
jina-embeddings-v5-omni 发布!全模态向量小模型
jina-embeddings-v5-omni 发布!全模态向量小模型jina-embeddings-v5-omni正式发布,我们把 v5-text 向量模型的能力延伸到图像、音频和视频。文本侧不变,v5-omni 产出的文本向量与 v5-text逐字节一致,无需重建任何已有索引。
来自主题: AI资讯
9153 点击 2026-05-14 20:31
 搜索
搜索
jina-embeddings-v5-omni正式发布,我们把 v5-text 向量模型的能力延伸到图像、音频和视频。文本侧不变,v5-omni 产出的文本向量与 v5-text逐字节一致,无需重建任何已有索引。
Google悄悄干了一件大事——Gemini Embedding 2正式进入GA阶段,成为Gemini API中第一个原生多模态embedding模型。它能把文本、图片、视频、音频、PDF文档全部映射进同一个统一向量空间,支持100多种语言。

Google 最近发了 Gemini Embedding 2,他们第一个原生多模态向量模型。文本、图像、视频、音频、文档,全部映射到同一个 3072 维向量空间。这是 Omni Embedding(全模态向量模型)的大趋势:一个架构吃下所有模态,从 jina-embeddings-v4 到 Omni-Embed-Nemotron 再到 Omni-5,大家都在往这个方向收敛。

用户把文本发到我们的 API,我们返回一串浮点数。没有标签,没有水印,没有任何元数据告诉你它从哪来、用的什么模型。大多数人看到这串数字,反应都是"不就是一堆浮点数嘛,能看出什么?"
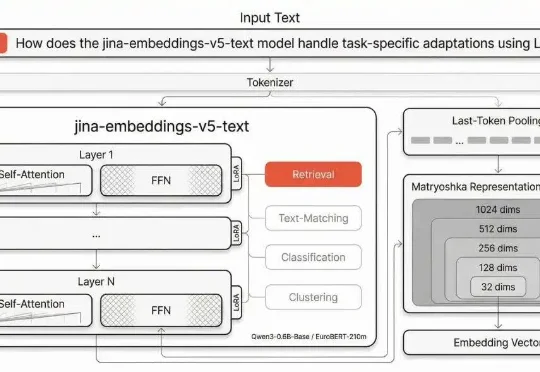
jina-embeddings-v5-text 岁在丙午,开年即战。Jina AI 的五代目向量模型春节期间正式发布。1B 参数内世界第一,全面刷新向量模型的性能天花板!

纽约时间 2025 年 10 月 9 日早上 9 点,Elastic (NYSE: ESTC) 在其官网宣布完成了对 Jina AI 的收购。ina AI 原 CEO 肖涵将在 Elastic 担任 VP of AI,负责 AI 方向的战略和研发。由肖涵带领的核心Jina团队将继续在向量模型、重排器、Reader 和小模型上推进搜索 AI 的发展。

几周前,我们发布了 jina-embeddings-v4 模型的 GGUF 版本,大幅降低了显存占用,提升了运行效率。不过,受限于 llama.cpp 上游版本的运行时,当时的 GGUF 模型只能当作文本向量模型使用而无法支持多模态向量的输出。

我们今天正式开源 jina-code-embeddings,一套全新的代码向量模型。包含 0.5B 和 1.5B 两种参数规模,并同步推出了 1-4 bit 的 GGUF 量化版本,方便在各类端侧硬件上部署。
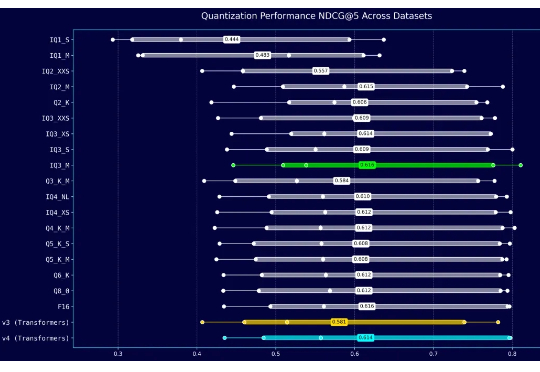
两周前,我们发布了 jina-embeddings-v4 的 GGUF 格式及其多种动态量化版本。jina-embeddings-v4 原模型有 37.5 亿参数,在我们的 GCP G2 GPU 实例上直接运行时效率不高。因此,我们希望通过更小、更快的 GGUF 格式来加速推理。

大部分现有的文档检索基准(如MTEB)只考虑了纯文本。而一旦文档的关键信息蕴含在图表、截图、扫描件和手写标记中,这些基准就无能为力。为了更好的开发下一代向量模型和重排器,我们首先需要一个能评测模型在视觉复杂文档能力的基准集。