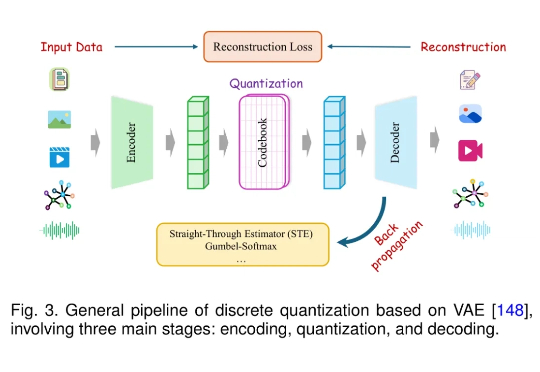
Discrete Tokenization:多模态大模型的关键基石,首个系统化综述发布
Discrete Tokenization:多模态大模型的关键基石,首个系统化综述发布近年来,大语言模型(LLM)在语言理解、生成和泛化方面取得了突破性进展,并广泛应用于各种文本任务。随着研究的深入,人们开始关注将 LLM 的能力扩展至非文本模态,例如图像、音频、视频、图结构、推荐系统等。
来自主题: AI技术研报
7997 点击 2025-08-06 12:18
 搜索
搜索
近年来,大语言模型(LLM)在语言理解、生成和泛化方面取得了突破性进展,并广泛应用于各种文本任务。随着研究的深入,人们开始关注将 LLM 的能力扩展至非文本模态,例如图像、音频、视频、图结构、推荐系统等。
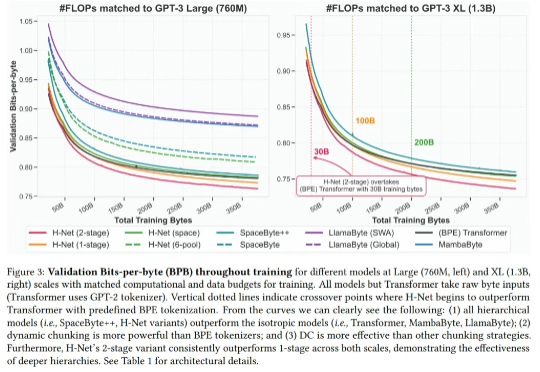
最近,Mamba 作者之一 Albert Gu 又发新研究,他参与的一篇论文《 Dynamic Chunking for End-to-End Hierarchical Sequence Modeling 》提出了一个分层网络 H-Net,其用模型内部的动态分块过程取代 tokenization,从而自动发现和操作有意义的数据单元。

「Tokenization(分词)是 Transformer 模型为弥补自身缺陷不得不戴上的枷锁。」
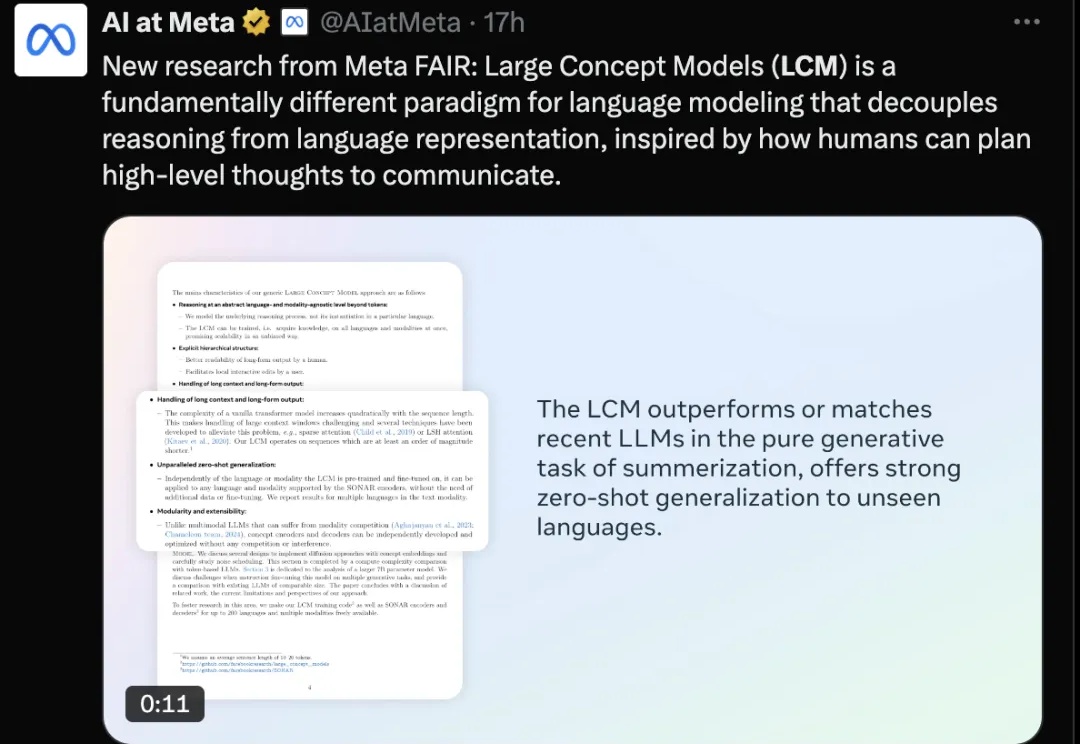
Meta提出大概念模型,抛弃token,采用更高级别的「概念」在句子嵌入空间上建模,彻底摆脱语言和模态对模型的制约。
2019 年问世的 GPT-2,其 tokenizer 使用了 BPE 算法,这种算法至今仍很常见,但这种方式是最优的吗?来自 HuggingFace 的一篇文章给出了解释。

