
来一手Qwen-Image-2.0实测,好像还不错?!
来一手Qwen-Image-2.0实测,好像还不错?!BUBBLE 2026 — ISSUE #18 家人们, 马上没几天快过年了,明显各个厂商已经开始疯狂卷了。 上周到现在,让我们来算算有多少东西了, 5.3 Codex,4.6 Opus, 可灵3.0
来自主题: AI产品测评
11217 点击 2026-02-11 12:43
 搜索
搜索
BUBBLE 2026 — ISSUE #18 家人们, 马上没几天快过年了,明显各个厂商已经开始疯狂卷了。 上周到现在,让我们来算算有多少东西了, 5.3 Codex,4.6 Opus, 可灵3.0

今天,阿里巴巴发布了新一代图像生成基础模型Qwen-Image 2.0,这一模型支持长达一千个token的超长指令、2k分辨率,并采用了更轻量的模型架构,模型尺寸远小于Qwen-Image 2.0的20B,带来更快的推理速度。

xAI“迄今为止最强大的视频音频生成模型”Grok Imagine 1.0版本,正式全面上线。

啥,Flash这次这真没了?还是被AI干没的??
就在刚刚,据《南华早报》援引知情人士最新消息,智谱 AI 计划在未来两周内,也就是春节前发布其新旗舰模型 GLM-5。与此同时,MiniMax 也预计将于春节前发布 M2.2 模型,这是在原有 M2.1 基础上进行的小幅更新,重点提升编程能力。
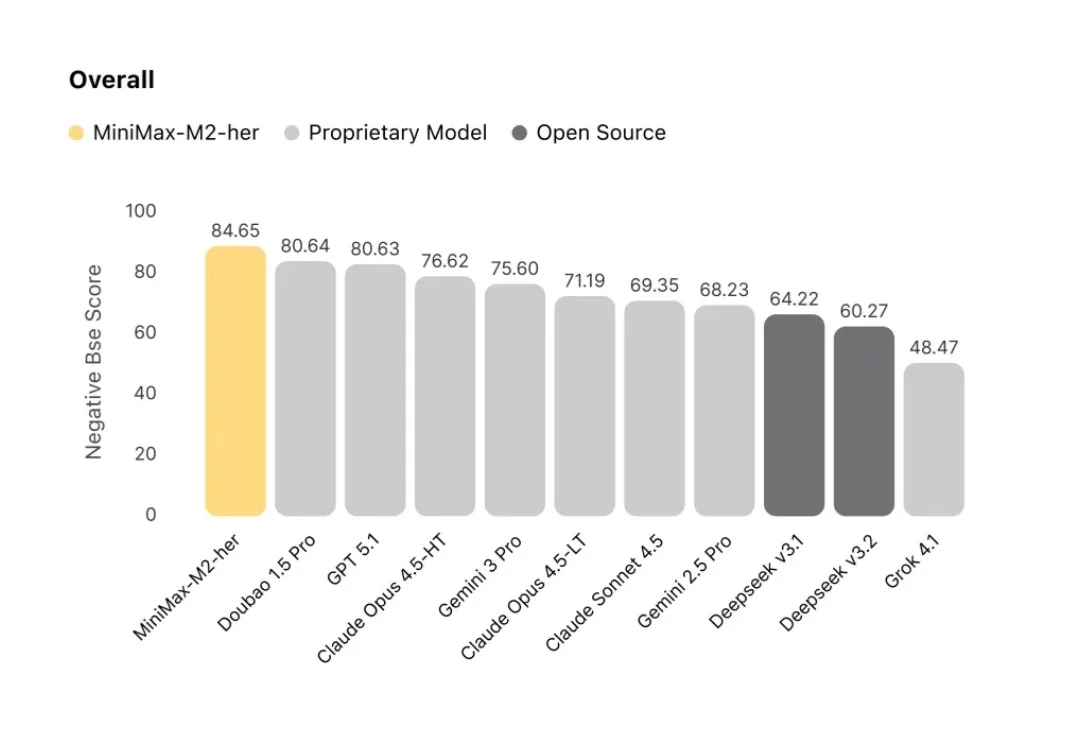
今天,我们分享 MiniMax-M2-her 背后的技术思考。M2-her 也是服务星野/Talkie的底层模型。

AI生成一张图片,你愿意等多久?在主流扩散模型还在迭代中反复“磨叽”、让用户盯着进度条发呆时,阿里智能引擎团队直接把进度条“拉爆”了——5秒钟,到手4张2K级高清大图。
Clawdbot痛失本名改叫Moltbot后,热度丝毫不减。

五个真实物理任务实测,PhysMaster 可推导、写码、数值验证。

今天,我们正式发布 MiniMax Music 2.5:全维度突破,指挥细节,定义真实。AI 音乐始终面对两个挑战:可控性与真实度。前者决定了创作者能否表达真实意图,后者决定了作品是否具备专业质感。