
深度讨论新一轮模型发布:当智能进入月更时代 | Best Ideas
深度讨论新一轮模型发布:当智能进入月更时代 | Best Ideas当 AI 开始加速 AI,模型公司的迭代周期正在被进一步压缩,模型公司开始进入“月更时代”。
来自主题: AI资讯
8592 点击 2026-05-12 08:52
 搜索
搜索
当 AI 开始加速 AI,模型公司的迭代周期正在被进一步压缩,模型公司开始进入“月更时代”。

有个31B参数的大模型,正常需要80GB显存才能跑。但现在,24GB显存就能跑满血版。这个版本叫Gemma-4-31B-JANG_4M-CRACK——"CRACK"这个词不要理解歪了,它本质是量化压缩加上对齐微调之后的部署版本,不是什么黑客攻击,就是工程优化。24GB,MacBook Pro,直接跑。苹果用户优先优化,MLX原生支持,月下载13000次。
今日,百度推出新一代基础模型文心5.1。百度称,文心5.1将总参数压缩至约1/3、激活参数压缩至约1/2,使用业界同规模模型约6%的预训练成本,实现同级别模型基础效果领先。不过,百度并未明确说明这一“6%成本”的具体对标模型范围与口径。
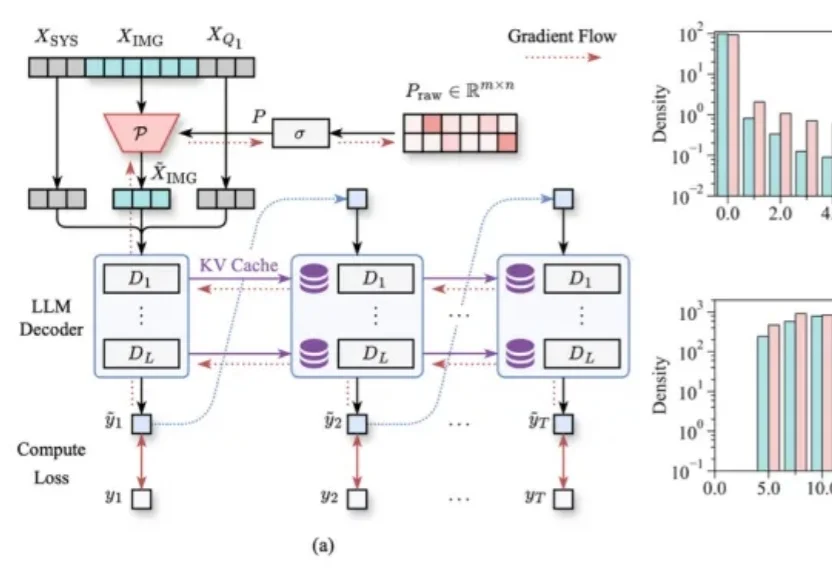
多轮视觉问答,正在成为LVLM推理效率的“照妖镜”。

AI投资新主题:超千亿美元砸向AI重塑传统行业介绍了AI热钱的新流向——寻找“物理世界的不可压缩性”。无论AI多先进,总要深入码头、林场、农田、工厂,重塑实业的生产函数与价值锚点。
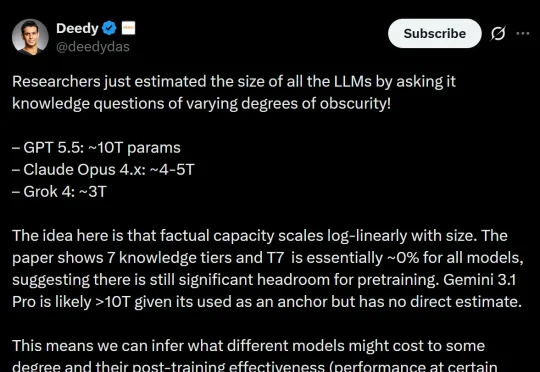
五一假期前,AI社区被一篇「GPT-5.5拥有近10万亿参数」的论文刷屏,今天这项研究就被研究者打假了!研究者表示,修正论文中的各种问题后,GPT-5.5的参数很可能约为1.5T。
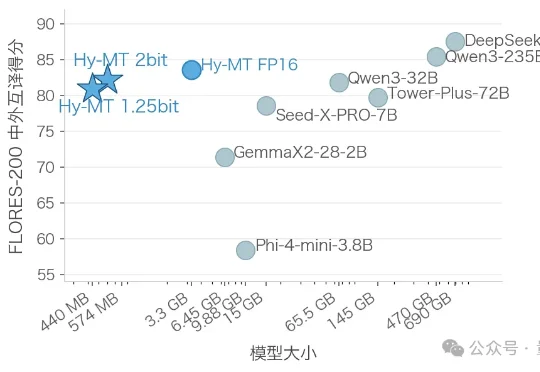
腾讯混元团队刚刚开源了一份硬核解决方案:推出极致量化压缩版本翻译模型Hy-MT1.5-1.8B-1.25bit,把支持33种语言的翻译大模型压缩至440MB。无需联网,下载后即可在手机本地运行 。官方测试显示,其翻译质量优于谷歌翻译。
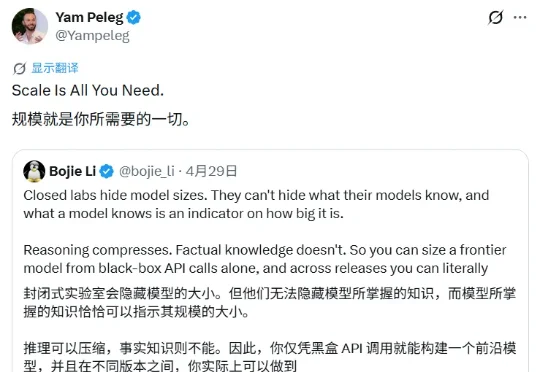
基于此,研究者在 89 个参数量已知的开源模型(规模从 1.35 亿到 1.6 万亿参数)上拟合出事实准确率与参数量的对数线性关系,拟合优度 R² = 0.917,并据此对闭源模型进行参数估算。

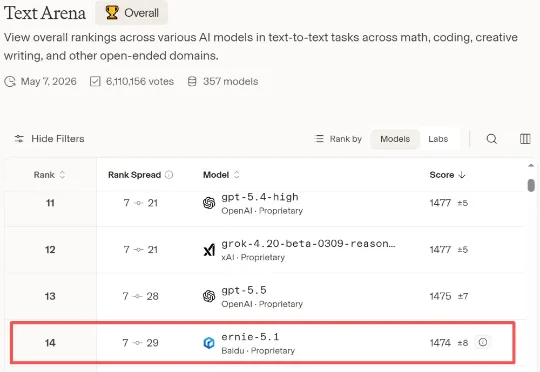
AI医疗最成熟的领域,迎来了一款重磅产品——颅脑CT超级智能体“小君医生2.0”。这是全球首个临床可用+检查项目级的颅脑CT智能体,能够覆盖90%的颅脑病变,诊断准确率达87.8%,90%以上病例无需修改或仅小幅度修改即可使用,将报告时效从15分钟大幅压缩至1分钟,已落地中国顶流三甲北京天坛医院,极大提升了医院影像诊断的效率。

过去十年,压缩在 CV 学术圈一直是个边缘方向——做生成、做大模型才是显学。但 SparcAI 的两位95后创始人各自做了多年压缩,然后在同一间 NTU 实验室相遇,两年后发布了 Sparc3D。模型 demo 上线当日冲上 HuggingFace Trending 榜首,论文被 NeurIPS 2025 录用。如今他们创办了 SparcAI,目标是一家世界模型公司。