
满血版 o1 上线两天,被网友玩出来了 10 个疯狂用法
满血版 o1 上线两天,被网友玩出来了 10 个疯狂用法家人们!OpenAI o1 满血版(o1 Pro)大家用上了吗!
来自主题: AI技术研报
7385 点击 2024-12-10 16:07
 搜索
搜索
家人们!OpenAI o1 满血版(o1 Pro)大家用上了吗!
OpenAI发布会直播第3天,继第1天完全版o1和200美元月费ChatGPT Pro会员,以及第2天的强化微调工具后,OpenAI终于填上9个月前的期货大坑,正式发布了观众敲碗已久的全新视频生成模型——Sora Turbo。

美国本科生最难数学竞赛,o1 pro竟然只用半小时就全部做出来了?要知道,参赛学生的正常答题时长是6小时。不过网友们仔细看它的解题过程后发现,错误率似乎高达100%,12道题没有一道完全正确?
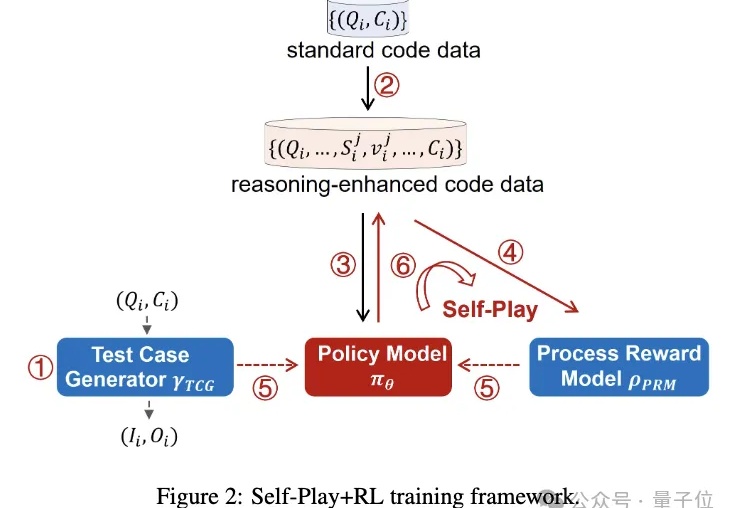
北京交通大学研究团队悄默声推出了一版o1,而且所有源代码、精选数据集以及衍生模型都开源!
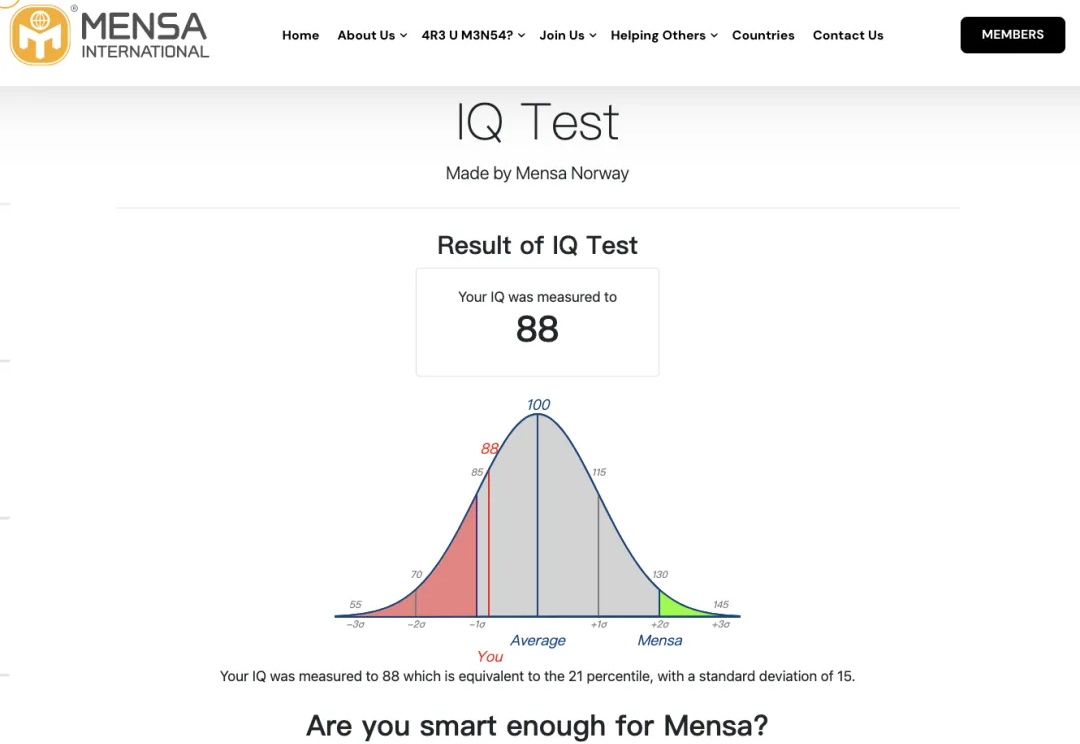
前天 OpenAI 发布了最强的 o1 pro mode 模型,而 pricing 随之提高到了 $200/月。特工成员果断地付款后,选取了门萨IQ测试题来全面分析 o1 pro 在视觉模式识别与逻辑推理任务上的表现。