BLT 在许多基准测试中超越了基于 token 的架构。
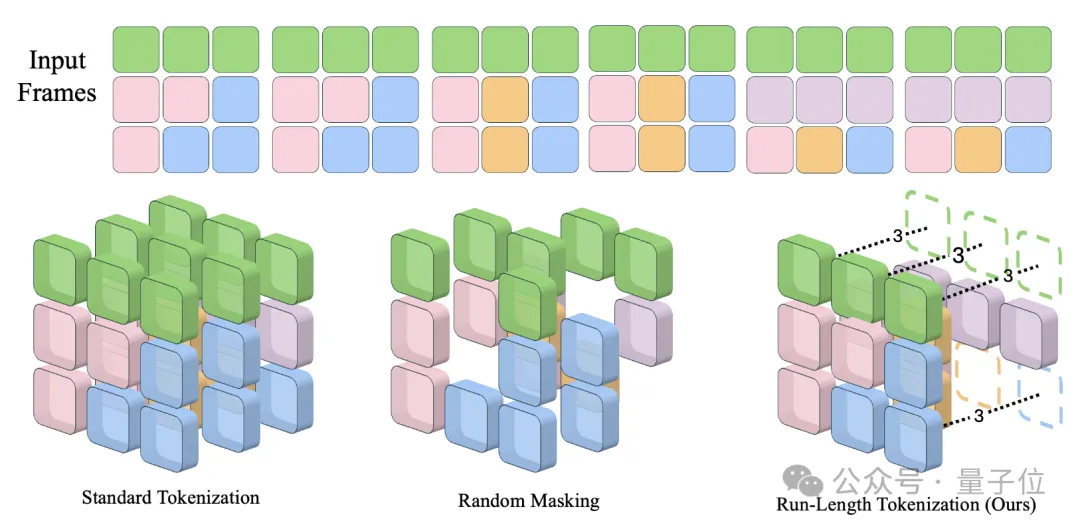
卡内基梅隆大学提出了视频生成模型加速方法Run-Length Tokenization(RLT),被NeurIPS 2024选为Spotlight论文。 在精度几乎没有损失的前提下,RLT可以让模型训练和推理速度双双提升。

在生成式模型的迅速发展中,Image Tokenization 扮演着一个很重要的角色,例如Diffusion依赖的VAE或者是Transformer依赖的VQGAN。这些Tokenizers会将图像编码至一个更为紧凑的隐空间(latent space),使得生成高分辨率图像更有效率。

关于大模型分词(tokenization),大神Karpathy刚刚推荐了一篇必读新论文。