最火VLA,看这一篇综述就够了
最火VLA,看这一篇综述就够了ICLR 2026爆火领域VLA(Vision-Language-Action,视觉-语言-动作)全面综述来了! 如果你还不了解VLA是什么,以及这个让机器人学者集体兴奋的领域进展如何,看这一篇就够了。
来自主题: AI技术研报
9119 点击 2025-10-31 14:59
 搜索
搜索
ICLR 2026爆火领域VLA(Vision-Language-Action,视觉-语言-动作)全面综述来了! 如果你还不了解VLA是什么,以及这个让机器人学者集体兴奋的领域进展如何,看这一篇就够了。
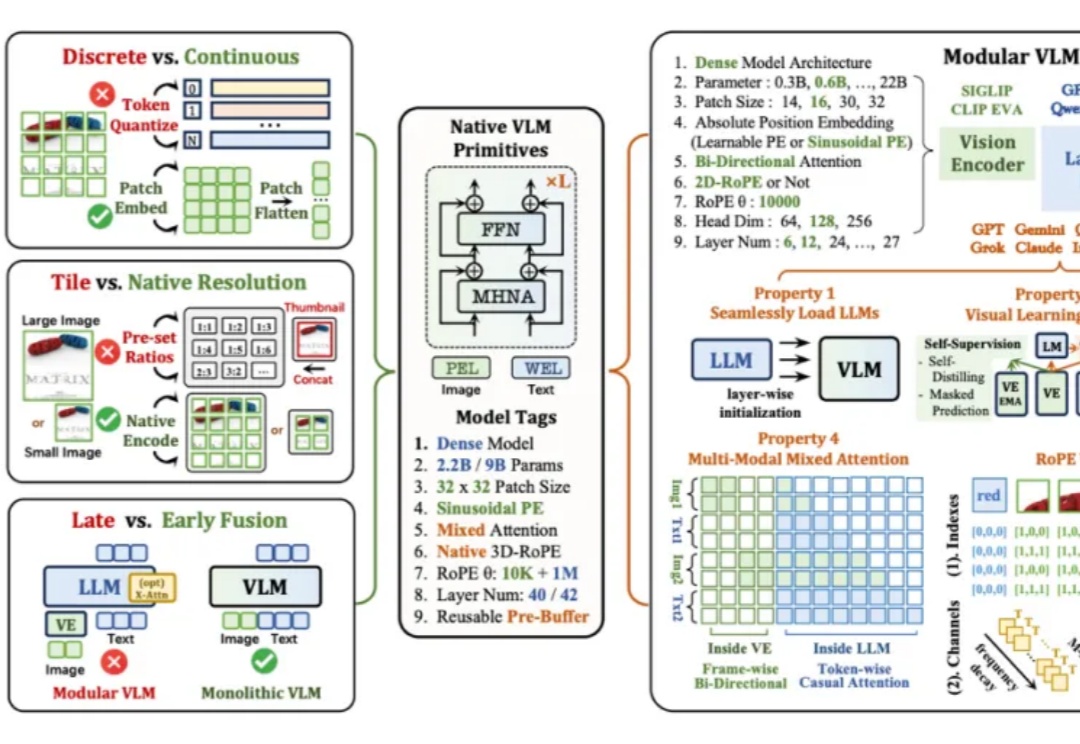
当下主流的视觉语言模型(Vision-Language Models, VLM),通常都采用这样一种设计思路:将预训练的视觉编码器与大语言模型通过投影层拼接起来。这种模块化架构成就了当前 VLM 的辉煌,但也带来了一系列新的问题——多阶段训练复杂、组件间语义对齐成本高,不同模块的扩展规律难以协调。
