
与DeepSeek-OCR不谋而合,NeurIPS论文提出让LLM像人一样读长文本
与DeepSeek-OCR不谋而合,NeurIPS论文提出让LLM像人一样读长文本在处理短文本时,大语言模型(LLM)已经表现出惊人的理解和生成能力。但现实世界中的许多任务 —— 如长文档理解、复杂问答、检索增强生成(RAG)等 —— 都需要模型处理成千上万甚至几十万长度的上下文。
来自主题: AI技术研报
7454 点击 2025-11-10 15:12
 搜索
搜索
在处理短文本时,大语言模型(LLM)已经表现出惊人的理解和生成能力。但现实世界中的许多任务 —— 如长文档理解、复杂问答、检索增强生成(RAG)等 —— 都需要模型处理成千上万甚至几十万长度的上下文。

在NeurIPS 2025论文中,来自「南京理工大学、中南大学、南京林业大学」的研究团队提出了一个极具突破性的框架——VIST(Vision-centric Token Compression in LLM),为大语言模型的长文本高效推理提供了全新的「视觉解决方案」。值得注意的是,这一思路与近期引起广泛关注的DeepSeek-OCR的核心理念不谋而合。
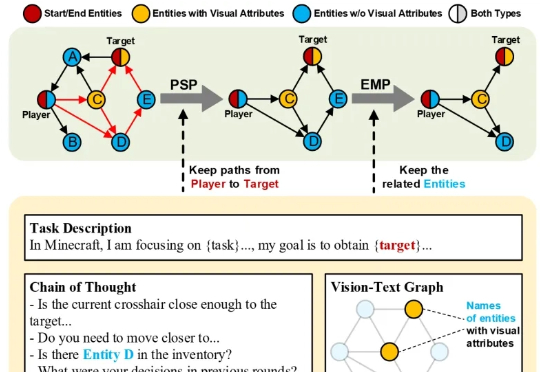
在大多数人眼中,《我的世界》(Minecraft)只是一款自由度极高的沙盒游戏。 而在香港科技大学(广州)与腾讯联合团队的眼中,它却是一座可以演练通用人工智能的“数字练兵场”。
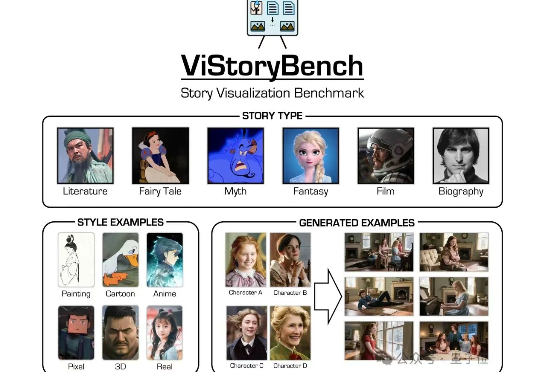
随着AIGC技术的进步,连环画与故事绘本生成(故事可视化)逐渐引发学界与业界的广泛关注,成为电影生成叙事性的基础。
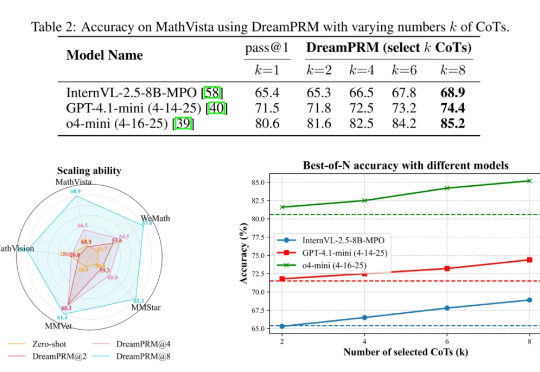
使用过程奖励模型(PRM)强化大语言模型的推理能力已在纯文本任务中取得显著成果,但将过程奖励模型扩展至多模态大语言模型(MLLMs)时,面临两大难题:

Vista-LLaMA 在处理长视频内容方面的显著优势,为视频分析领域带来了新的解决框架。

大型多模态模型会做数学题吗?在UCLA等机构最新发布的MathVista基准上,即使是当前最强的GPT-4V也会感到「挫败感」。