外媒:苹果内部讨论买Perplexity,140亿美元史上最大收购?
外媒:苹果内部讨论买Perplexity,140亿美元史上最大收购?第一个 AI 搜索引擎,要归苹果了?
来自主题: AI资讯
7613 点击 2025-06-21 19:47
 搜索
搜索
第一个 AI 搜索引擎,要归苹果了?

前有美图的出海,验证了“颜值经济”的普适性,也悄然改变着大众对于修图工具类产品的消费认知。

一个大模型有了火星图片,能做什么?
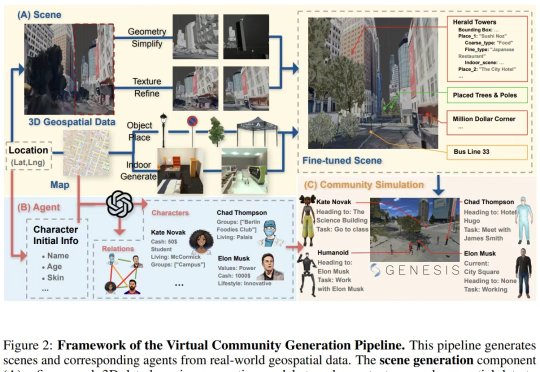
一个真实世界模拟器。

最近,一类「穿越 vlog」爆火了。有人让 Veo 3 变成「时间机器」,将人们带回历史事件中进行现场直播。

硬氪获悉,触觉感知与具身智能领军企业「帕西尼感知科技」(以下简称“帕西尼”),已于近日完成新一轮 A 系列融资。
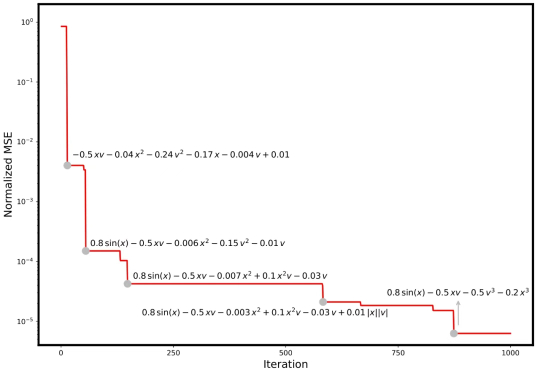
随着 AI4Science 的浪潮席卷科研各领域,如何将强大的人工智能模型真正用于分析科学数据、构建数学模型、发现科学规律,正成为该领域亟待突破的关键问题。

陶哲轩罕见接受了一次长长长长访谈,把他关于数学、AI、教育和人类智慧的最新认知,都对外分享了。
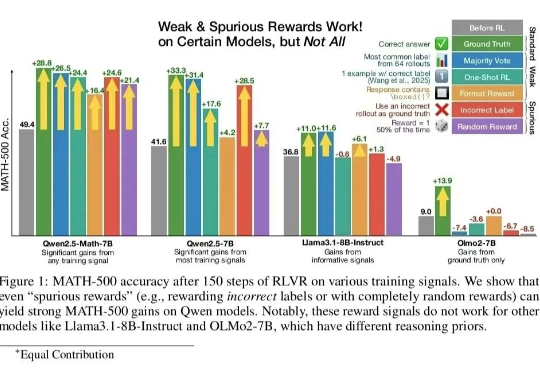
在人工智能领域,大型语言模型(LLM)的推理能力正以前所未有的速度发展。
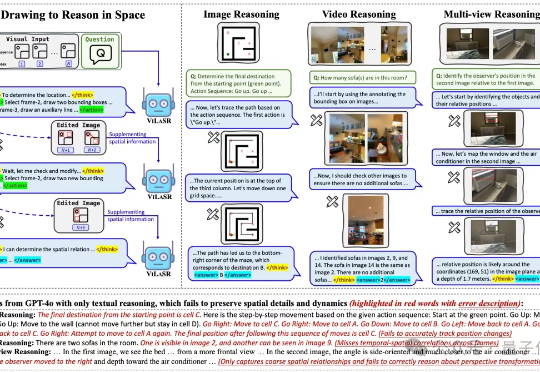
“边看边画,边画边想”,让大模型掌握空间思考能力,结果直接实现空间推理任务新SOTA。