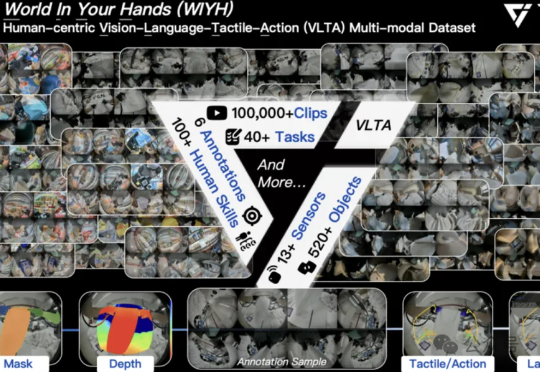
全球首个真实世界具身多模态数据集,它来了! 刚刚,它石智航发布全球首个大规模真实世界具身VLTA(Vision-Language-Tactile-Action)多模态数据集World In Your Hands(WIYH)。
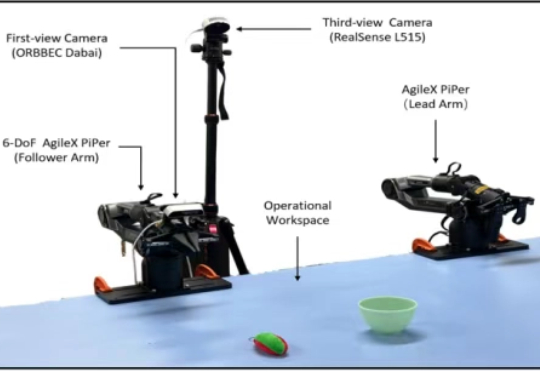
近年来,视觉 - 语言 - 动作(Vision-Language-Action, VLA)模型因其出色的多模态理解与泛化能力,已成为机器人领域的重要研究方向。尽管相关技术取得了显著进展,但在实际部署中,尤其是在高频率和精细操作等任务中,VLA 模型仍受到推理速度瓶颈的严重制约。
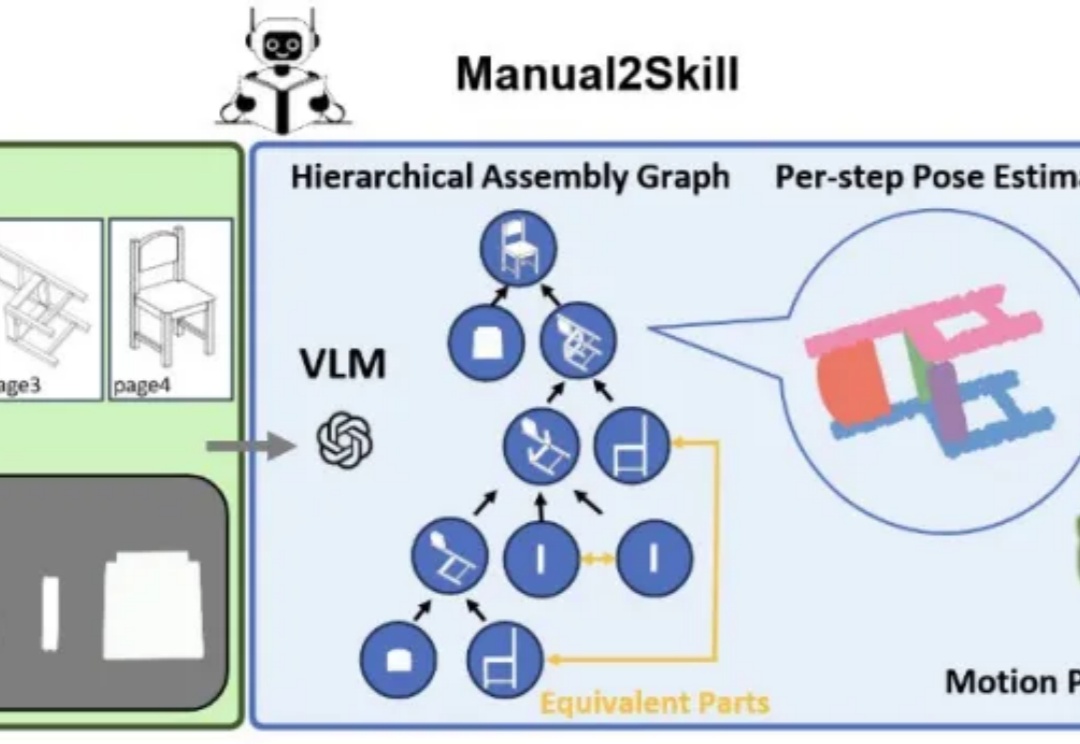
