
AI教育走出屏幕的第一步,是一台万元机器人
AI教育走出屏幕的第一步,是一台万元机器人当 AI 教育从屏幕走向物理世界,松延动力正用小布米、课程体系和「学校—机构—家庭」生态闭环,把 K12 机器人教育变成具身智能走进千家万户的第一站。
来自主题: AI资讯
8627 点击 2026-06-11 15:02
 搜索
搜索
当 AI 教育从屏幕走向物理世界,松延动力正用小布米、课程体系和「学校—机构—家庭」生态闭环,把 K12 机器人教育变成具身智能走进千家万户的第一站。

第一篇论文(白皮书)由 Google Quantum AI 发表。他们针对逻辑层面的 Shor 算法进行了优化,专门用于破解比特币和以太坊的签名。该算法在针对 256 位椭圆曲线 secp256k1 时,仅需约 1000 个逻辑量子比特即可运行。由于电路深度较低,一台快速的超导量子计算机可以在几分钟内恢复私钥。
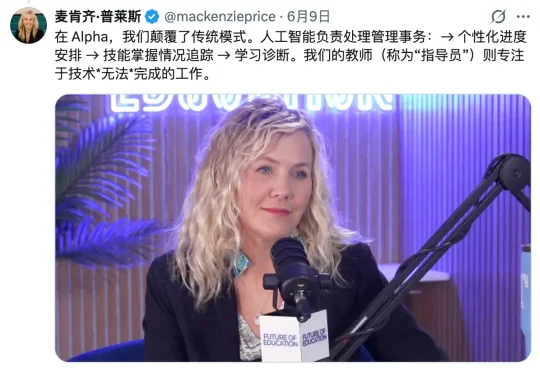
教授知识,AI 确实比人类教师更合适,但学生依旧需要好老师。国外的一所 K12 学校,Alpha School,正在尝试给出一种答案。它让我们有机会看清一件事:当 AI 接管了知识和传授,学校和家长还能提供什么?
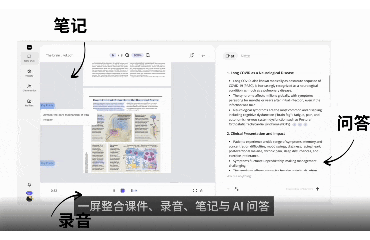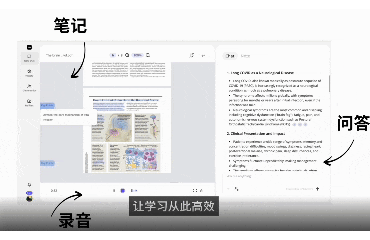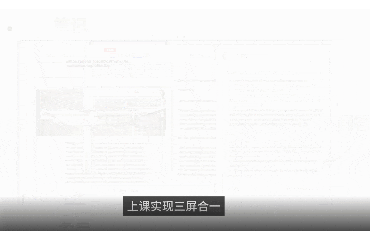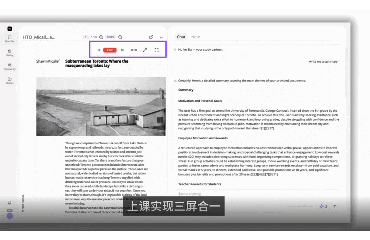
是否有哪个AI产品,让你觉得——它已经深入我们某个核心生活或工作场景,并让我们完全离不开?

AMD半年发起4笔AI收购。

美国K12学校也在通过AI助教进行技术升级。近日,美国AI教育科技初创公司Kira Learning面向K12学校推出AI智能体。

当前,强化学习(RL)在提升大语言模型(LLM)推理能力方面展现出巨大潜力。DeepSeek R1、Kimi K1.5 和 Qwen 3 等模型充分证明了 RL 在增强 LLM 复杂推理能力方面的有效性。
本文详细解读了 Kimi k1.5、OpenReasonerZero、DAPO 和 Dr. GRPO 四篇论文中的创新点,读完会对 GRPO 及其改进算法有更深的理解,进而启发构建推理模型的新思路。
近日,以色列宣布与以色列AI“数字化身”制作平台eSelf、以色列最大的K12教科书出版商CET(Center for Educational Technology)合作,在全国范围内铺开AI辅导。

当前,强化学习(RL)方法在最近模型的推理任务上取得了显著的改进,比如 DeepSeek-R1、Kimi K1.5,显示了将 RL 直接用于基础模型可以取得媲美 OpenAI o1 的性能不过,基于 RL 的后训练进展主要受限于自回归的大语言模型(LLM),它们通过从左到右的序列推理来运行。