免剪辑直出!AI生成多角色同框对话视频,动态路由精准绑定音频
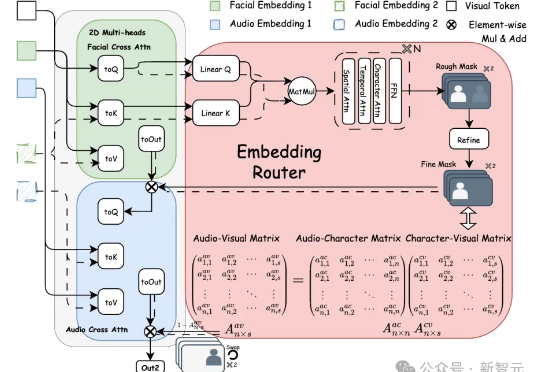
免剪辑直出!AI生成多角色同框对话视频,动态路由精准绑定音频Bind-Your-Avatar是一个基于扩散Transformer(MM-DiT)的框架,通过细粒度嵌入路由将语音与角色绑定,实现精准的音画同步,并支持动态背景生成。该框架还引入了首个针对多角色对话视频生成的数据集MTCC和基准测试,实验表明其在身份保真和音画同步上优于现有方法。
来自主题: AI技术研报
8370 点击 2025-07-18 11:44
 搜索
搜索
Bind-Your-Avatar是一个基于扩散Transformer(MM-DiT)的框架,通过细粒度嵌入路由将语音与角色绑定,实现精准的音画同步,并支持动态背景生成。该框架还引入了首个针对多角色对话视频生成的数据集MTCC和基准测试,实验表明其在身份保真和音画同步上优于现有方法。