视觉语言模型(Vision-Language Models, VLMs),为真实环境中的机器人操作任务提供了极具潜力的解决方案。
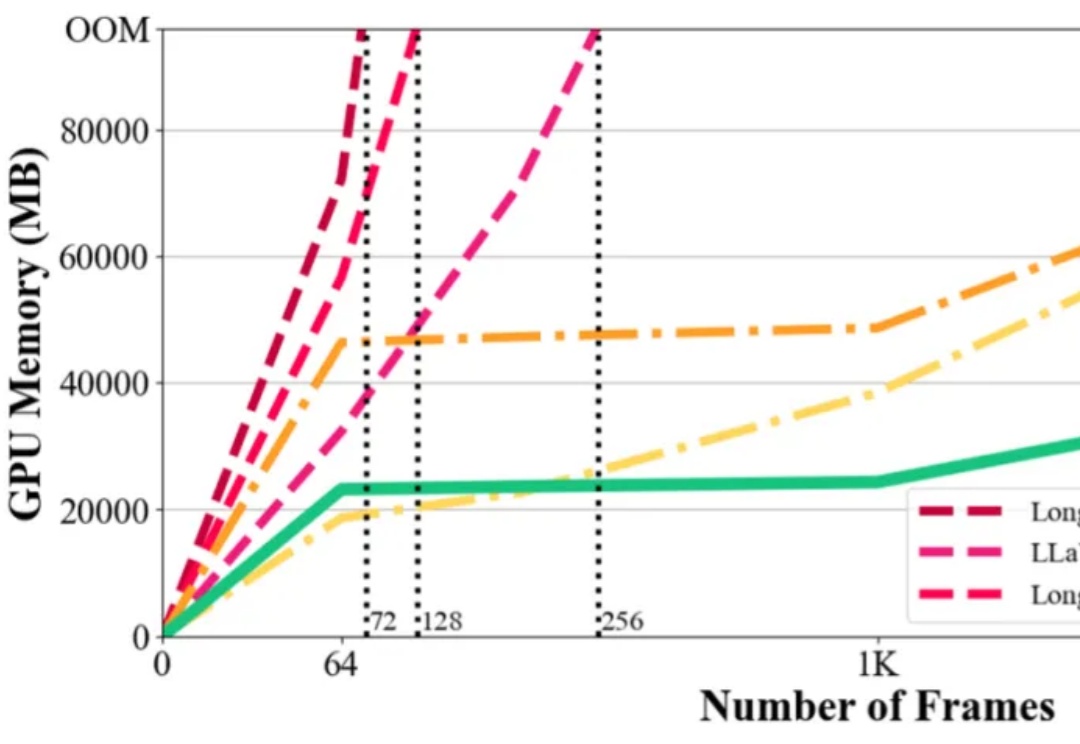
在视觉语言模型(Vision-Language Models,VLMs)取得突破性进展的当下,长视频理解的挑战显得愈发重要。以标准 24 帧率的标清视频为例,仅需数分钟即可产生逾百万的视觉 token,这已远超主流大语言模型 4K-128K 的上下文处理极限。
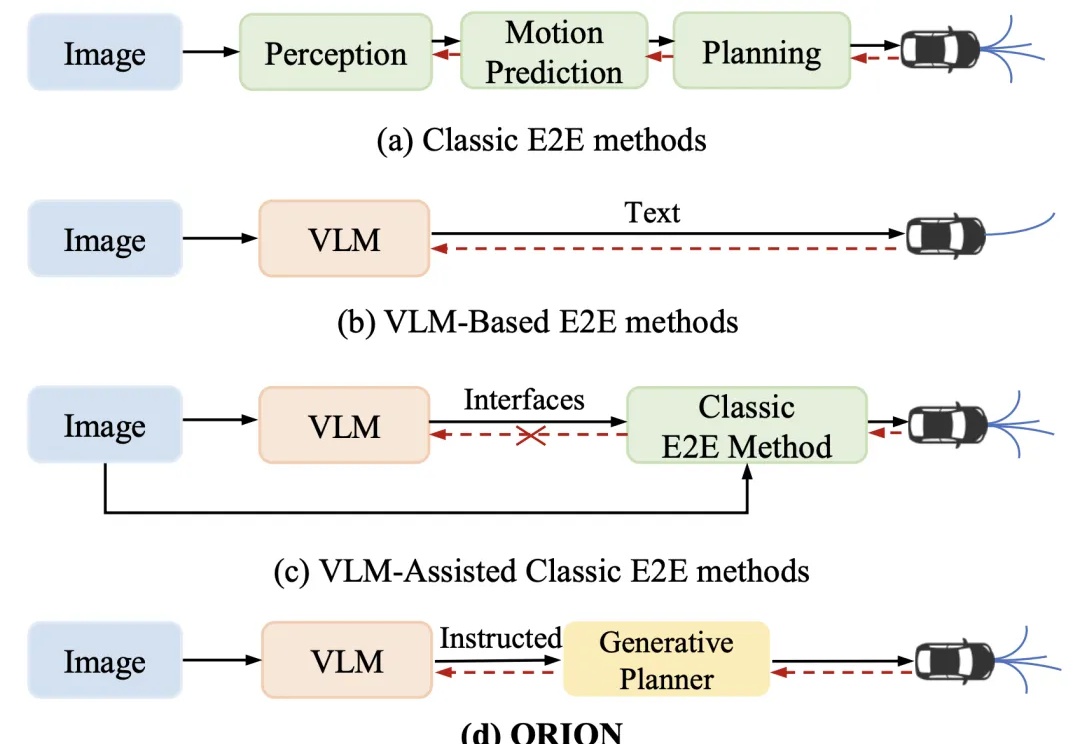
近年来,端到端(End-to-End,E2E)自动驾驶技术不断进步,但在复杂的闭环交互环境中,由于其因果推理能力有限,仍然难以做出准确决策。虽然视觉 - 语言大模型(Vision-Language Model,VLM)凭借其卓越的理解和推理能力,为端到端自动驾驶带来了新的希望,但现有方法在 VLM 的语义推理空间和纯数值轨迹的行动空间之间仍然存在巨大鸿沟。
