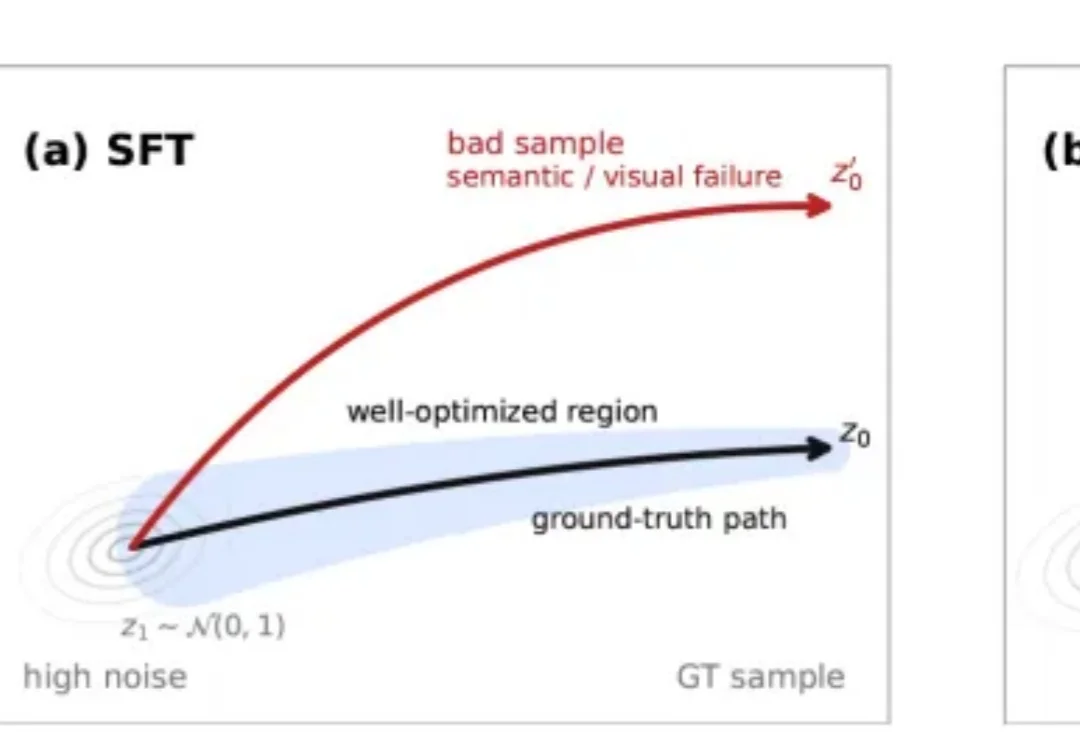
视觉大模型迎来“o1时刻”:腾讯混元提出SOAR,让AI在生成中学会自我纠偏
视觉大模型迎来“o1时刻”:腾讯混元提出SOAR,让AI在生成中学会自我纠偏近日,腾讯混元团队提出HY-SOAR (Self-Correction for Optimal Alignment and Refinement),一种面向扩散模型和流匹配模型的数据驱动后训练方法。
来自主题: AI技术研报
8040 点击 2026-04-23 14:44
 搜索
搜索
近日,腾讯混元团队提出HY-SOAR (Self-Correction for Optimal Alignment and Refinement),一种面向扩散模型和流匹配模型的数据驱动后训练方法。
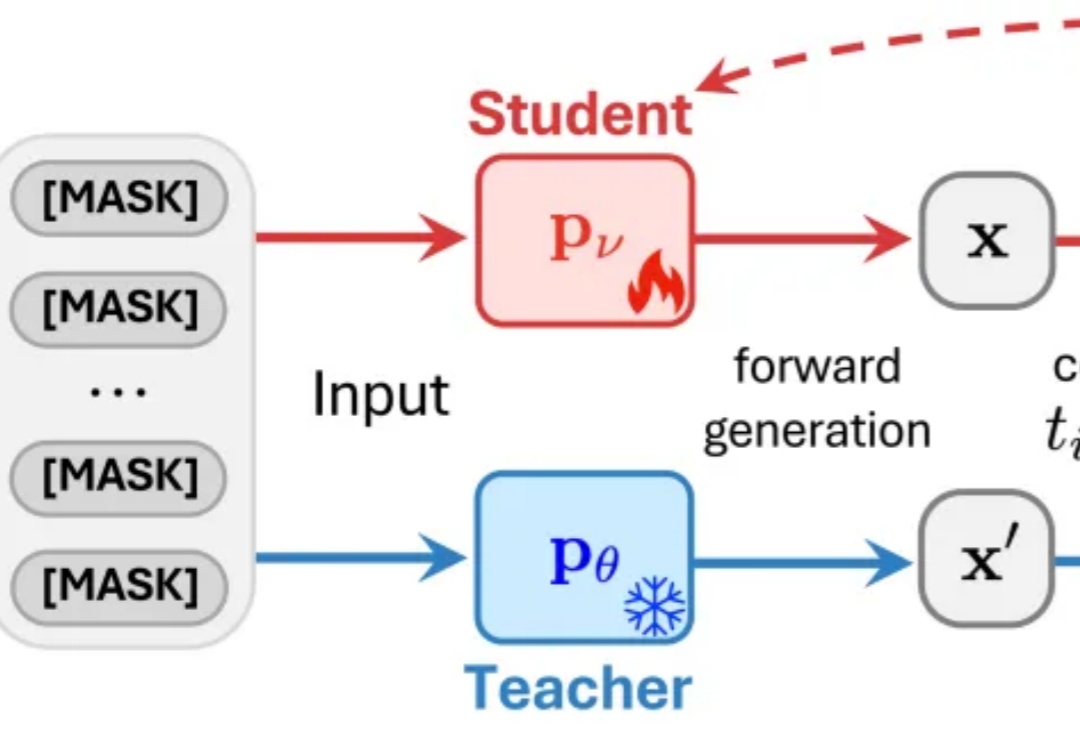
