
AI Agent 摩尔定律:每7个月能力翻倍,带来软件智能大爆炸
AI Agent 摩尔定律:每7个月能力翻倍,带来软件智能大爆炸AI Agent 领域也存在 scaling law,甚至还在加速。
来自主题: AI技术研报
9996 点击 2025-04-12 14:11
 搜索
搜索
AI Agent 领域也存在 scaling law,甚至还在加速。
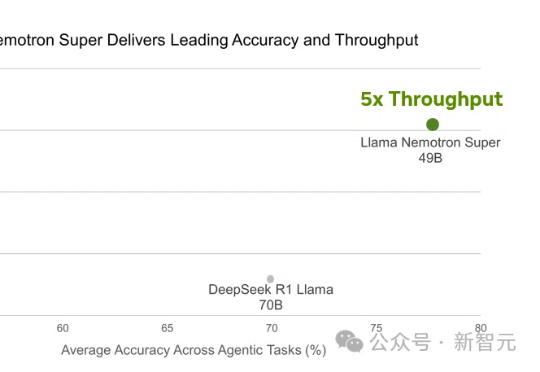
Llama 4刚出世就被碾压!英伟达强势开源Llama Nemotron-253B推理模型,在数学编码、科学问答中准确率登顶,甚至以一半参数媲美DeepSeek R1,吞吐量暴涨4倍。关键秘诀,就在于团队采用的测试时Scaling。

刚刚,一位AI公司CEO细细扒皮了关于Llama 4的五大疑点。甚至有圈内人表示,Llama 4证明Scaling已经结束了,LLM并不能可靠推理。但更可怕的事,就是全球的AI进步恐将彻底停滞。
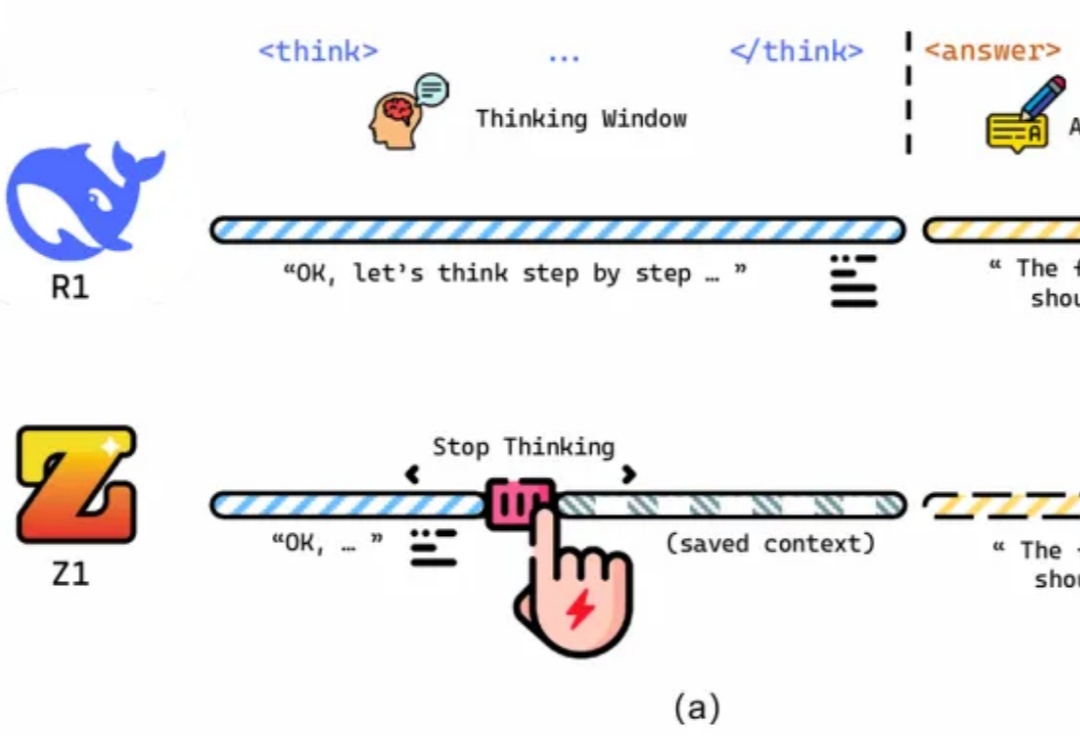
推理性能提升的同时,还大大减少Token消耗!
近年来,大语言模型(LLM)的性能提升逐渐从训练时规模扩展转向推理阶段的优化,这一趋势催生了「测试时扩展(test-time scaling)」的研究热潮。

DeepSeek新论文来了!在清华研究者共同发布的研究中,他们发现了奖励模型推理时Scaling的全新方法。DeepSeek R2,果然近了。
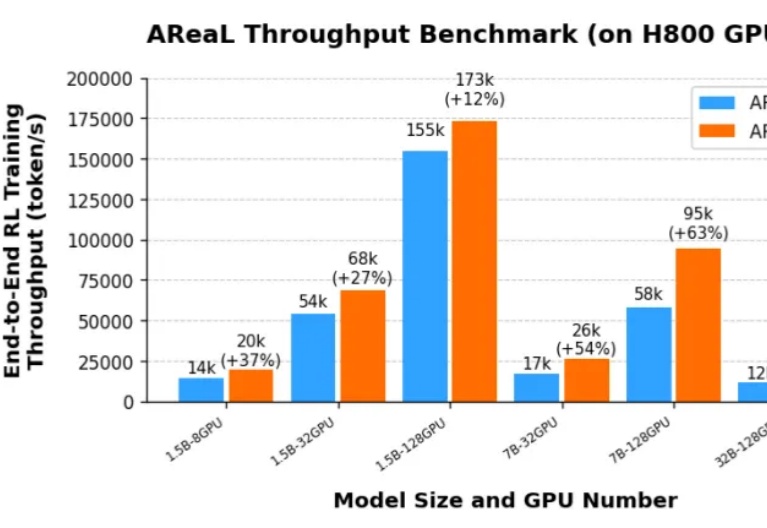
由于 DeepSeek R1 和 OpenAI o1 等推理模型(LRM,Large Reasoning Model)带来了新的 post-training scaling law,强化学习(RL,Reinforcement Learning)成为了大语言模型能力提升的新引擎。然而,针对大语言模型的大规模强化学习训练门槛一直很高:
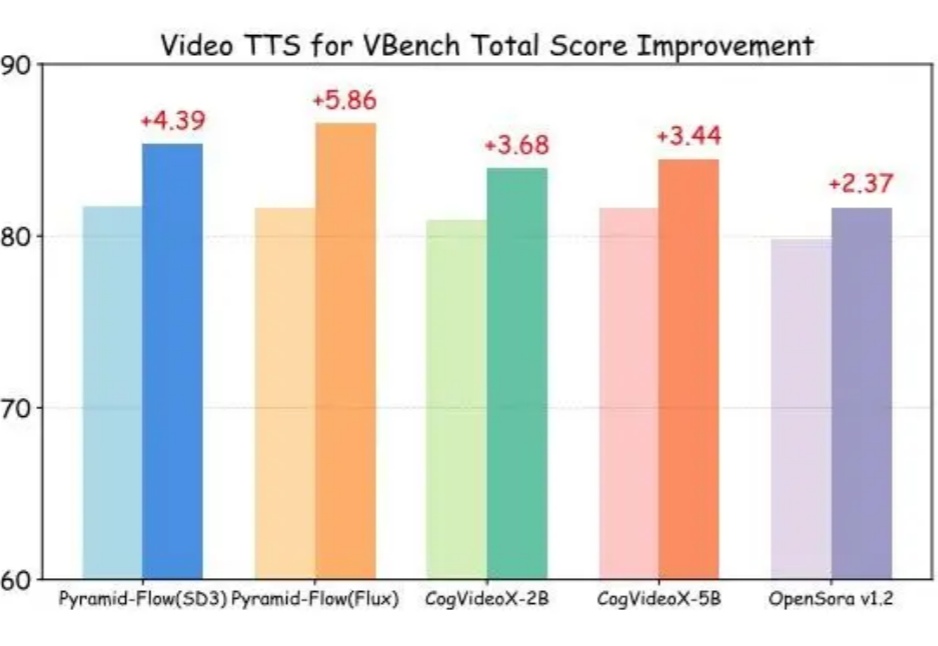
视频作为包含大量时空信息和语义的媒介,对于 AI 理解、模拟现实世界至关重要。视频生成作为生成式 AI 的一个重要方向,其性能目前主要通过增大基础模型的参数量和预训练数据实现提升,更大的模型是更好表现的基础,但同时也意味着更苛刻的计算资源需求。

在GTC2025大会上,NVIDIA依旧延续着“算力的故事”。如果AI的发展依旧遵循着scaling law(规模定律),那么这个故事还能继续讲下去。

事关路由LLM(Routing LLM),一项截至目前最全面的研究,来了——