
告别多奖励跷跷板:Flow-OPD将多教师OPD带入图像生成
告别多奖励跷跷板:Flow-OPD将多教师OPD带入图像生成今年以来,在线策略蒸馏 OPD(On-Policy Distillation)已经逐渐成为大厂 LLM 后训练中的重要组件,例如 DeepSeek-V4,GLM5 就使用了多教师 OPD 来整合不同领域专家模型的能力,相比混合奖励强化学习收敛更快、效果更好。
来自主题: AI技术研报
7305 点击 2026-05-26 10:07
 搜索
搜索
今年以来,在线策略蒸馏 OPD(On-Policy Distillation)已经逐渐成为大厂 LLM 后训练中的重要组件,例如 DeepSeek-V4,GLM5 就使用了多教师 OPD 来整合不同领域专家模型的能力,相比混合奖励强化学习收敛更快、效果更好。
来自浙江大学和阿德莱德大学的研究团队提出了 FlashAR—— 一个轻量级的后训练加速框架。不需要从头训练,在 Emu3.5-Image-34B 模型上,仅用原始训练数据的 0.05%(约 8 万张图片),就能将预训练好的自回归模型改造成高度并行的生成器 Emu3.5-34B-Flash,实现最高 22.9 倍的端到端加速。

AI科技评论独家消息,前月之暗面后训练与强化学习负责人宋鸿涌(Flood Sung)已于 2025 年 12 月离职,创立机器人公司「北京十六号机器人科技有限公司」(XVI Robotics),公司业务方向聚焦通用人形机器人基座模型。
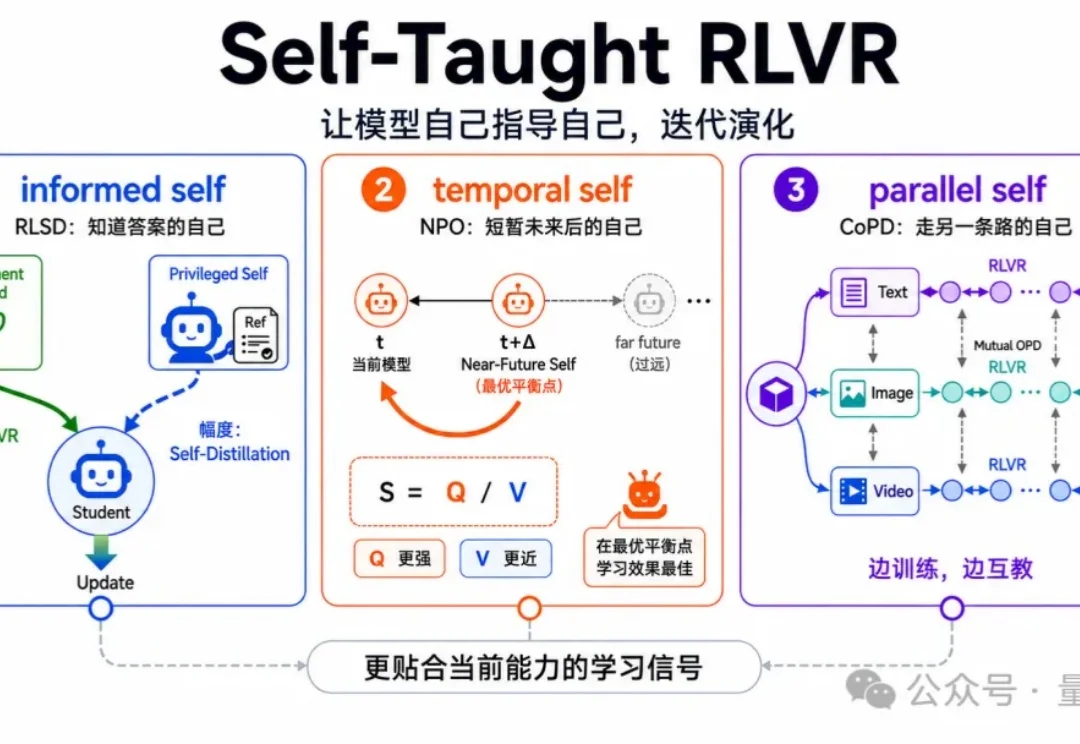
最近,京东和中科院信工所展开了Self-Taught RLVR的系列研究,并连发三篇后训练新作。
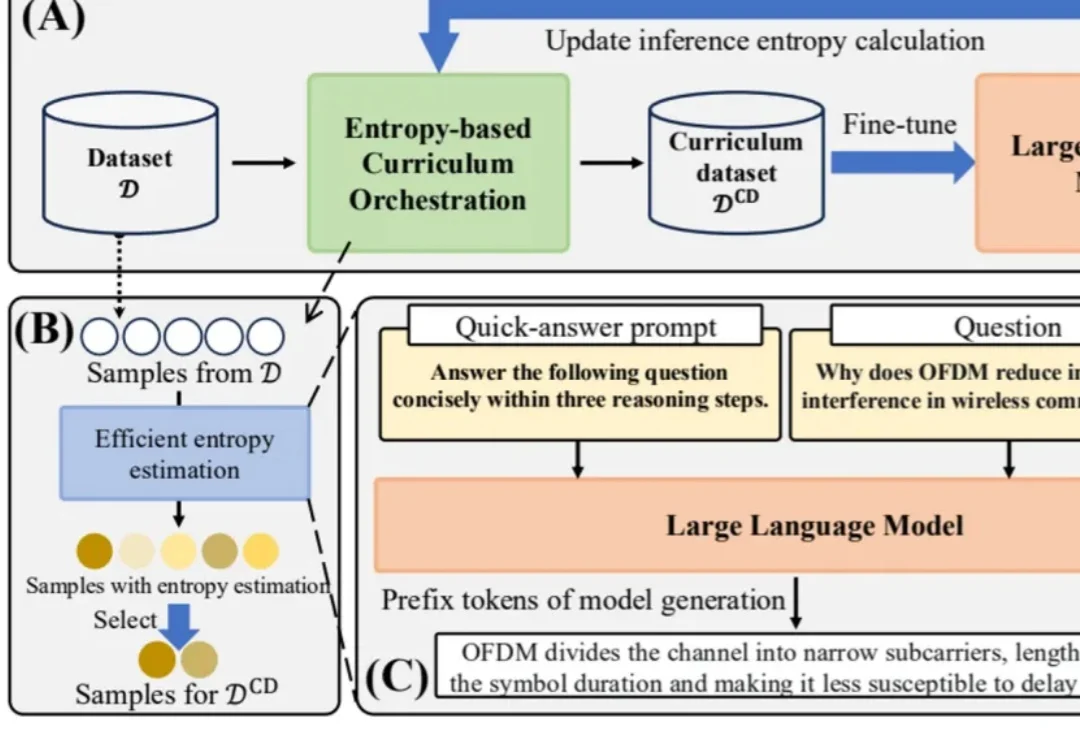
