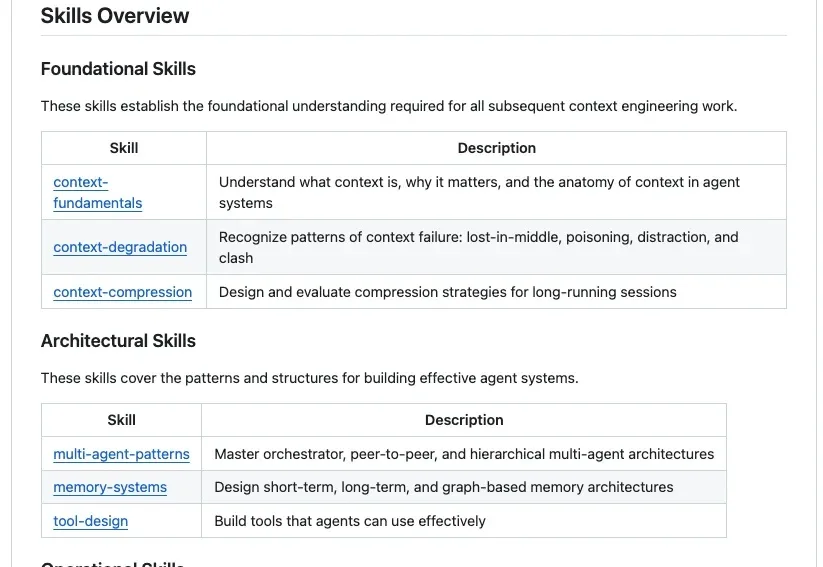
上下文工程的Agent Skills来了,CC、Codex直接用,一周获2.3k star
上下文工程的Agent Skills来了,CC、Codex直接用,一周获2.3k starGitHub上最近出现了一个非常火的项目Agent-Skills-for-Context-Engineering,发布不到一周就斩获了2.3k Stars。为什么它能瞬间引爆社区?因为站在2025年末的节点上,我们已经受够了那些只存在于大厂白皮书里的Context Engineering(上下文工程) 理论。
来自主题: AI技术研报
9709 点击 2025-12-26 10:56