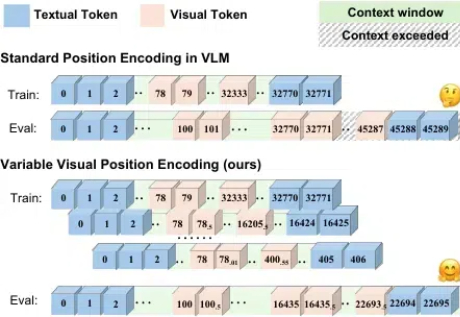
随着语言大模型的成功,视觉 - 语言多模态大模型 (Vision-Language Multimodal Models, 简写为 VLMs) 发展迅速,但在长上下文场景下表现却不尽如人意,这一问题严重制约了多模态模型在实际应用中的潜力。
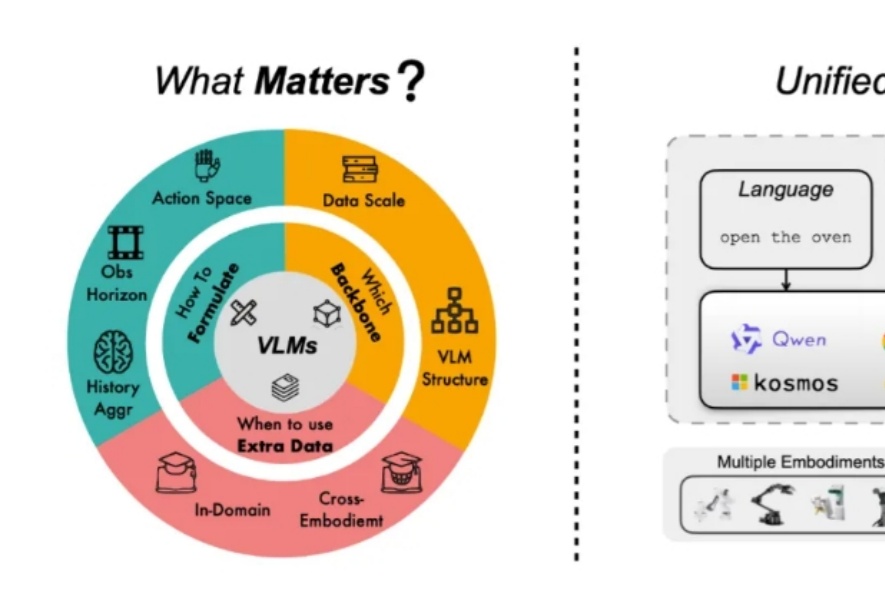
近年来,视觉语言基础模型(Vision Language Models, VLMs)大放异彩,在多模态理解和推理上展现出了超强能力。现在,更加酷炫的视觉语言动作模型(Vision-Language-Action Models, VLAs)来了!通过为 VLMs 加上动作预测模块,VLAs 不仅能 “看” 懂和 “说” 清,还能 “动” 起来,为机器人领域开启了新玩法!
