
Ilya刚预言完,世界首个原生多模态架构NEO就来了:视觉和语言彻底被焊死
Ilya刚预言完,世界首个原生多模态架构NEO就来了:视觉和语言彻底被焊死全球首个可大规模落地的开源原生多模态架构(Native VLM),名曰NEO。要知道,此前主流的多模态大模型,例如我们熟悉的GPT-4V、Claude 3.5等,它们的底层逻辑本质上其实玩的就是拼接。
来自主题: AI技术研报
9321 点击 2025-12-05 14:46
 搜索
搜索
全球首个可大规模落地的开源原生多模态架构(Native VLM),名曰NEO。要知道,此前主流的多模态大模型,例如我们熟悉的GPT-4V、Claude 3.5等,它们的底层逻辑本质上其实玩的就是拼接。

在 Vision-Language Model 领域,提升其复杂推理能力通常依赖于耗费巨大的人工标注数据或启发式奖励。这不仅成本高昂,且难以规模化。

本文第一作者为刘禹宏,上海交通大学人工智能专业本科四年级学生,相关研究工作于上海人工智能实验室科研实习期间完成。通讯作者为王佳琦、臧宇航,在该研究工作完成期间,均担任上海人工智能实验室研究员。
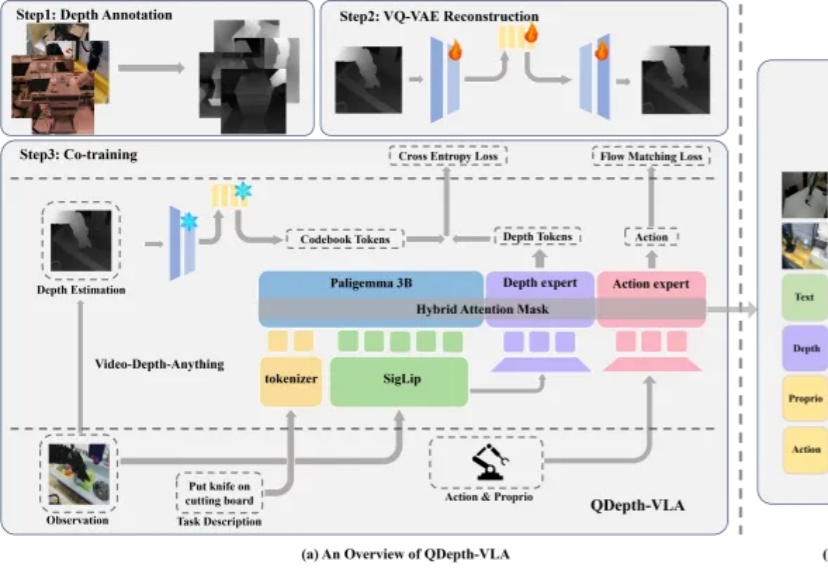
视觉-语言-动作模型(VLA)在机器人操控领域展现出巨大潜力。通过赋予预训练视觉-语言模型(VLM)动作生成能力,机器人能够理解自然语言指令并在多样化场景中展现出强大的泛化能力。然而,这类模型在应对长时序或精细操作任务时,仍然存在性能下降的现象。
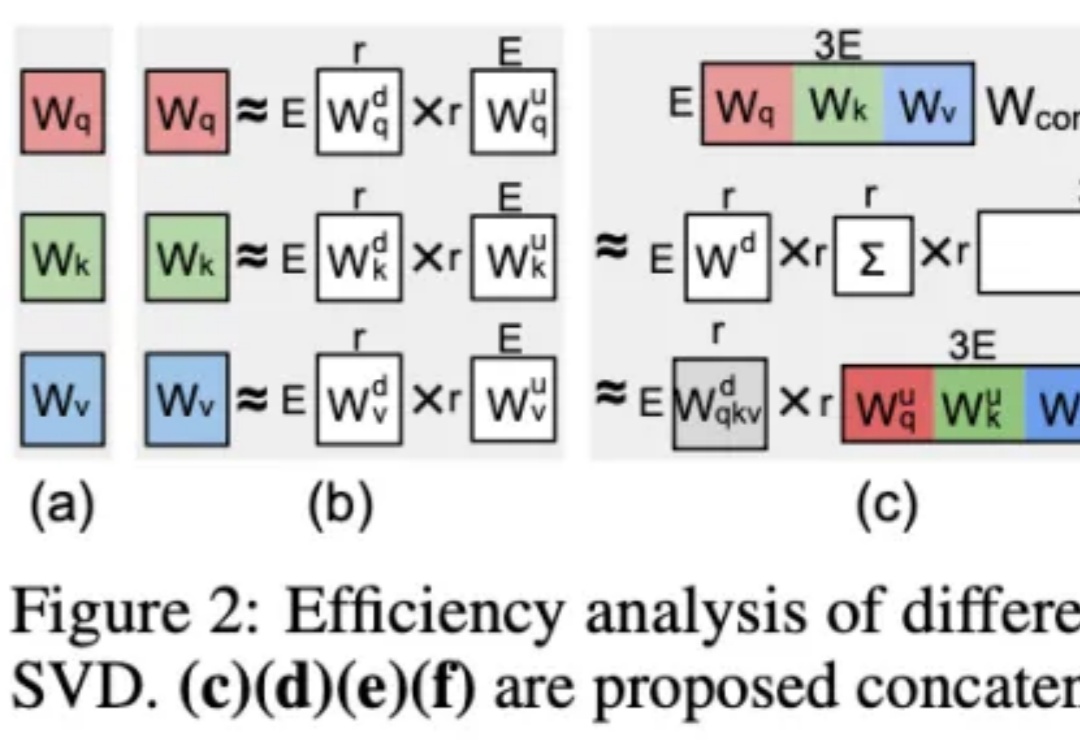
在多模态智能浪潮中,视觉语言模型(Vision-Language Models, VLM)已成为连接视觉理解与语言生成的核心引擎。从图像描述、视觉问答到 AI 教育和交互系统,它们让机器能够「看懂世界、说人话」。
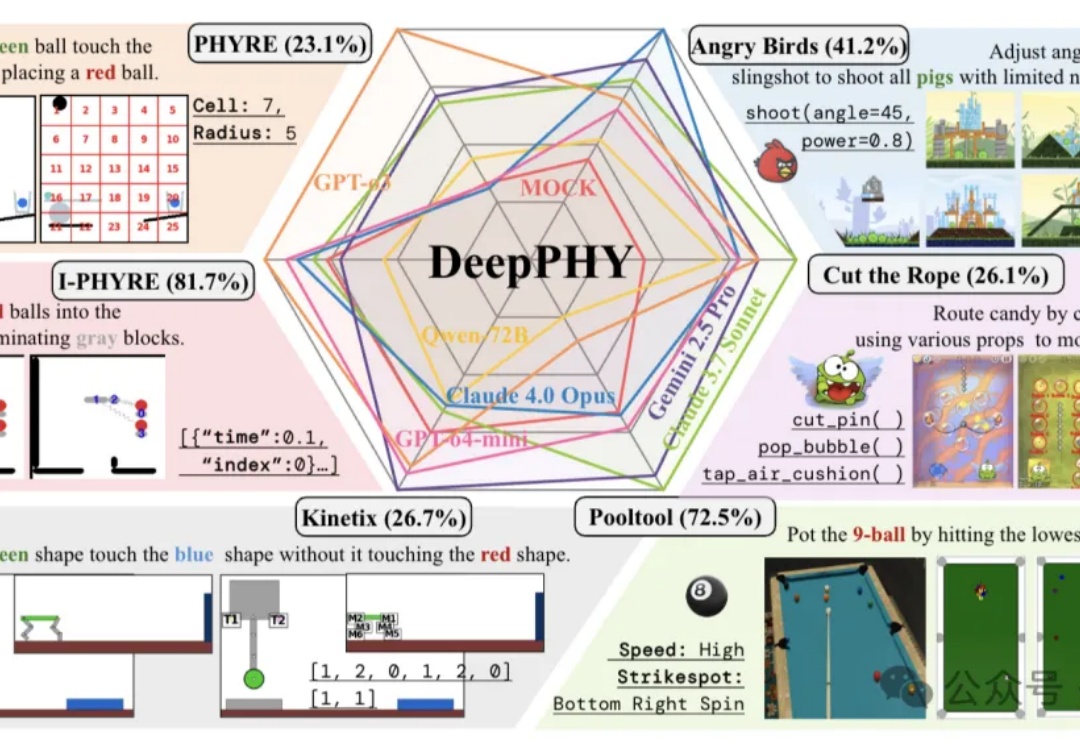
