UC伯克利:让推理模型少思考,准确率反而更高了!
UC伯克利:让推理模型少思考,准确率反而更高了!让推理模型不要思考,得到的结果反而更准确?
来自主题: AI技术研报
9389 点击 2025-04-18 09:34
 搜索
搜索
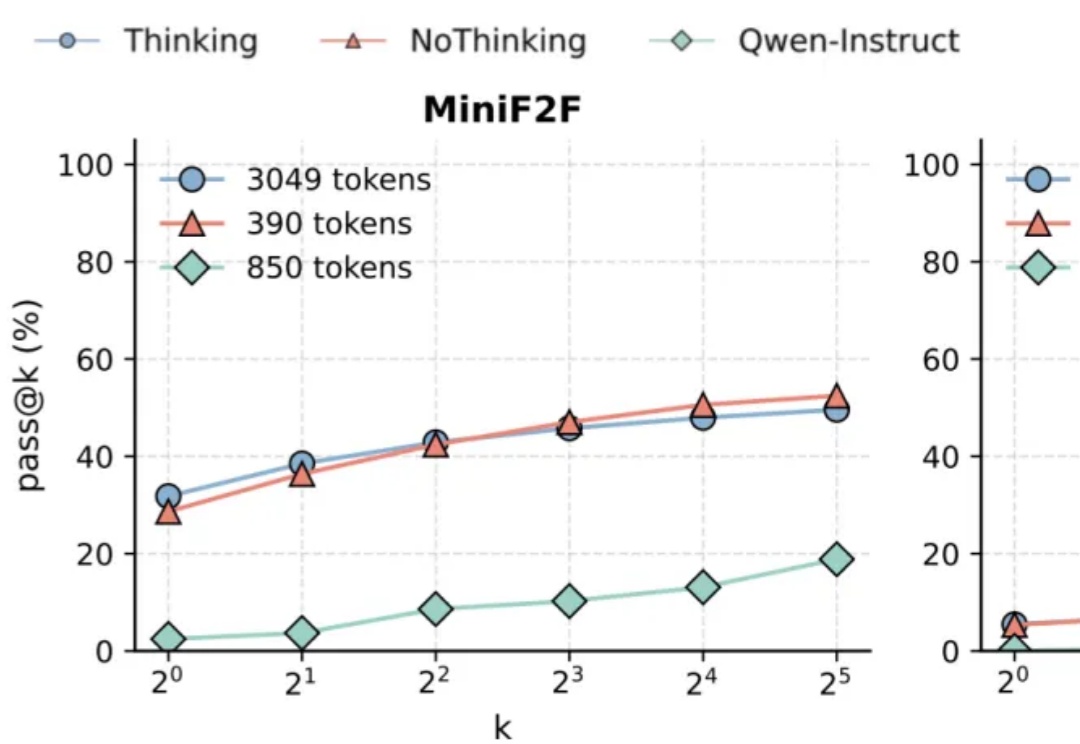
让推理模型不要思考,得到的结果反而更准确?
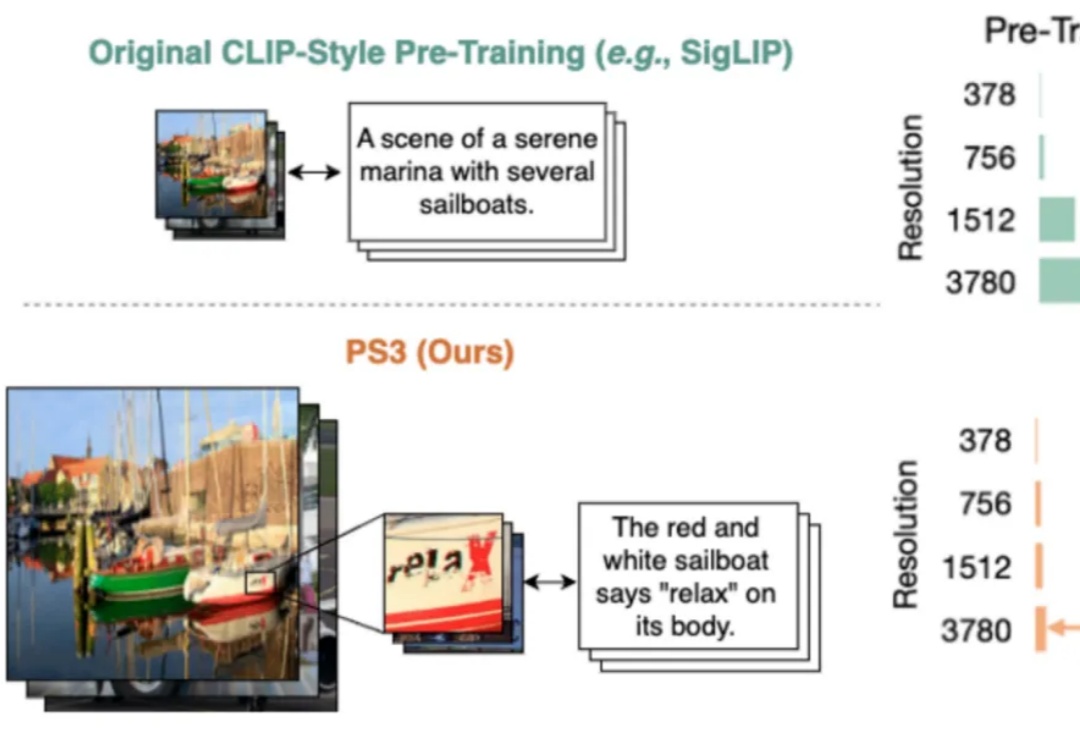
当前,所有主流的视觉基础模型(如 SigLIP、DINOv2 等)都仍然在低分辨率(如 384 * 384 分辨率)下进行预训练。对比人类视觉系统可以轻松达到 10K 等效分辨率,这种低分辨率预训练极大地限制了视觉模型对于高清细节的理解能力。
OpenAI o1/o3-mini级别的代码推理模型竟被抢先开源!UC伯克利和Together AI联合推出的DeepCoder-14B-Preview,仅14B参数就能媲美o3-mini,开源代码、数据集一应俱全,免费使用。
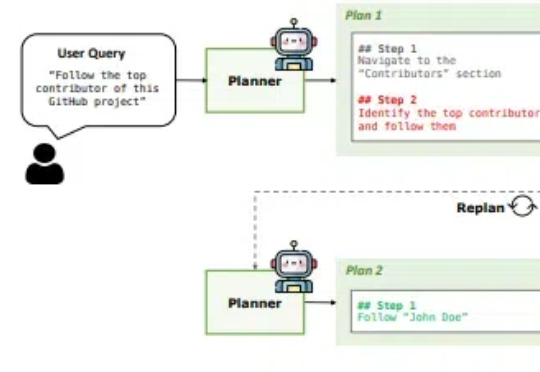
当你要求AI"帮我订一张去纽约的机票"时,它需要理解目标、分解步骤、适应变化,这个过程远比看起来复杂。UC伯克利的研究者们带来了振奋人心的新发现:通过将任务规划和执行分离的PLAN-AND-ACT框架,他们成功将智能体在长期任务中的规划能力提升了54%,创造了新的技术突破。

大模型同样的上下文窗口,只需一半内存就能实现,而且精度无损? 前苹果ASIC架构师Nils Graef,和一名UC伯克利在读本科生一起提出了新的注意力机制Slim Attention。
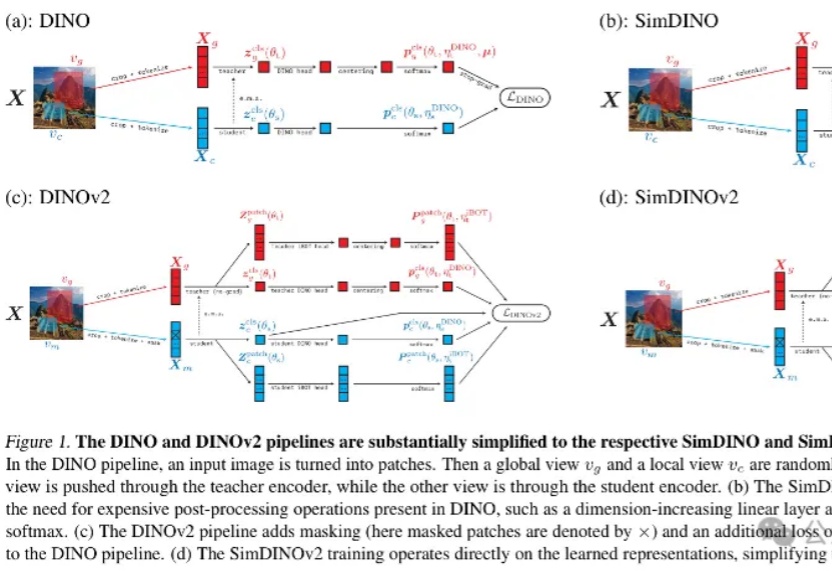
最新开源的视觉预训练方法,马毅团队、微软研究院、UC伯克利等联合出品!
生物学大模型又迎新里程碑!2025 年 2 月 19 日,来自 Arc Institute、英伟达、斯坦福大学、加州大学伯克利分校和加州大学旧金山分校的科学家们,联合发布了生物学大模型 Evo2。
近日,斯坦福、UC伯克利等多机构联手发布了开源推理新SOTA——OpenThinker-32B,性能直逼DeepSeek-R1-32B。其成功秘诀在于数据规模化、严格验证和模型扩展。

只用4500美元成本,就能成功复现DeepSeek?就在刚刚,UC伯克利团队只用简单的RL微调,就训出了DeepScaleR-1.5B-Preview,15亿参数模型直接吊打o1-preview,震撼业内。

基于一段文本提问时,人类和大模型会基于截然不同的思维模式给出问题。大模型喜欢那些需要详细解释才能回答的问题,而人类倾向于提出更直接、基于事实的问题。