当做应用成为共识,大模型公司拿出了更多弹药
当做应用成为共识,大模型公司拿出了更多弹药OpenAI连续12个工作日的直播继续进行,完全版的o1,跳票很久的Sora和GPT-4o的高级语音模式,最新的ChatGPTProjects功能纷纷上线,其中还夹杂着一些关于AGI的符号性植入,仿佛在暗示这场马拉松式新品发布的压轴大戏会与AGI密切相关。
来自主题: AI资讯
8666 点击 2024-12-17 09:25
 搜索
搜索
OpenAI连续12个工作日的直播继续进行,完全版的o1,跳票很久的Sora和GPT-4o的高级语音模式,最新的ChatGPTProjects功能纷纷上线,其中还夹杂着一些关于AGI的符号性植入,仿佛在暗示这场马拉松式新品发布的压轴大戏会与AGI密切相关。
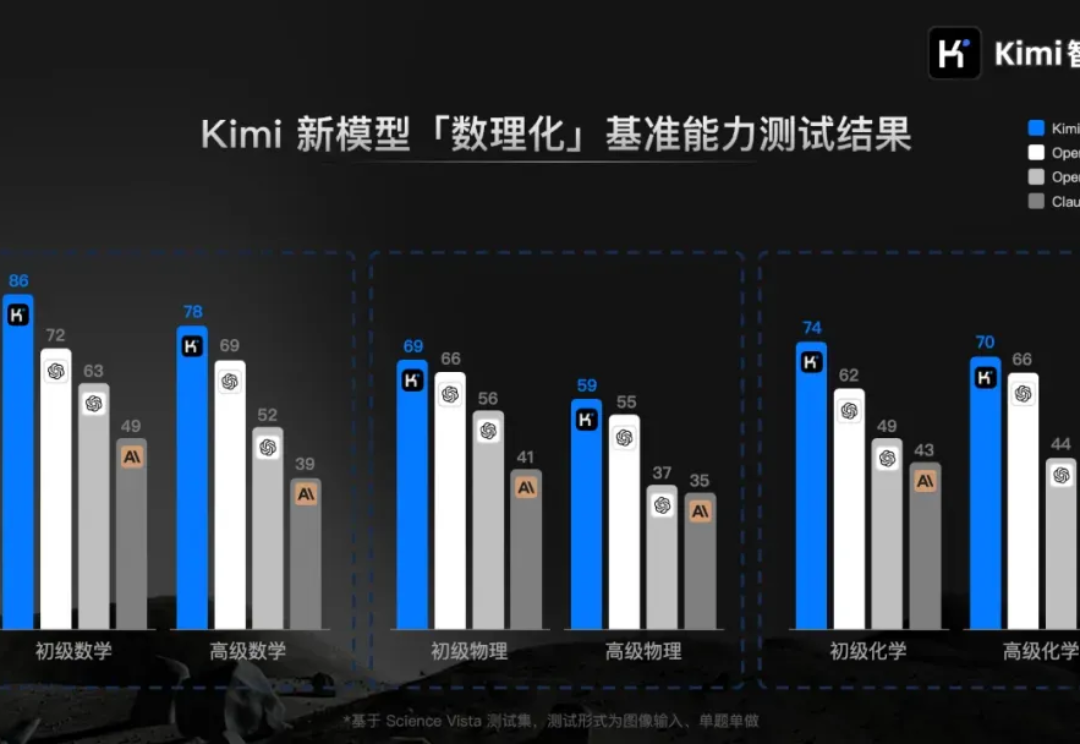
国产大模型,正在引领 AI 技术新方向。 今天上午,月之暗面 Kimi 正式发布了视觉思考模型 k1,并已经上线了最新版的网页版以及安卓和 iOS APP。

全网独一份o1 pro架构爆料来了!首创自洽性机制打破推理极限,「草莓训练」系统首次揭秘。更令人震惊的是,OpenAI和Anthropic自留Orion、Claude 3.5超大杯,并不是内部失败了,而是它们成为数据生成的秘密武器。
OpenAI 放出了 o1 Pro、GPT-4o 高级语音、GPTCanavas,就跟孔雀开屏一样 ~ 谷歌最近的大动作是发布了 Gemini 2.0 嘛!2.0 比 1.5 版本快一倍,而且是原生的多模态大模型,能输入和生成语言、声音、图片、视频等。

嘿!最近 AI 圈都在关注 OpenAI 的连续 12 场直播。就在直播开播同一天,OpenAI 也出炉了 o1 系统卡(o1 System Card),今天咱们就来啃啃这块硬骨头。

大语言模型(LLMs)通过更多的推理展现出了更强的能力和可靠性,从思维链提示发展到了 OpenAI-o1 这样具有较强推理能力的模型。

昨天深夜,OpenAI彻底被谷歌狙击,震撼亮相的Gemini 2.0掀起智能体革命,原生多模态的多项惊人demo预示着:智能体时代,谷歌已经走在了最前面。

目前大语言模型(Large Language Models, LLMs)的推理能力备受关注。从思维链(Chain of Thought,CoT)技术提出,到以 o1 为代表的长思考模型发布,大模型正在展现出接近人类甚至领域专家的水平,其中数学推理是一个典型任务。

LLM 作为推理引擎,coding 是最好的应用场景:代码的逻辑比自然语言更清晰,执行的结果能由 AI 自动化验证。因此我们看到从 Sonnet 3.5 到 o1 pro,每一次模型能力的提升都会反映在 coding 能力的提升上,这一领域的应用进步就尤其显著。

2023年10月的某一天,在OpenAI的实验室里,一个被称为Q*的模型展现出了某种前所未有的能力。