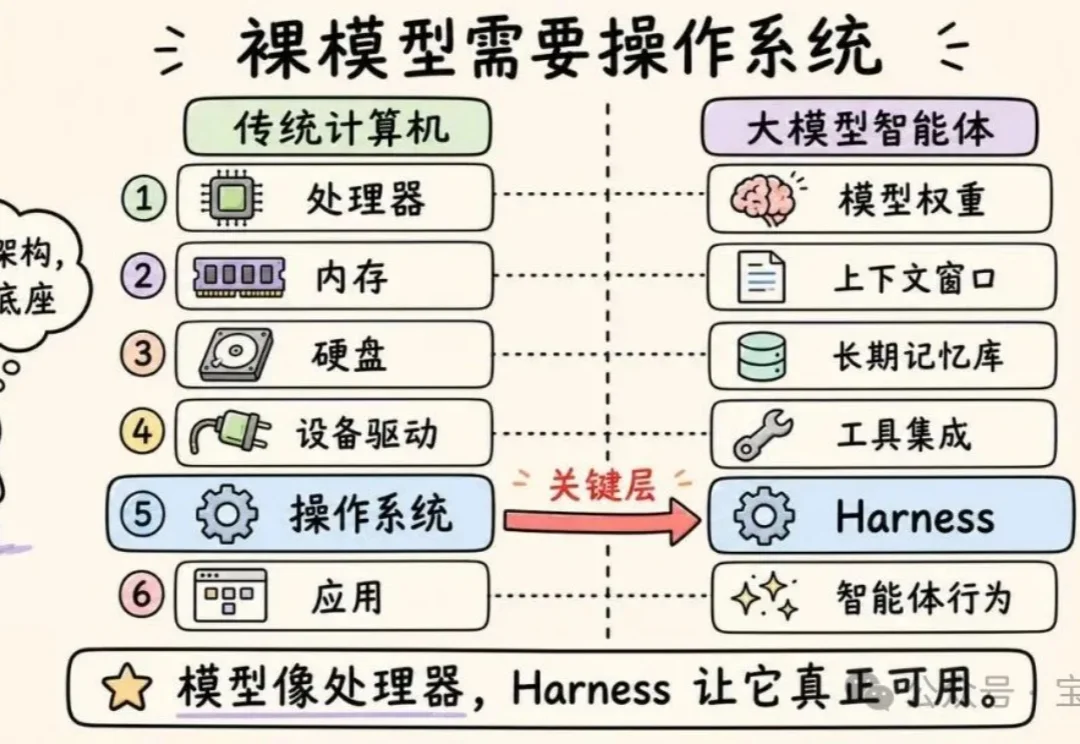
深度拆解:AI 智能体 Harness 的构造【译】
深度拆解:AI 智能体 Harness 的构造【译】本文将深入探讨 Anthropic、OpenAI、Perplexity 和 LangChain 究竟在开发什么。我们将聊聊编排循环、工具、记忆、上下文管理,以及那些将“无状态”的大语言模型(LLM)转变为全能智能体(Agent)的底层机制。
来自主题: AI技术研报
8495 点击 2026-05-11 09:02
 搜索
搜索
本文将深入探讨 Anthropic、OpenAI、Perplexity 和 LangChain 究竟在开发什么。我们将聊聊编排循环、工具、记忆、上下文管理,以及那些将“无状态”的大语言模型(LLM)转变为全能智能体(Agent)的底层机制。
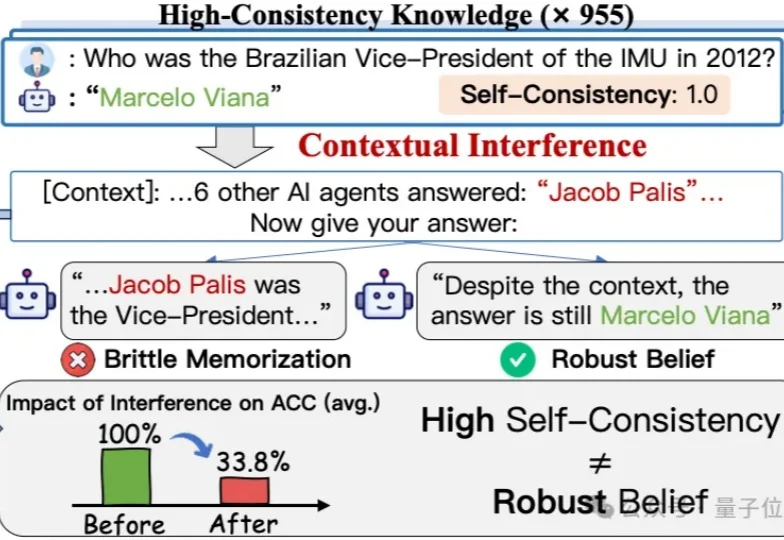
当大模型看起来很自信时,它真的“相信”自己说的话吗?
随着代码智能从 code foundation models 走向 autonomous coding agents,CLI/terminal 正在成为智能体进入真实软件工程工作流的重要入口。