在大模型后训练中,数据不再只是 “越多越好”,而是要像人类学习一样,动态选择最合适难度的样本。华为提出的 EDCO 方法,将样本难度估计与动态课程编排引入领域大模型微调;数月后,由 Rutgers、Amazon、Google 等作者参与的 DARE 论文即引用 EDCO,并将其作为难度感知强化学习训练的重要对比基线。
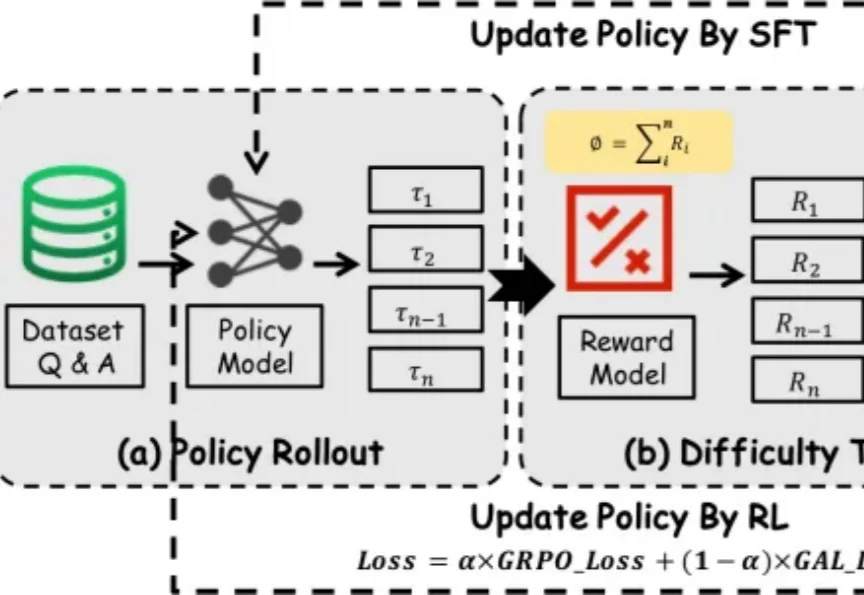
过去一段时间里,在围绕大模型推理能力增强的研究中,SFT 和 RL 是两类核心后训练范式 —— 前者稳定收敛快,能高效吸收高质量推理数据;后者更具探索性,有望推动模型实现复杂推理和分布外泛化。
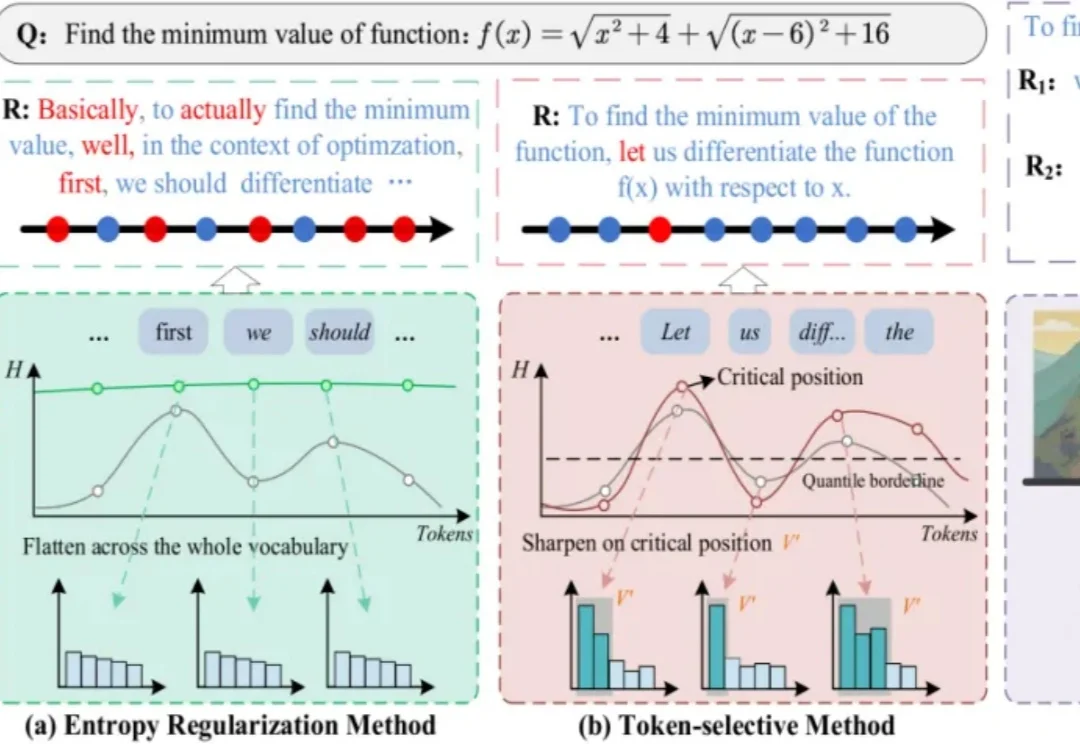
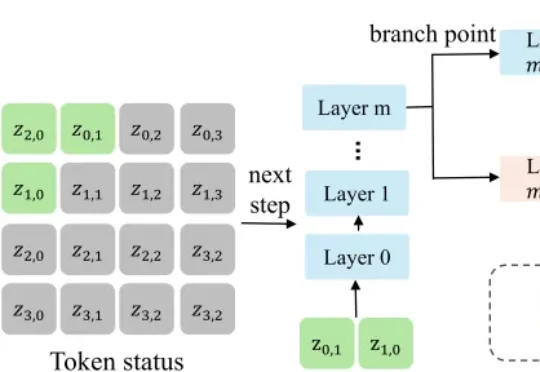
I²B-LPO 是一个面向 RLVR 后训练的探索增强框架,通过改进 rollout 策略引导模型生成更多样化的推理轨迹,将探索行为从 “重复采样” 推进到 “在关键节点生成更具区分度的推理轨迹”,在多个数学基准上同时提升准确率与语义多样性,最高分别达 5.3% 和 7.4%。