像挖币一样挖激活函数?DeepMind搭建「算力矿场」,暴力搜出下一代ReLU
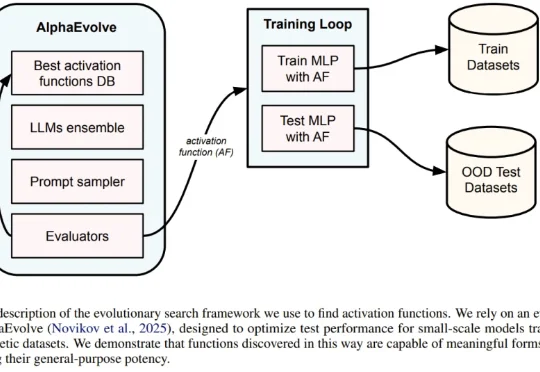
像挖币一样挖激活函数?DeepMind搭建「算力矿场」,暴力搜出下一代ReLU一直以来,神经网络的激活函数就像是 AI 引擎中的火花塞。从早期的 Sigmoid、Tanh,到后来统治业界的 ReLU,再到近年来的 GELU 和 Swish,每一次激活函数的演进都伴随着模型性能的提升。但长期以来,寻找最佳激活函数往往依赖于人类直觉或有限的搜索空间。
来自主题: AI技术研报
7075 点击 2026-02-08 11:47