨作!