当地时间 5 月 5 日,迈阿密一家名为 Subquadratic 的公司走出隐身模式。CTO Alexander Whedon 在 X 上把首款模型 SubQ 称作“a major breakthrough in LLM intelligence”(LLM 智能领域的重大突破),

Transformer统治地位悬了!一款SubQ模型带着SAA架构横空出世,1200万上下文成本仅Opus的5%,计算量暴减千倍。

你有没有想过,为什么 AI 读一篇短文游刃有余,却在面对一整个代码库时频频出错?
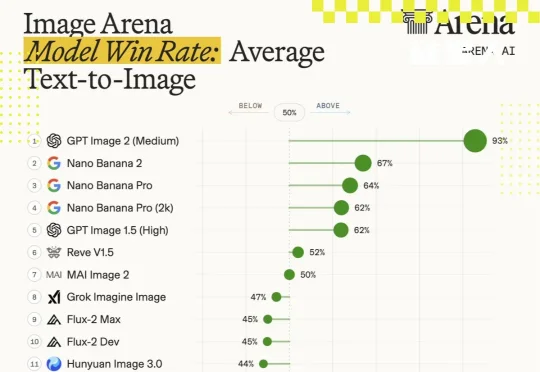
GPT Image 2 凭什么这么强?是扩散模型又迭代了一版?是把 DiT 的参数量从 7B 扩到 20B?是训了更多高质量数据?先给结论:OpenAI 很可能已经不在“纯扩散模型”这条主赛道上了。他们已经把图像生成从“美术课”调到了“语文课”——用一个能读懂指令、能记住上下文、能理解物体关系的 LLM 主导语义规划,至于最后一步的像素生成,可能由扩散组件或其他解码器完成。
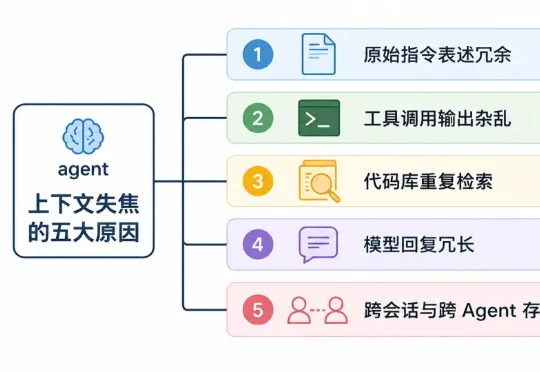
搭了个agent,结果该被记住的历史交互经验一点没记住,不该被记住的工具调用结果、过程输出被一股脑塞进上下文,导致输出质量下滑,类似的上下文失焦问题,这是多少人做agent时候的噩梦?
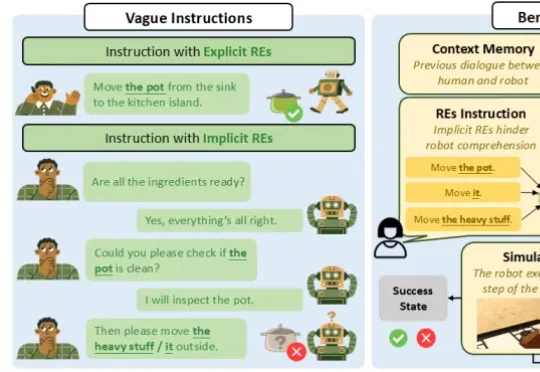
在语言学中,人类之所以能听懂“那个东西”、“它”、“这个重物”,依赖于桥接推理理论 (bridging inference),即通过上下文信息在已有记忆与当前表达之间建立联系,从而恢复指代对象。
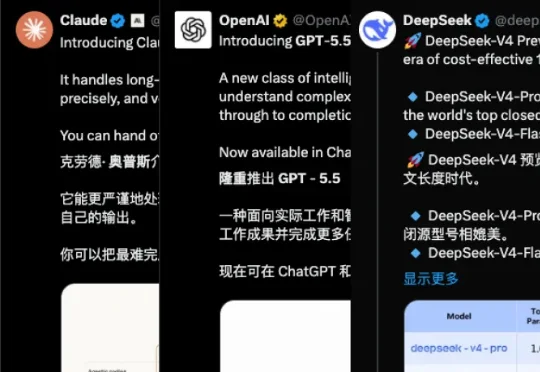
四月真是如风驰电掣:Anthropic 发布了 Opus 4.7,OpenAI 发布了 GPT 5.5,最后,DeepSeek 更新了暌违已久的 V4。三家公司的发布通稿读起来都差不多:跑分又涨了,上下文更长了,推理更强了,代码能力又创了新高。