MiniMax 成为 Token 调用第一后,模型厂商必须面对的 AgentOS 现实
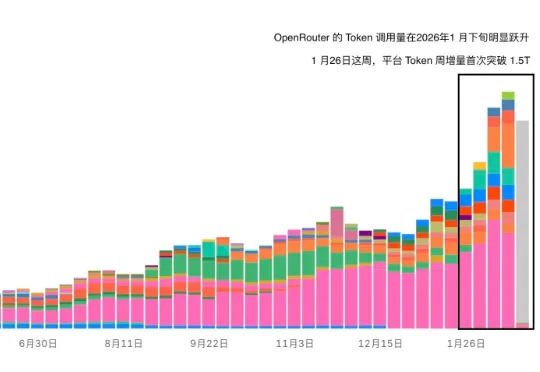
MiniMax 成为 Token 调用第一后,模型厂商必须面对的 AgentOS 现实作为目前全球最主要的大模型 API 聚合网关之一,OpenRouter 的 Token 调用量在 2026 年 1 月下旬出现了明显跃升。自 1 月 26 日当周开始,平台 Token 周增量首次突破 1.5T,这一幅度在过去的调用曲线中并不常见。时间点同样值得玩味——这一轮增长几乎与 OpenClaw 的迅速传播高度重合。人们开始发现,OpenClaw 简直就是 Token 碎纸机。
来自主题: AI资讯
9776 点击 2026-02-23 19:13