Transformer杀手来了?KAIST、谷歌DeepMind等机构刚刚发布的MoR架构,推理速度翻倍、内存减半,直接重塑了LLM的性能边界,全面碾压了传统的Transformer。网友们直呼炸裂:又一个改变游戏规则的炸弹来了。
大模型在潜空间中推理,带宽能达到普通(显式)思维链(CoT)的2700多倍?
AI也能选择性失忆?Meta联合NYU发布新作,轻松操控缩放Transformer注意头,让大模型「忘掉狗会叫」。记忆可删、偏见可调、安全可破,掀开大模型「可编辑时代」,安全边界何去何从。
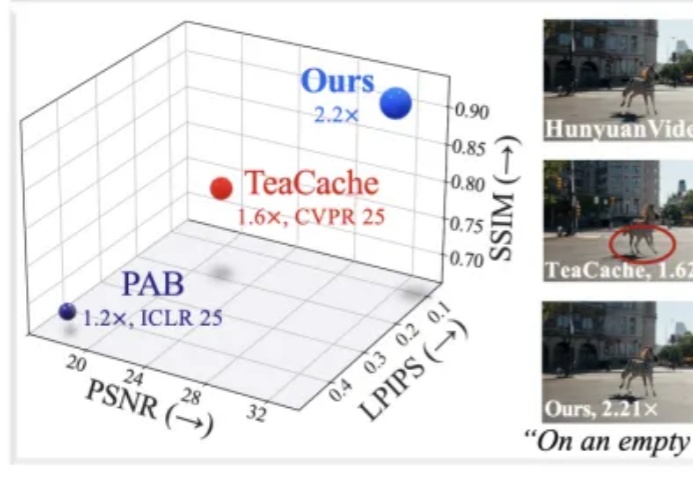
近年来,随着扩散模型(Diffusion Models)和扩散 Transformer(DiT)在视频生成领域的广泛应用,AI 合成视频的质量和连贯性有了飞跃式提升。像 OpenAI Sora、HunyuanVideo、Wan2.1 等大模型,已经能够生成结构清晰、细节丰富且高度连贯的长视频内容,为数字内容创作、虚拟世界和多媒体娱乐带来了巨大变革。
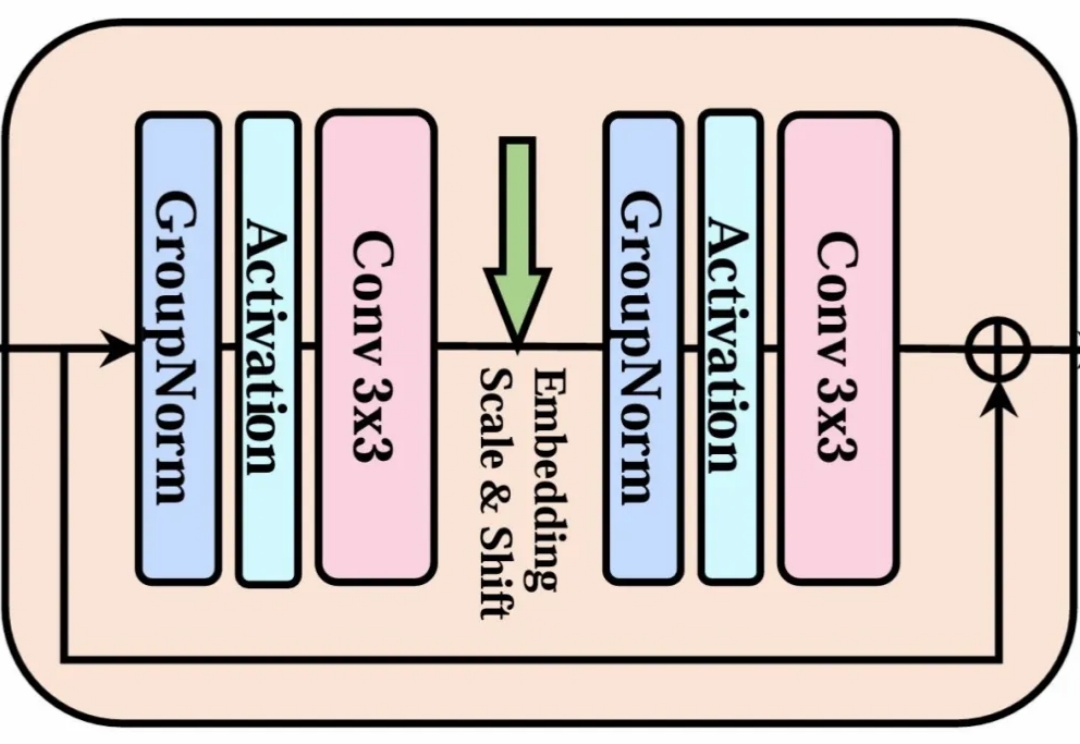
当整个 AI 视觉生成领域都在 Transformer 架构上「卷生卷死」时,一项来自北大、北邮和华为的最新研究却反其道而行之,重新审视了深度学习中最基础、最经典的模块——3x3 卷积。
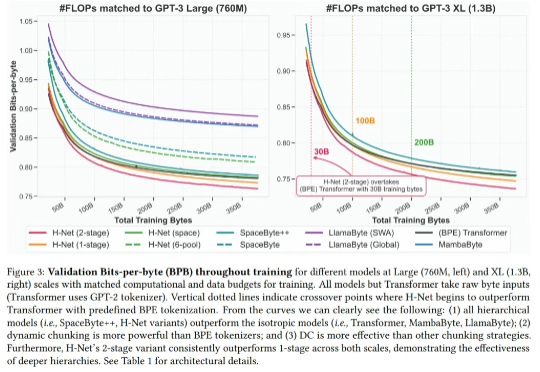
最近,Mamba 作者之一 Albert Gu 又发新研究,他参与的一篇论文《 Dynamic Chunking for End-to-End Hierarchical Sequence Modeling 》提出了一个分层网络 H-Net,其用模型内部的动态分块过程取代 tokenization,从而自动发现和操作有意义的数据单元。

「停止研究 RL 吧,研究者更应该将精力投入到产品开发中,真正推动人工智能大规模发展的关键技术是互联网,而不是像 Transformer 这样的模型架构。」

「Tokenization(分词)是 Transformer 模型为弥补自身缺陷不得不戴上的枷锁。」
Mamba一作最新大发长文! 主题只有一个,即探讨两种主流序列模型——状态空间模型(SSMs)和Transformer模型的权衡之术。