首个系统性评估多模态大模型(VLM)交互式物理推理能力的综合基准来了。
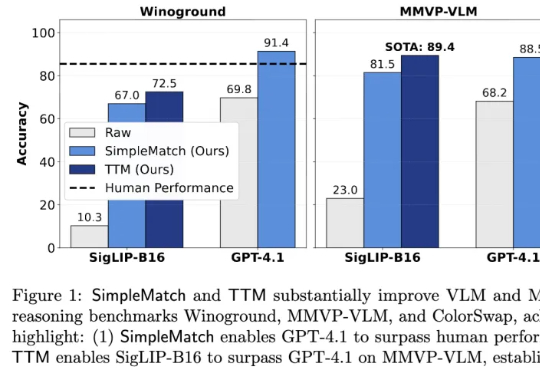
加州大学河滨分校团队发现,AI组合推理表现不佳部分源于评测指标过于苛刻。他们提出新指标GroupMatch和Test-Time Matching算法,挖掘模型潜力,使GPT-4.1在Winoground测试中首次超越人类,0.2B参数的SigLIP-B16在MMVP-VLM基准测试上超越GPT-4.1并刷新最优结果。这表明模型的组合推理能力早已存在,只需合适方法在测试阶段解锁。
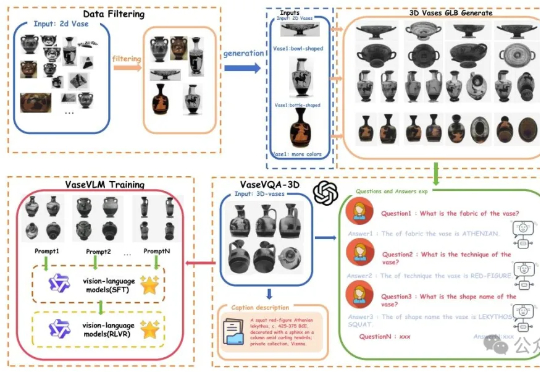
现在AI都懂文物懂历史了。一项来自北京大学的最新研究引发关注:他们推出了全球首个面向古希腊陶罐的3D视觉问答数据集——VaseVQA-3D,并配套推出了专用视觉语言模型VaseVLM。这意味着,AI正在从“识图机器”迈向“文化考古Agent”。