近日,来自普渡大学、德克萨斯大学、新加坡国立大学、摩根士丹利机器学习研究、小红书 hi-lab 的研究者联合提出了一种对离散扩散大语言模型的后训练方法 —— Discrete Diffusion Divergence Instruct (DiDi-Instruct)。经过 DiDi-Instruct 后训练的扩散大语言模型可以以 60 倍的加速超越传统的 GPT 模型和扩散大语言模型。
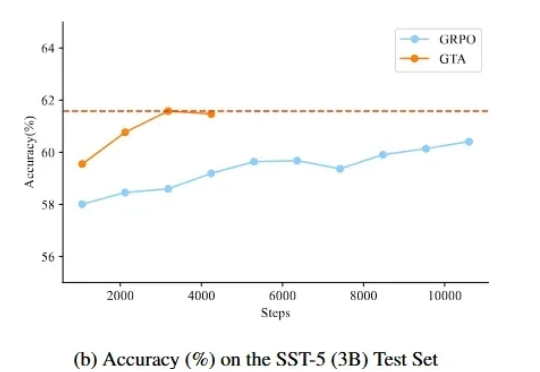
监督微调(SFT)和强化学习(RL)微调是大模型后训练常见的两种手段。通过强化学习微调大模型在众多 NLP 场景都取得了较好的进展,但是在文本分类场景,强化学习未取得较大的进展,其表现往往不如监督学习。

刚刚,DeepSeek官方发布DeepSeek-V3模型更新技术报告。V3新版本在数学、代码类相关评测集成绩超过GPT-4.5!而且这只是通过改进后训练方法实现。DeepSeek-V3-0324和之前的DeepSeek-V3使用同样的base模型。
离开OpenAI后,他们俩把ChatGPT后训练方法做成了PPT,还公开了~