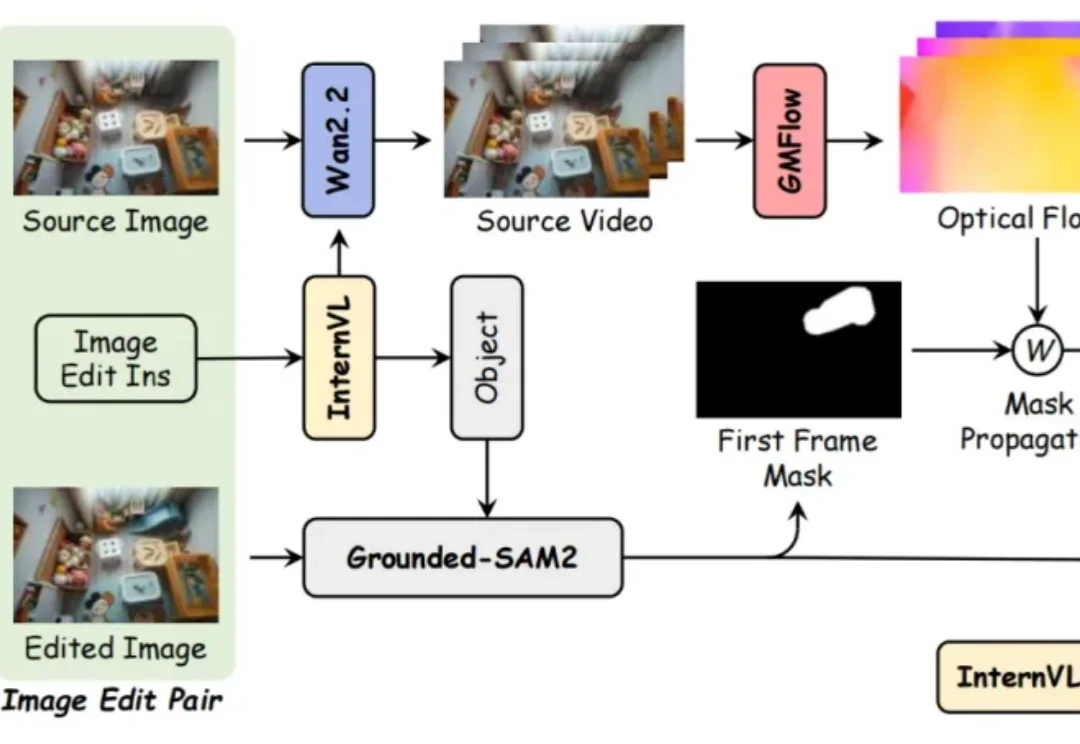
纯文本驱动视频编辑,清华&华为&中科大实现无需掩码/参考帧就能精准移除/添加对象
纯文本驱动视频编辑,清华&华为&中科大实现无需掩码/参考帧就能精准移除/添加对象近年来,基于扩散的视频生成模型的最新进展极大地提高了视频编辑的真实感和可控性。然而,文字驱动的视频对象移除添加依然面临巨大挑战:
来自主题: AI技术研报
8385 点击 2025-12-12 09:37
 搜索
搜索
近年来,基于扩散的视频生成模型的最新进展极大地提高了视频编辑的真实感和可控性。然而,文字驱动的视频对象移除添加依然面临巨大挑战:

白铂 博士,华为 2012 实验室理论研究部主任 信息论首席科学家
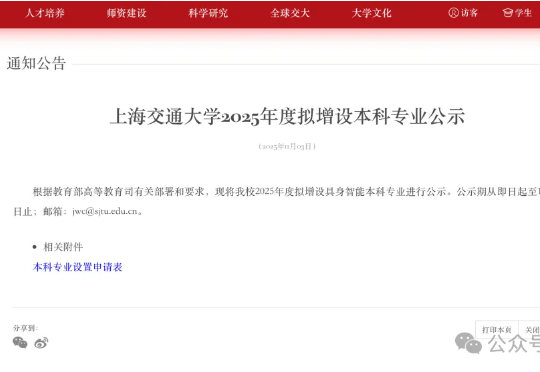
鹭羽 发自 凹非寺 量子位 | 公众号 QbitAI 具身智能的风也是卷到高校了。 近期,上海交通大学发布公告,宣布即日起拟增设具身智能本科专业。 环顾全球,目前还没有将具身智能作为独立本科专业开设的

