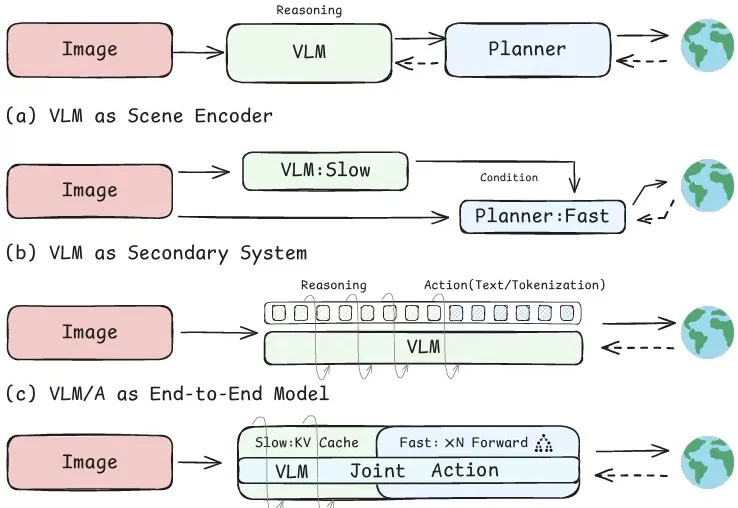
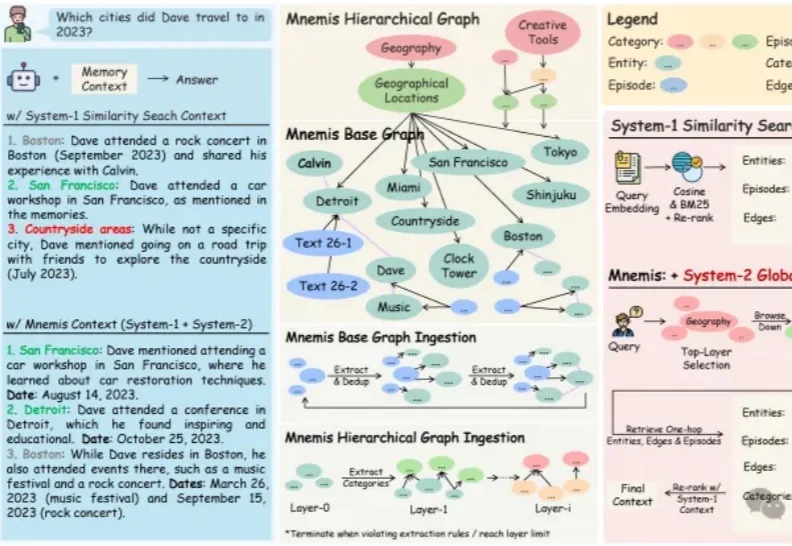
大模型搜索总偷懒?IQuest等联合推出FORT,30B开源搜索Agent刷新同规模SOTA
大模型搜索总偷懒?IQuest等联合推出FORT,30B开源搜索Agent刷新同规模SOTA来自至知创新研究院(IQuest Research)、中国人民大学高瓴人工智能学院、KAUST等机构的研究团队提出了FORT,一个面向Deep Search Agent的shortcut-resistant training-data synthesis framework。
来自主题: AI技术研报
8697 点击 2026-06-27 11:27