该工作接收于 ACL 2026 Main,来自阿里达摩院 - 智能决策团队。
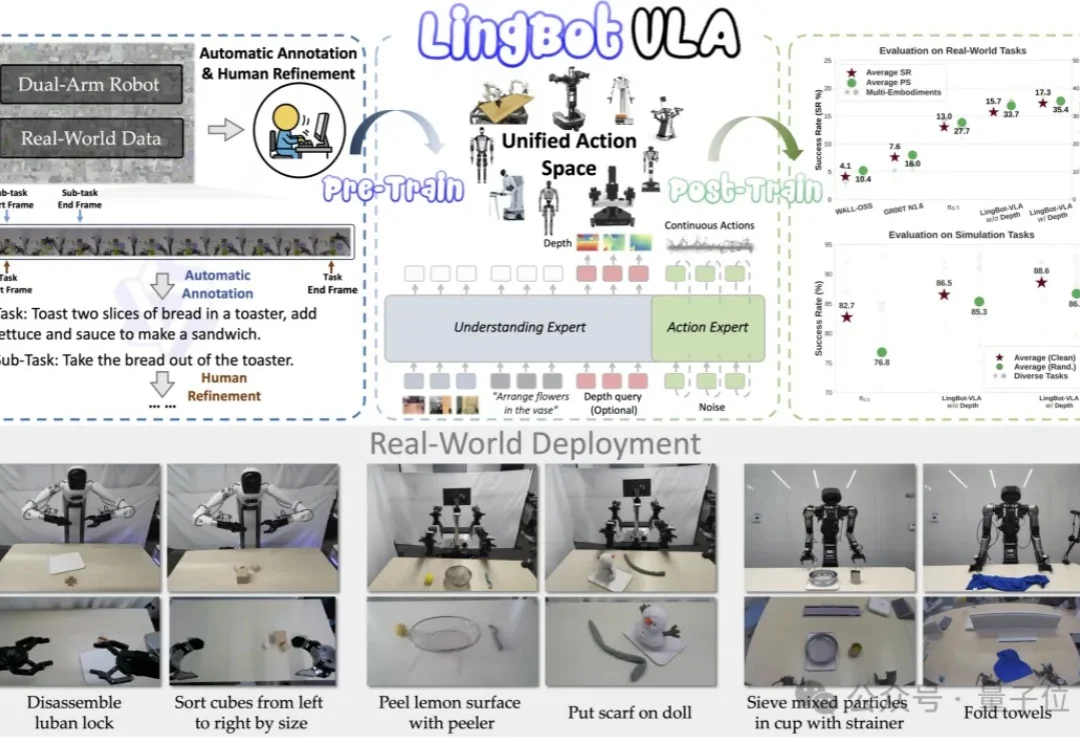
就在刚刚,蚂蚁集团旗下具身智能公司灵波科技传出新动作—— 全面开源其具身基座模型LingBot-VLA的真机后训练工具链。

当下的大模型后训练(Post-training)pipeline 中,On-Policy Distillation(OPD)已经成为了明星技术。从 Qwen3、MiMo 到 GLM-5,业界纷纷采用 OPD 并报告了巨大的性能提升。相比于强化学习(RL)稀疏的结果奖励,OPD 提供了密集的 Token 级别监督信号,看起来就像是一顿「免费的午餐」。

随着大模型后训练(Post-training)技术的发展,强化学习(RL)在提升模型推理能力方面的表现备受瞩目。