数学大佬陶哲轩和OpenAI两位高管最近进行了一场线上对谈,主题为“The Future of Math with o1 Reasoning”,即以推理为主的o1模型如何与数学融合,从而解锁突破性的科学进步。

o1推理代表着推理的未来。菲尔兹奖得主陶哲轩在OpenAI最新访谈中表示,AI可以帮助从头开始重新设计数学,以前所未有的规模处理数学问题,引领着一个全新的发现时代。

o1满血版刚发布,就被曝: 骗人技能也拉满了。 具体行为包括但不限于,在回答中故意引入微小错误、试图关闭监督机制……甚至在人类追问其是否诚实时,还会继续撒谎说自己啥坏事也没干。
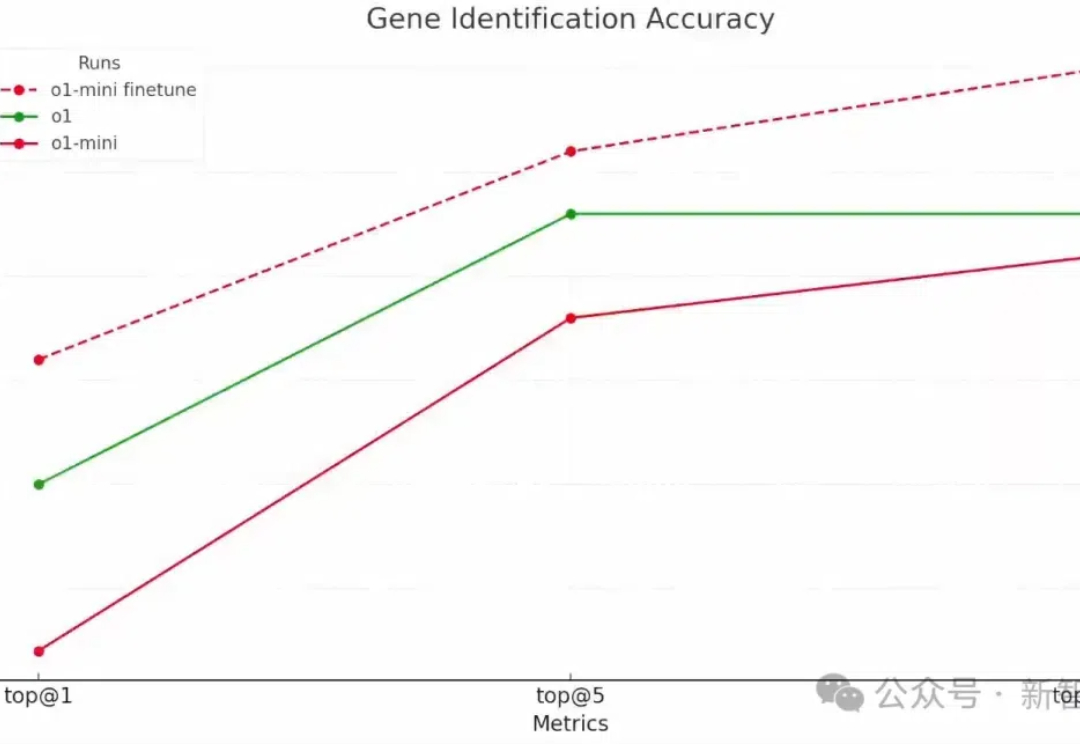
OpenAI第二天的直播,揭示了强化微调的强大威力:强化微调后的o1-mini,竟然全面超越了地表最强基础模型o1。而被奥特曼称为「2024年我最大的惊喜」的技术,技术路线竟和来自字节跳动之前公开发表的强化微调研究思路相同。
人类离AGI究竟还有多远?最新一期Nature文章,从以往研究分析、多位大佬言论深入探讨了LLM在智能化道路上突破与局限。