何恺明团队发布像素空间文生图模型MiniT2I
何恺明团队发布像素空间文生图模型MiniT2I文本生成图像的领域早已经是一片红海,看上去已经卷无可卷了。
来自主题: AI技术研报
8830 点击 2026-06-22 16:53
 搜索
搜索
文本生成图像的领域早已经是一片红海,看上去已经卷无可卷了。

近年来,基于扩散模型的图像生成技术发展迅猛,催生了Stable Diffusion、Midjourney等一系列强大的文生图应用。然而,当前主流的训练范式普遍依赖一个核心组件——变分自编码器(VAE),这也带来了长久以来困扰研究者们的几个问题:
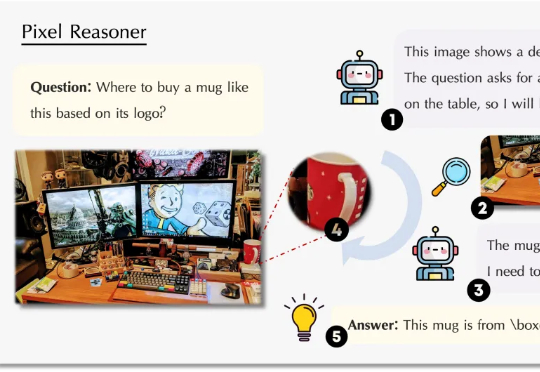
视觉语言模型(VLM)正经历从「感知」到「认知」的关键跃迁。 当OpenAI的o3系列通过「图像思维」(Thinking with Images)让模型学会缩放、标记视觉区域时,我们看到了多模态交互的全新可能。
本文作者分别来自中国科学院大学和中国科学院计算技术研究所。第一作者裴高政为中国科学院大学博士二年级学生,本工作共同通讯作者是中国科学院大学马坷副教授和黄庆明教授。

在 2024 世界经济论坛的一次会谈中,图灵奖得主 Yann LeCun 提出用来处理视频的模型应该学会在抽象的表征空间中进行预测,而不是具体的像素空间 [1]。借助文本信息的多模态视频表征学习可抽取利于视频理解或内容生成的特征,

在 2024 世界经济论坛的一次会谈中,图灵奖得主、Meta 首席 AI 科学家 Yann LeCun 被问到了这个问题。他认为,虽然这个问题还没有明确的答案,但适合用来处理视频的模型并不是我们现在大范围应用的生成模型。而且新的模型应该学会在抽象的表征空间中预测,而不是在像素空间中。