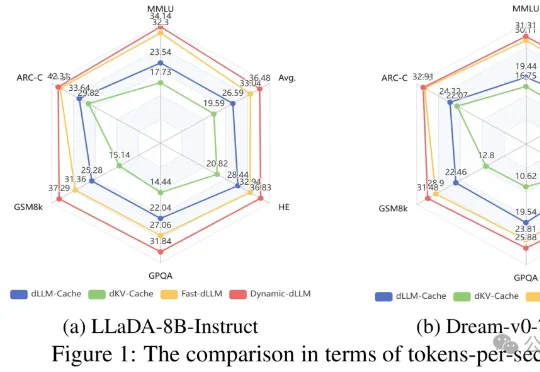
提速4.48倍!哈工大华为新框架让扩散大模型精度无损、推理起飞
提速4.48倍!哈工大华为新框架让扩散大模型精度无损、推理起飞文本生成这件事,扩散大语言模型(dLLMs)正展现出巨大的潜力。但与此同时,它也面临着严重的计算瓶颈——为此,哈工大(深圳)与华为、深圳河套学院的研究团队提出了一套免训练加速框架Dynamic-dLLM。
来自主题: AI技术研报
8512 点击 2026-05-08 14:05
 搜索
搜索
文本生成这件事,扩散大语言模型(dLLMs)正展现出巨大的潜力。但与此同时,它也面临着严重的计算瓶颈——为此,哈工大(深圳)与华为、深圳河套学院的研究团队提出了一套免训练加速框架Dynamic-dLLM。
在生成式 AI 的浪潮中,自回归(Autoregressive, AR)模型凭借其卓越的性能占据了统治地位。然而,其「从左到右」逐个预测 Token 的串行机制,天生限制了并行生成的可能性。
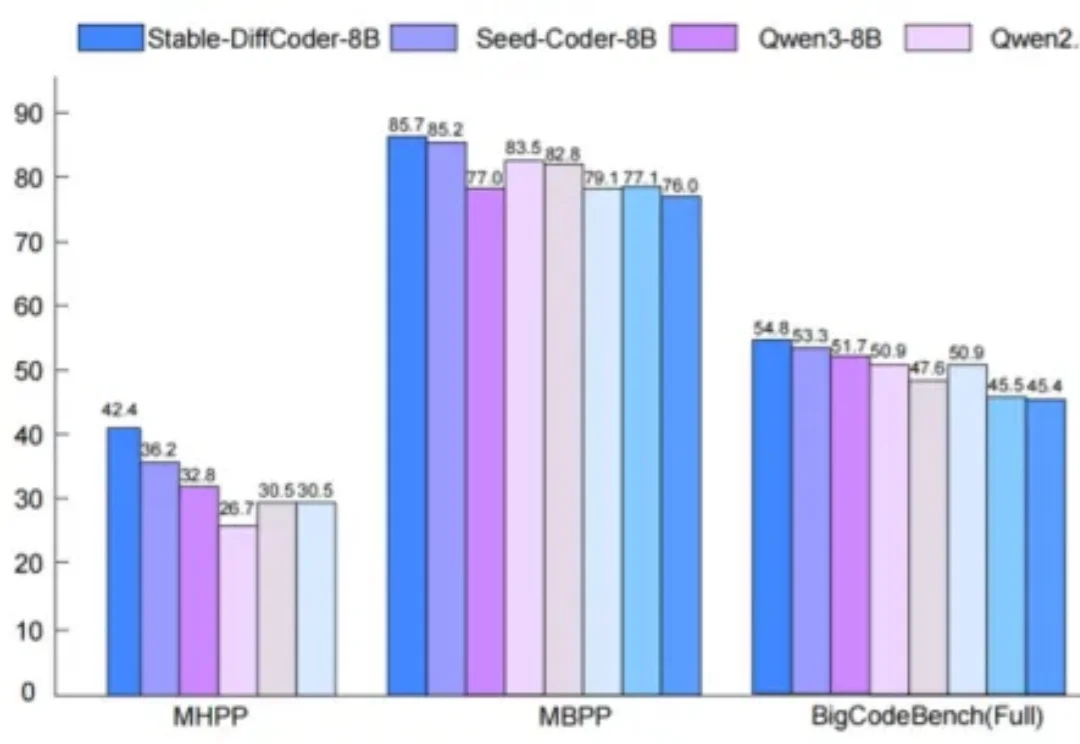
