TPAMI 2026 | 北大彭宇新团队提出CPL++框架,实现视觉定位模型的「自知之明」和「自我纠错」
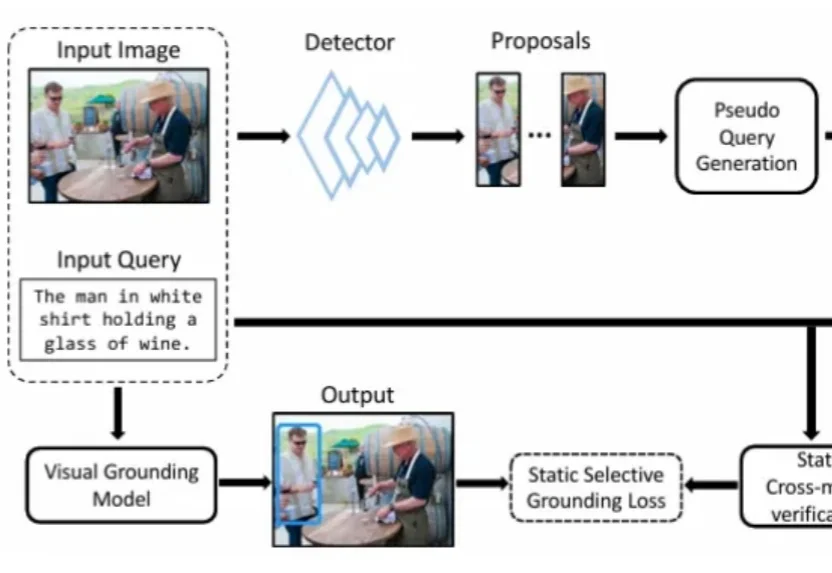
TPAMI 2026 | 北大彭宇新团队提出CPL++框架,实现视觉定位模型的「自知之明」和「自我纠错」本文是北京大学彭宇新教授团队在视觉定位方向的最新研究成果,相关论文已被顶级国际期刊 IEEE TPAMI 接收。为视觉定位模型赋予「自知之明」能力 —— 通过自监督的关联校正与验证模块,在训练过程中动态识别、衰减并纠正错误的监督信号。大量实验证明,让模型学会「自我纠错」,是突破弱监督视觉定位瓶颈的有效途径。
来自主题: AI技术研报
8048 点击 2026-04-17 08:41