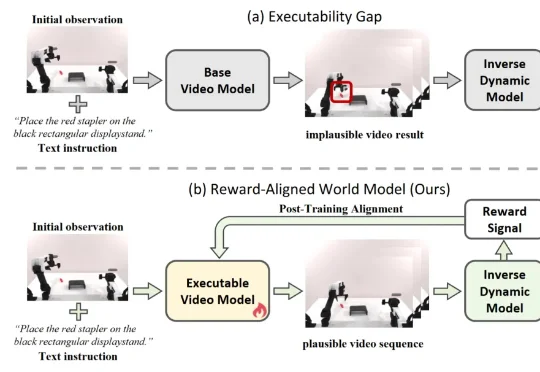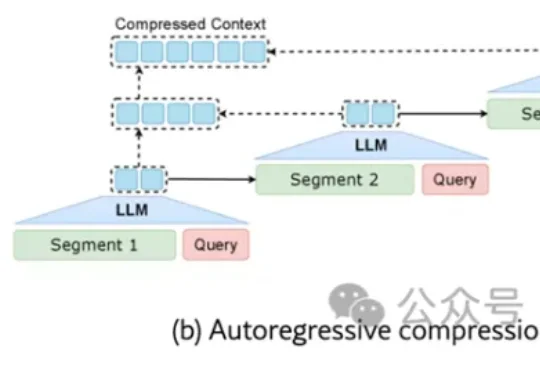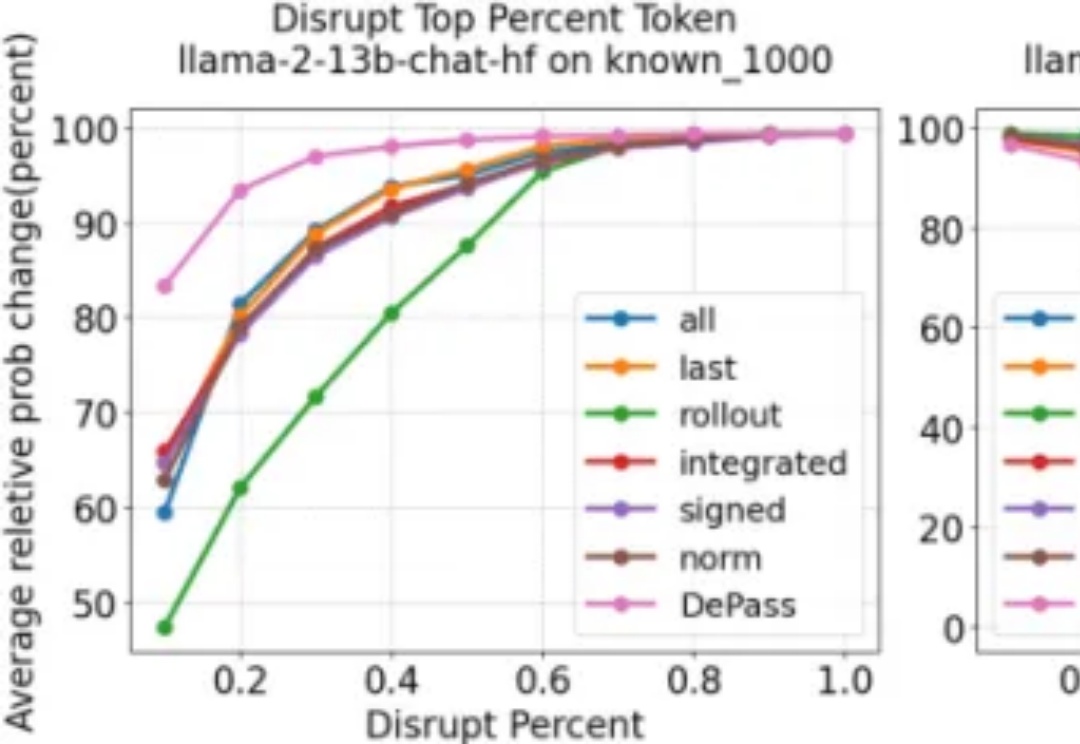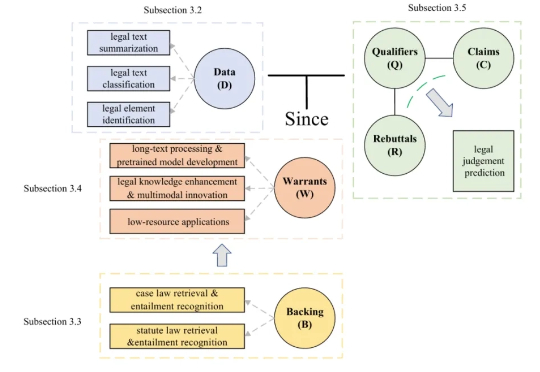
条条电路通罗马:大模型可解释性的「唯一机制」可能从一开始就不存在
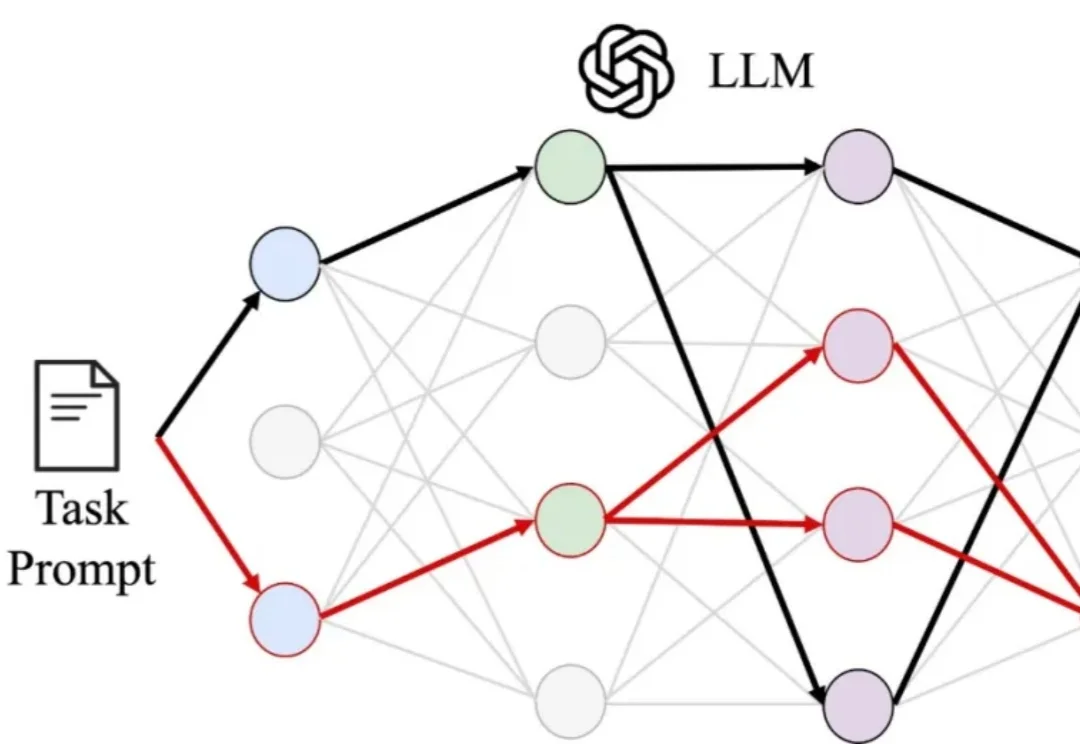
条条电路通罗马:大模型可解释性的「唯一机制」可能从一开始就不存在长期以来,机制可解释性(mechanistic interpretability)领域有一个几乎从未被明说、却被视为理所当然的前提:模型对于同一种任务的能力或表现,背后对应着一条唯一的、或近乎唯一的内部「电路」(circuit)。该领域的研究者们之所以要做「电路发现」(circuit discovery),是为了要把这些「特定的」电路找出来。
来自主题: AI技术研报
7766 点击 2026-06-30 15:12