扩散语言模型(Diffusion Language Models, DLLMs)因其多种潜在的特性而备受关注,如能加速的非自回归并行生成特性,能直接起草编辑的特性,能数据增强的特性。然而,其模型能力往往落后于同等规模的强力自回归(AR)模型。
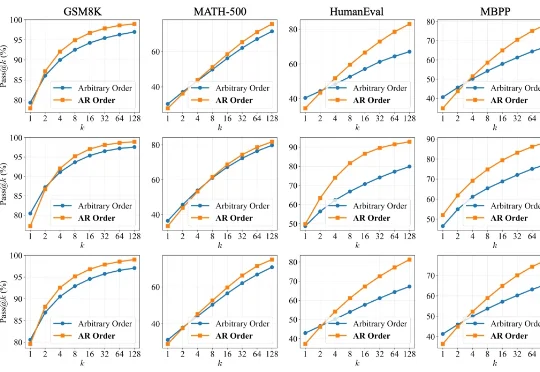
扩散语言模型(Diffusion LLMs, dLLMs)因支持「任意顺序生成」和并行解码而备受瞩目。直觉上,打破传统自回归(AR)「从左到右」的束缚,理应赋予模型更广阔的解空间,从而在数学、代码等复杂任务上解锁更强的推理潜力。
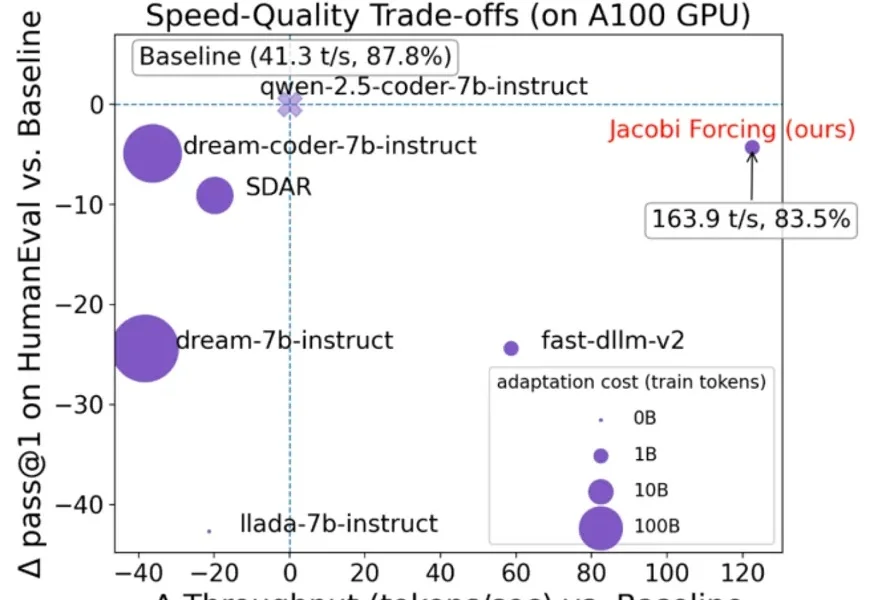
在大语言模型(LLM)落地应用中,推理速度始终是制约效率的核心瓶颈。传统自回归(AR)解码虽能保证生成质量,却需逐 token 串行计算,速度极为缓慢;扩散型 LLM(dLLMs)虽支持并行解码,却面
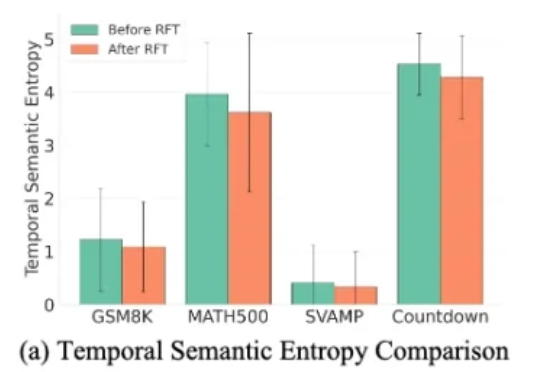
近年来,扩散大语言模型(Diffusion Large Language Models, dLLMs)正迅速崭露头角,成为文本生成领域的一股新势力。与传统自回归(Autoregressive, AR)模型从左到右逐字生成不同,dLLM 依托迭代去噪的生成机制,不仅能够一次性生成多个 token,还能在对话、推理、创作等任务中展现出独特的优势。
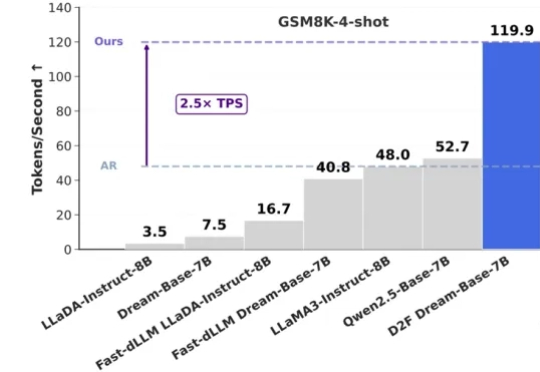
在大语言模型(LLMs)领域,自回归(AR)范式长期占据主导地位,但其逐 token 生成也带来了固有的推理效率瓶颈。此前,谷歌的 Gemini Diffusion 和字节的 Seed Diffusion 以每秒千余 Tokens 的惊人吞吐量,向业界展现了扩散大语言模型(dLLMs)在推理速度上的巨大潜力。
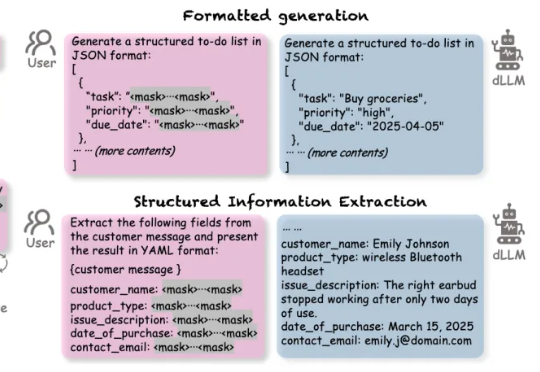
扩散语言模型(Diffusion-based LLMs,简称 dLLMs)以其并行解码、双向上下文建模、灵活插入masked token进行解码的特性,成为一个重要的发展方向。
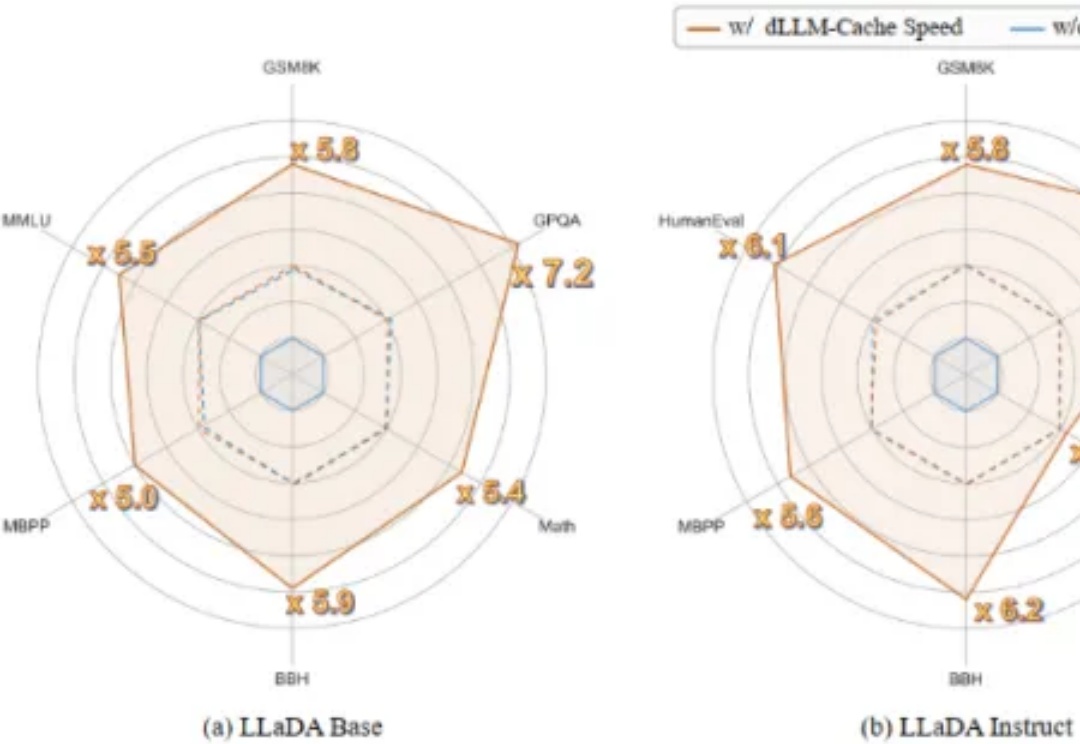
首个用于加速扩散式大语言模型(diffusion-based Large Language Models, 简称 dLLMs)推理过程的免训练方法。