在 LLM 优化领域,有两个响亮的名字:Adam(及其变体 AdamW)和 Muon。
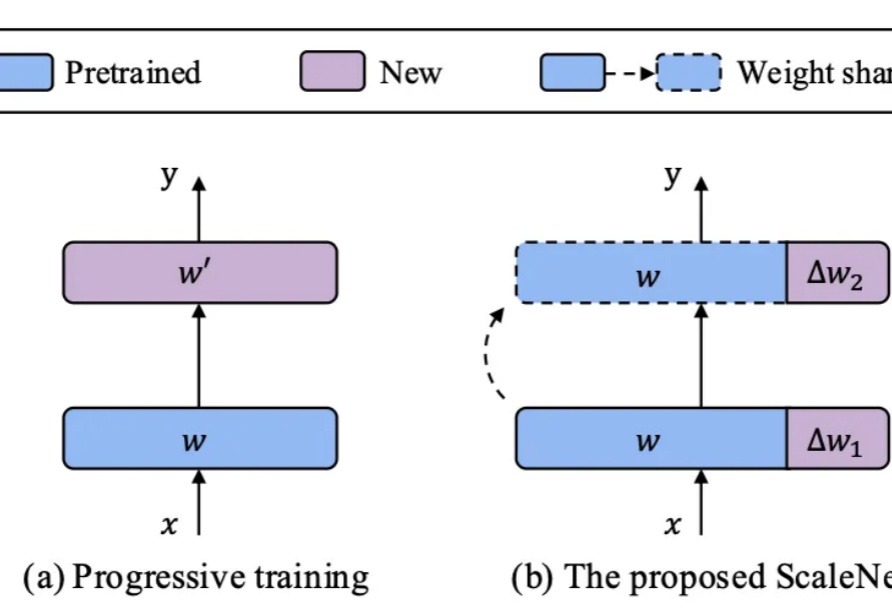
在基础模型领域,模型规模与性能之间的缩放定律(Scaling Law)已被广泛验证,但模型增大也伴随着训练成本、存储需求和能耗的急剧上升。如何在控制参数量的前提下高效扩展模型,成为当前研究的关键挑战。

华为公司董事、ICT BG CEO 杨超斌在致辞中表示,AI 技术正以前所未有的速度改变各行各业,传统服务器集群无法有效满足算力不断增长的诉求。华为已经开放灵衢互联协议 2.0,支持产业界伙伴打造基于灵衢的超节点,还将向开源欧拉社区贡献支持超节点的操作系统插件代码,提供「内存统一编址」

华为在世界模型上又有新动作:投了一家物理AI公司。

今年是 AI 大模型的落地关键年。大模型技术在快速进步,但行业落地仍面临三大痛点:开发门槛高、场景碎片化、端侧能力有限。结合 AI 能力与云计算,在 CGC2025 大会上,华为云提出的 Versatile 智能体平台与 CloudDevice 云终端协同,正致力于破解这些难题。
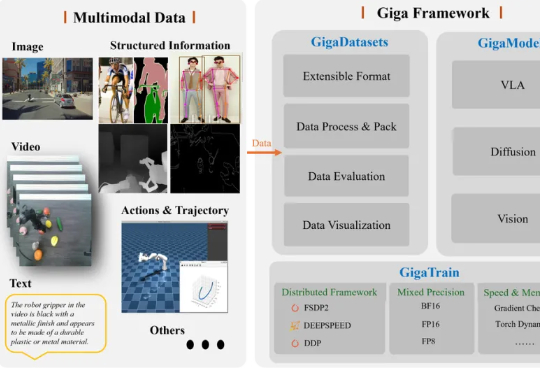
据《智能涌现》获悉,极佳视界近日完成新一轮亿元级A1轮融资,本轮融资由华为哈勃、华控基金联合投资。此前8月底,极佳视界宣布完成Pre-A&Pre-A+连续两轮数亿元融资。2个月3轮融资,体现了资本市场对极佳视界团队实力、技术路线和业务推进的认可,也折射出投资方对“物理世界通用智能”(物理AI)关键转折点的判断。
AI大house真来了。