
Context 即 Agent:下一场 AI 产品战争,是上下文之争
Context 即 Agent:下一场 AI 产品战争,是上下文之争本篇文章根据我在本月 43 Talks 线下活动中的分享整理而成。主理人李继刚邀请我时,给的主题词只有一个:Context。我想从 Agent 的视角出发,讨论一个判断:随着模型和 Harness 逐步趋同,真正决定 Agent 能力边界的,会越来越是 Context。
来自主题: AI资讯
8910 点击 2026-07-01 15:41
 搜索
搜索
本篇文章根据我在本月 43 Talks 线下活动中的分享整理而成。主理人李继刚邀请我时,给的主题词只有一个:Context。我想从 Agent 的视角出发,讨论一个判断:随着模型和 Harness 逐步趋同,真正决定 Agent 能力边界的,会越来越是 Context。

近日,穗升科技首款产品Memoket在海外正式开启预售。这是一款AI Memory可穿戴硬件,仅11克,分表带款和手环款两种形态,待机超过30天,连续录音续航20小时。它可以将物理世界中所听到的信息结构化,需要时调给Agent,实现跨时间聚合和Context(上下文)串联。

如果只看标题,它很容易被归到“又一个万亿参数大模型”的队伍里:1.6 万亿总参数、MoE 架构、100 万 token 上下文、面向代码和 Agent 场景。但这次真正值得看的,不只是模型有多大,而是它背后的三个问题:国产算力能不能支撑前沿级大模型训练?
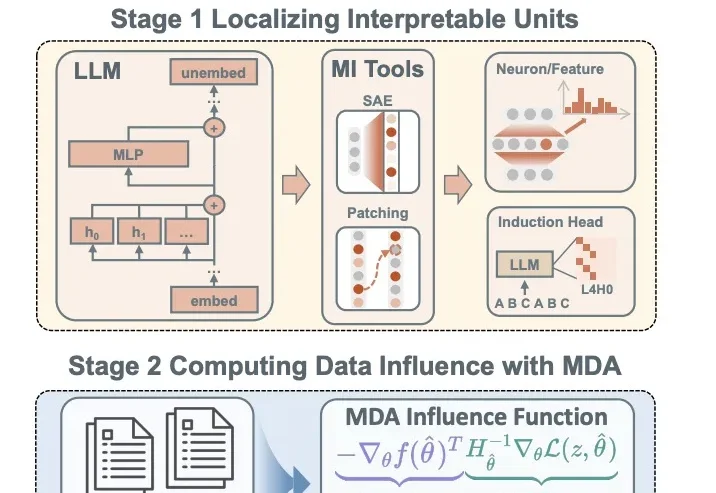
近年来,大语言模型展现出了越来越强的能力,从上下文学习(In-Context Learning, ICL)到复杂推理、代码生成,这些能力不断刷新人们对模型能力边界的认知。

太酷了,这个 Agent 的体验。感觉这是最近除了 Codex 外,最让我惊喜的 Agent 产品了。今天想和大家分享一下。
6 月 11 日凌晨,小米 MiMo 团队公开了一个叫 MiMo Code 的项目,定位是终端编程 Agent,MIT 协议开源。官方宣传重点有三处,14 天 5 人团队投入的“vibe coding”开发叙事、Claude Code 之上的 SWE-Bench Pro 跑分。以及“无限上下文”的记忆架构。

当大模型公司还在竞争更长的上下文窗口、更强的推理能力和更复杂的 Agent 工作流时,一家名为 Engram 的新公司选择押注另一个问题:AI 能不能像人一样,持续从每天接触到的资料、对话和经验中学习?
一个开源的省Token工具Headroom,火了!公开页面显示Headroom已有4万多个star,最新版本是v0.26.0。一个“上下文压缩层”工具能到这个热度,已经说明很多问题。
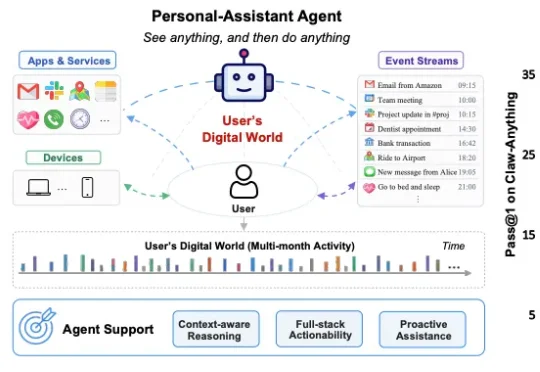
我们相信,常驻型 (always-on) AI 助理的下一次飞跃,不在于把某一个模型单点调得更聪明,而在于扩展智能体的上下文 (Scaling Agent Context)—— 不断拓宽助理能够持续 "感知 — 推理 — 执行" 的范围,作为生活连接器连接用户的信息孤岛,直到它能接管用户的整个数字世界。
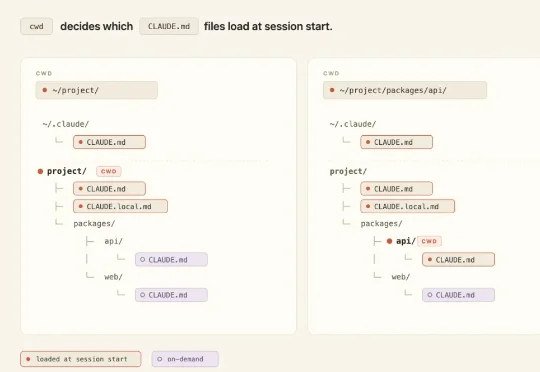
在常规的对话外,Claude Code(也可以是 Codex)其实还提供了一些别样的控制(或者说:上下文注入)方法,比如:CLAUDE.md、Rules、Skills、Subagents、Hooks、Output Styles、以及 System Prompt Append