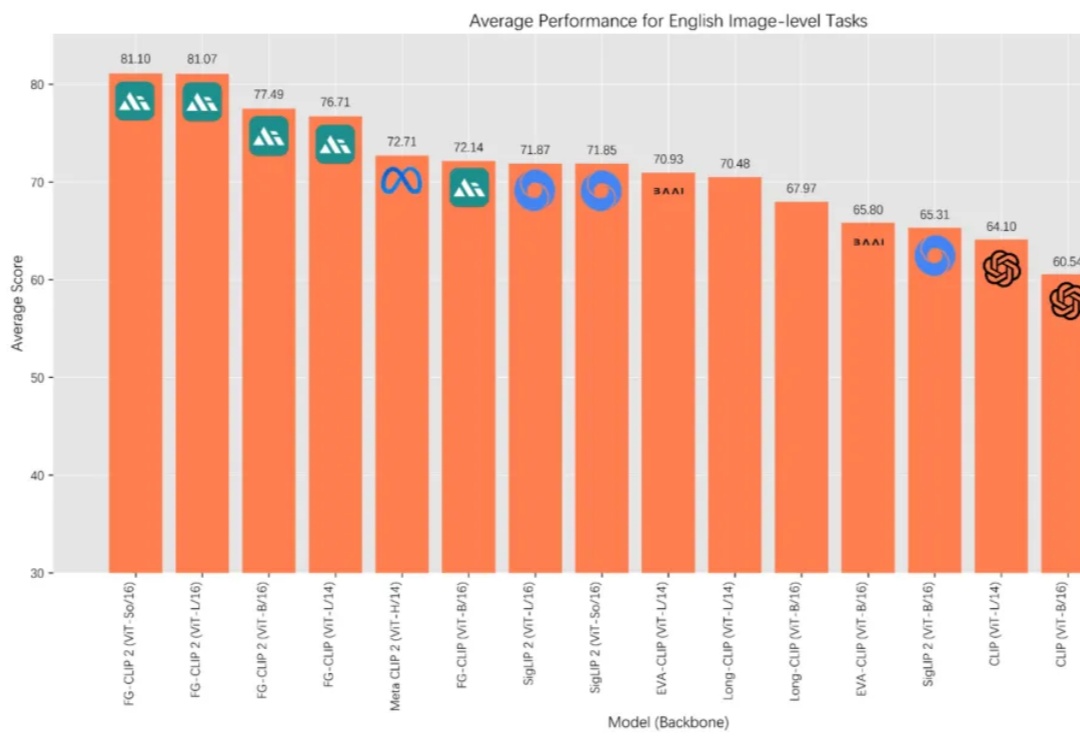
在 AI 多模态的发展历程中,OpenAI 的 CLIP 让机器第一次具备了“看懂”图像与文字的能力,为跨模态学习奠定了基础。如今,来自 360 人工智能研究院冷大炜团队的 FG-CLIP 2 正式发布并开源,在中英文双语任务上全面超越 MetaCLIP 2 与 SigLIP 2,并通过新的细粒度对齐范式,补足了第一代模型在细节理解上的不足。
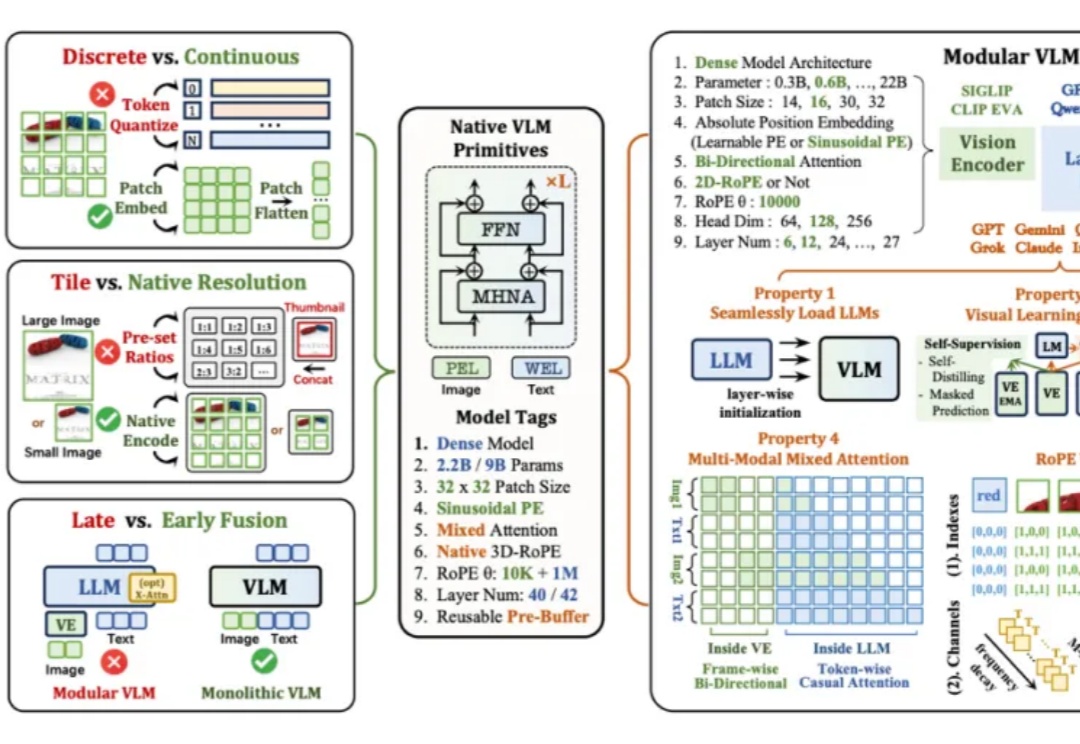
当下主流的视觉语言模型(Vision-Language Models, VLM),通常都采用这样一种设计思路:将预训练的视觉编码器与大语言模型通过投影层拼接起来。这种模块化架构成就了当前 VLM 的辉煌,但也带来了一系列新的问题——多阶段训练复杂、组件间语义对齐成本高,不同模块的扩展规律难以协调。