
准确率达60.8%,浙大基于Transformer的化学逆合成预测模型,登Nature子刊
准确率达60.8%,浙大基于Transformer的化学逆合成预测模型,登Nature子刊逆合成是药物发现和有机合成中的一项关键任务,AI 越来越多地用于加快这一过程。
来自主题: AI技术研报
11695 点击 2024-08-07 14:04
 搜索
搜索
逆合成是药物发现和有机合成中的一项关键任务,AI 越来越多地用于加快这一过程。

卖身,AI大模型创企的归宿?
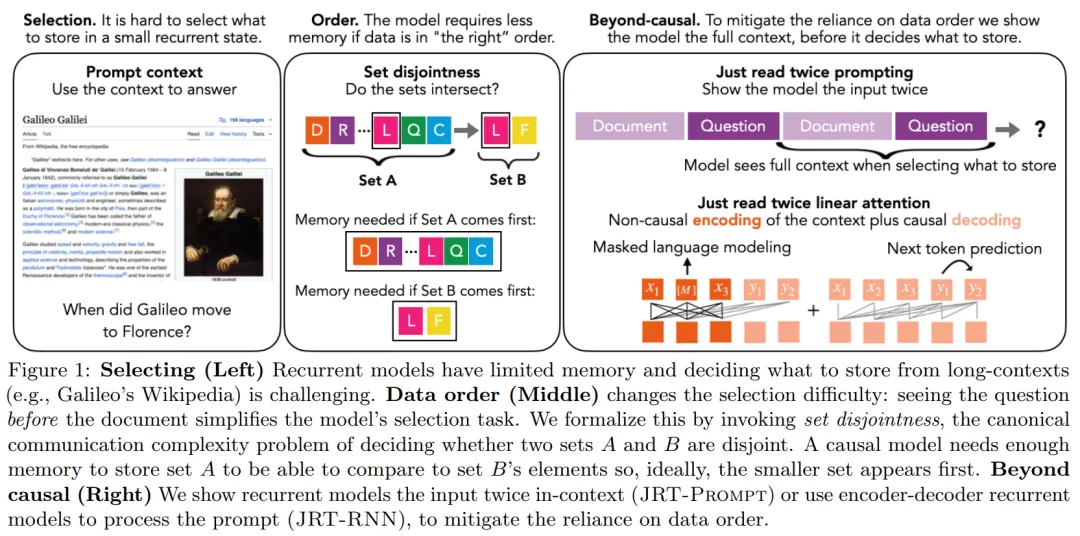
在当前 AI 领域,大语言模型采用的主流架构是 Transformer。不过,随着 RWKV、Mamba 等架构的陆续问世,出现了一个很明显的趋势:在语言建模困惑度方面与 Transformer 较量的循环大语言模型正在快速进入人们的视线。

人工智能赛道最受关注的独角兽之一,Character.AI迎来了新命运。尽管近期媒体报道,伊隆·马斯克的 xAI 正在考虑收购Character.AI,但最终摘到果实的是谷歌。

明星AI独角兽Character.AI,核心团队被谷歌打包带走了。

明星AI独角兽Character.AI,核心团队被谷歌打包带走了。

AI 初创者的归宿还是大厂?

Transformer大模型尺寸变化,正在重走CNN的老路!
RNN每个step的隐状态都取决于上一个step的输出,这种连续的状态转移方式使得RNN天然带有位置信息。

Transformer中的信息流动机制,被最新研究揭开了: