突破大模型推理瓶颈!首篇「Test-Time Scaling」全景综述,深入剖析AI深思之道
突破大模型推理瓶颈!首篇「Test-Time Scaling」全景综述,深入剖析AI深思之道当训练成本飙升、数据枯竭,如何继续激发大模型潜能?
来自主题: AI技术研报
9329 点击 2025-05-13 14:48
 搜索
搜索
当训练成本飙升、数据枯竭,如何继续激发大模型潜能?
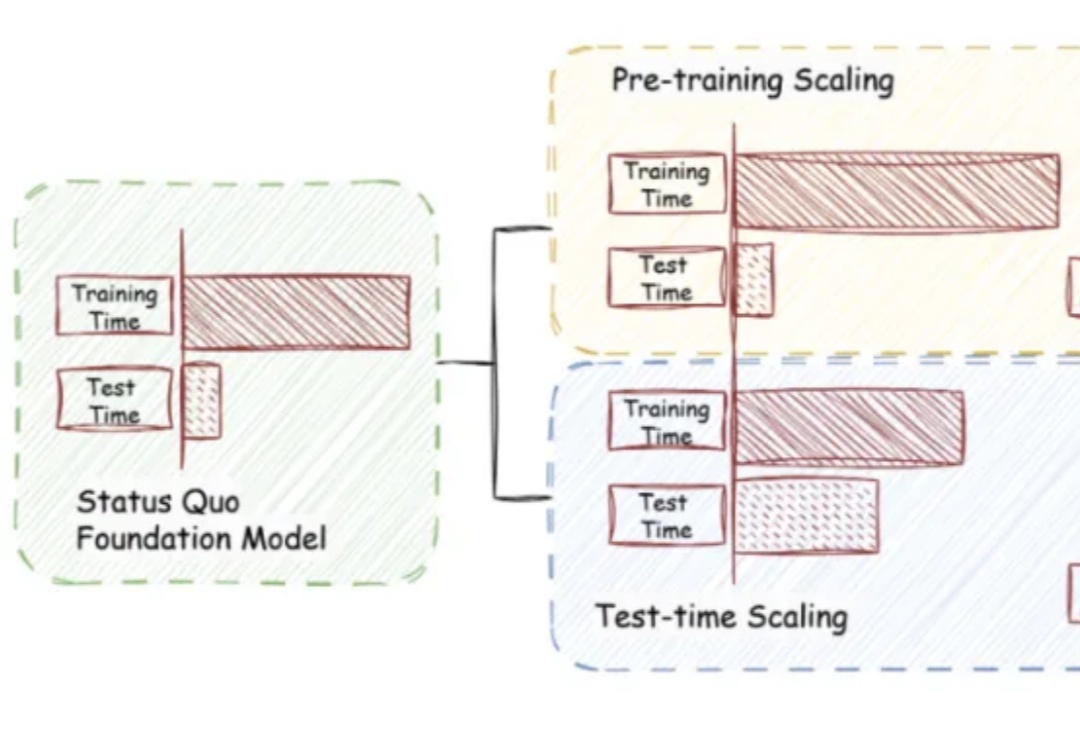
当以端到端黑盒训练为代表的深度学习深陷低效 Scaling Law 而无法自拔时,我们是否可以回到起点重看模型表征本身——究竟什么才是一个人工智能模型的「表征质量」或者「泛化性」?我们真的只有通过海量的测试数据才能抓住泛化性的本质吗?或者说,能否在数学上找到一个定理,直接从表征逻辑复杂度本身就给出一个对模型泛化性的先验的判断呢?

Jim Fan,英伟达机器人部门主管和杰出科学家、GEAR 实验室联合领导人、OpenAI 的首位实习生,最近在红杉资本主办的 AI Ascent 上做了一场 17 分钟的演讲
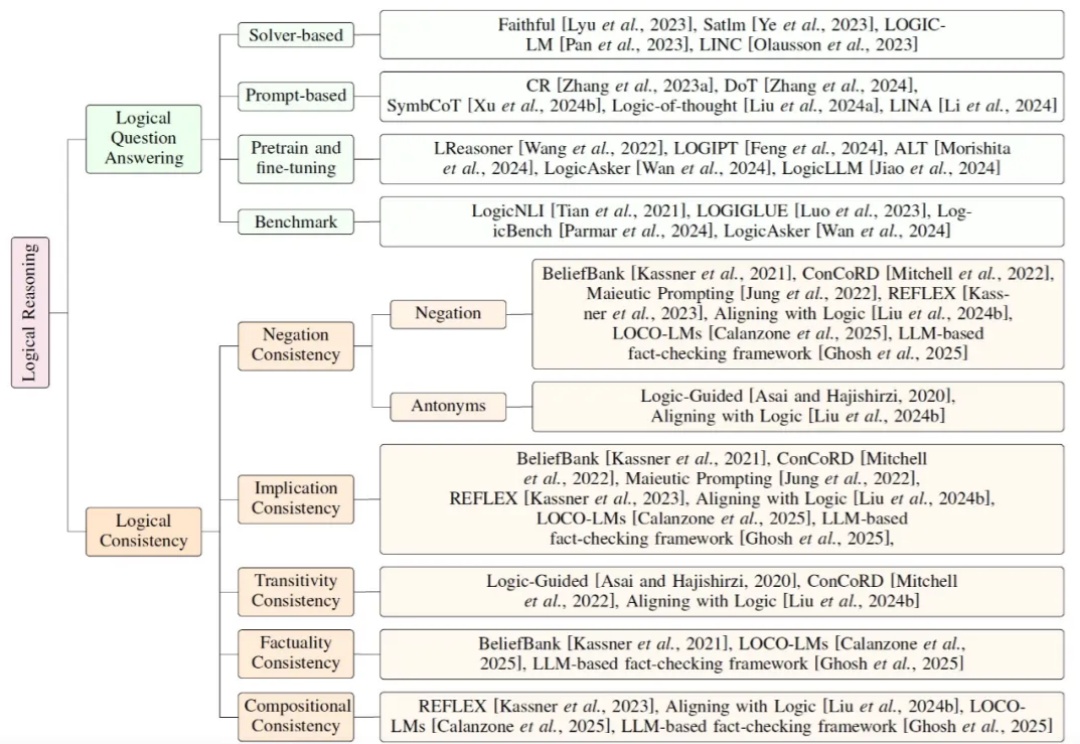
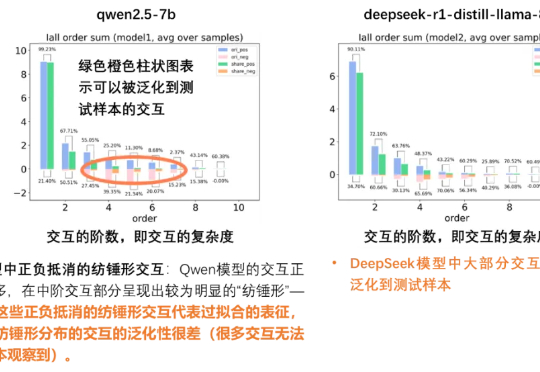
当前大模型研究正逐步从依赖扩展定律(Scaling Law)的预训练,转向聚焦推理能力的后训练。鉴于符号逻辑推理的有效性与普遍性,提升大模型的逻辑推理能力成为解决幻觉问题的关键途径。