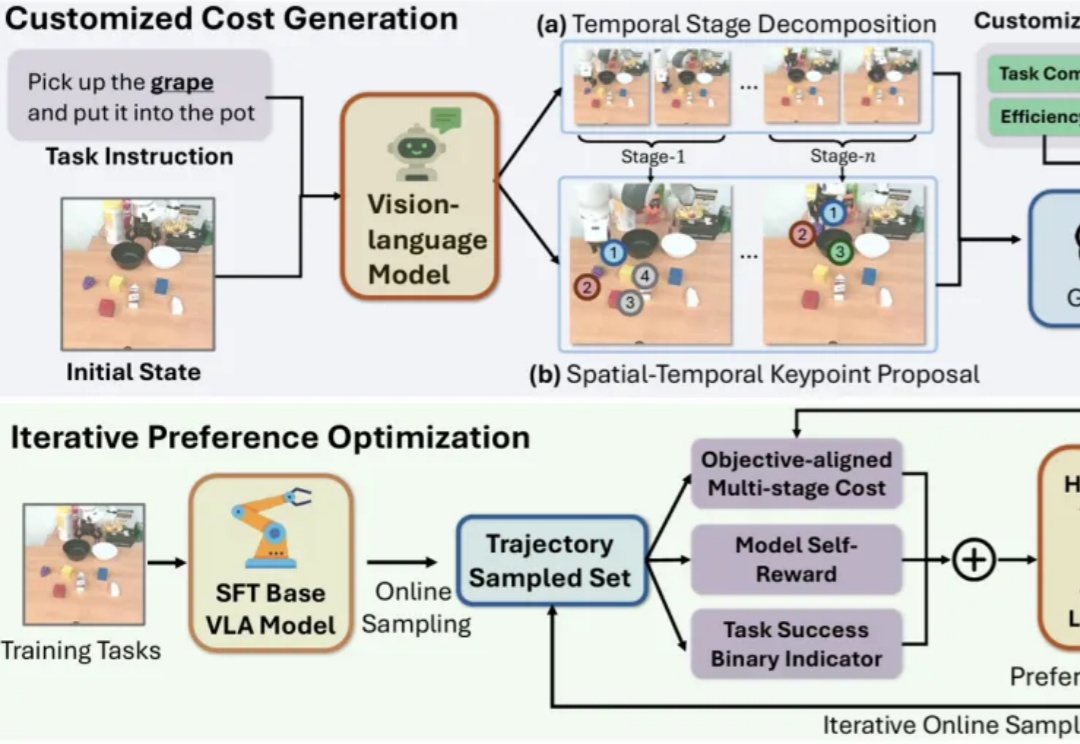
近年来,视觉-语言-动作模型(Vision-Language-Action, VLA)在诸多机器人任务上取得了显著的进展,但它们仍面临一些关键问题,例如由于仅依赖从成功的执行轨迹中进行行为克隆,导致对新任务的泛化能力较差。