研究揭示早融合架构在低计算预算下表现更优,训练效率更高。混合专家(MoE)技术让模型动态适应不同模态,显著提升性能,堪称多模态模型的秘密武器。

现如今,微调和强化学习等后训练技术已经成为提升 LLM 能力的重要关键。
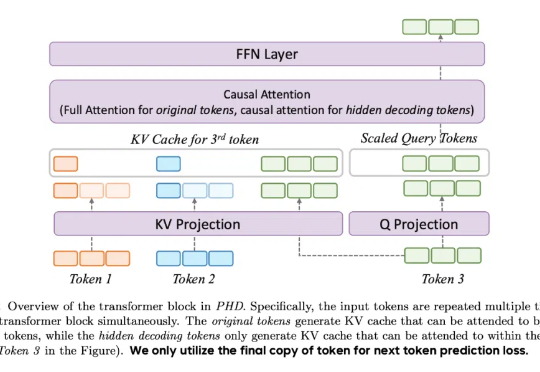
最近,DeepSeek-R1 和 OpenAI o1/03 等推理大模型在后训练阶段探索了长度扩展(length scaling),通过强化学习(比如 PPO、GPRO)训练模型生成很长的推理链(CoT),并在奥数等高难度推理任务上取得了显著的效果提升。
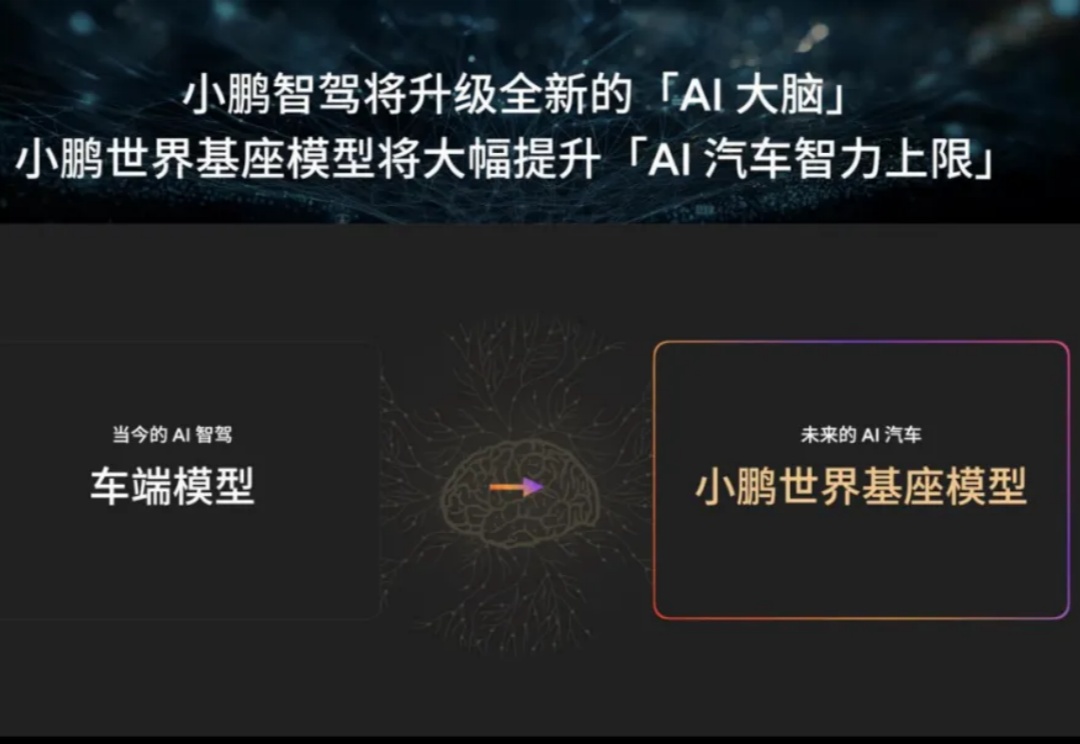
最近一段时间,各家新势力都在角力部署端到端的智能驾驶系统。
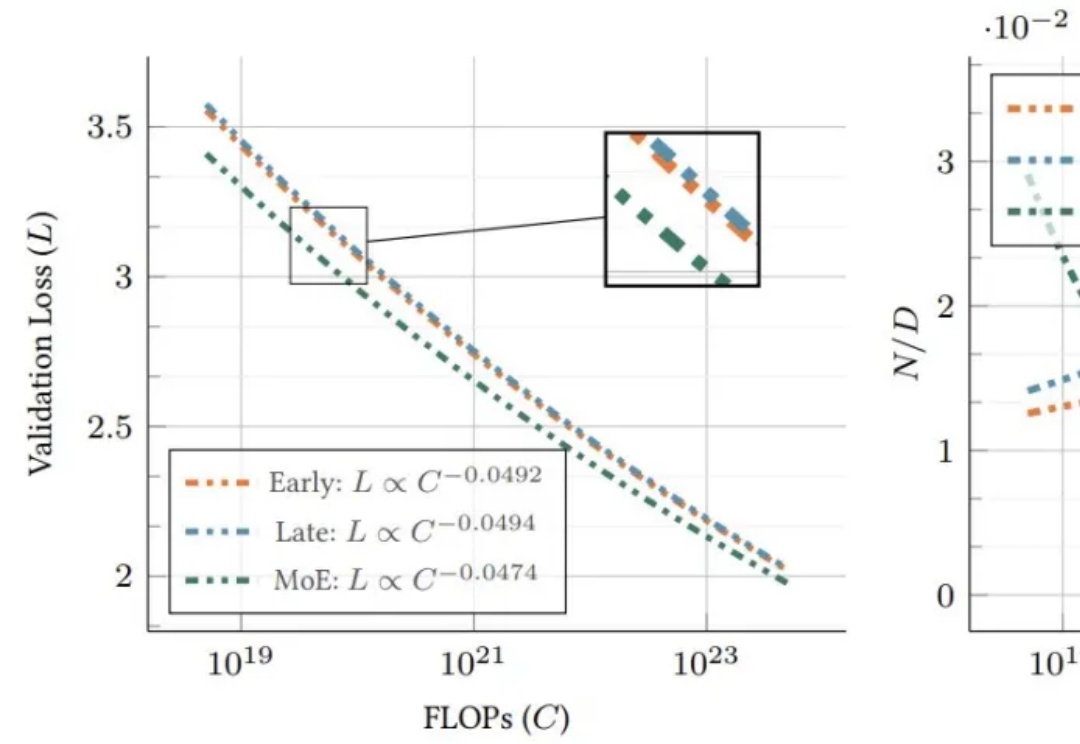
让大模型进入多模态模式,从而能够有效感知世界,是最近 AI 领域里人们一直的探索目标。
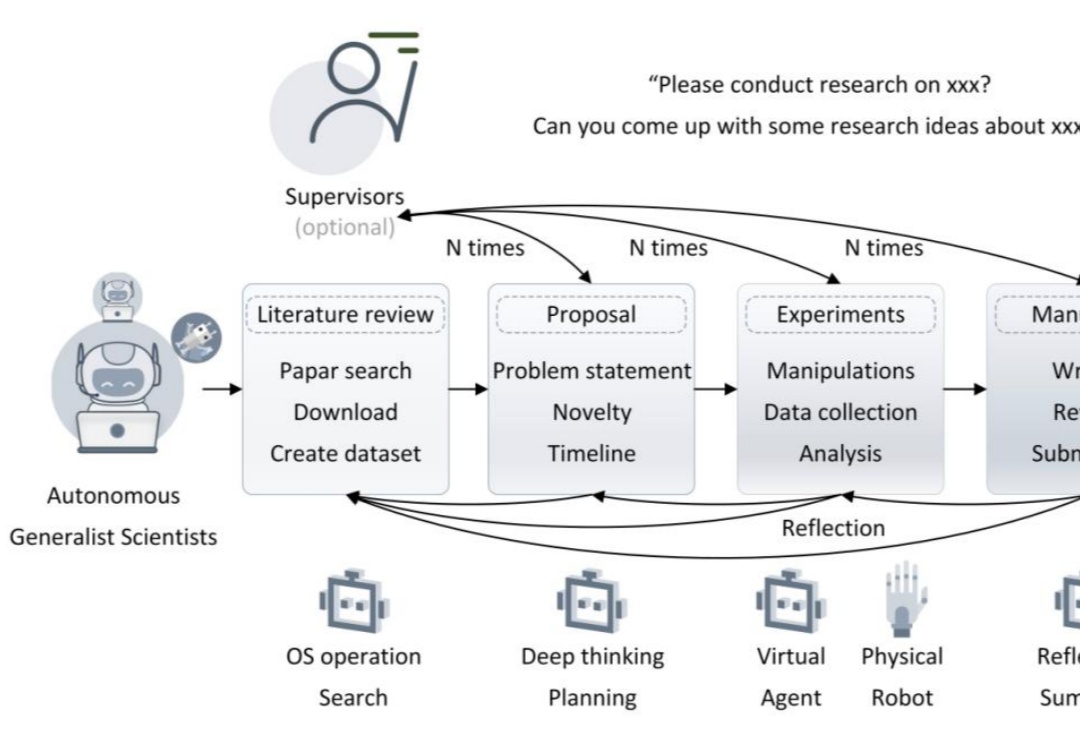
自主通才科学家的 5 个层级。