GPT-5编程成绩有猫腻!自删23道测试题,关键基准还是自己提的
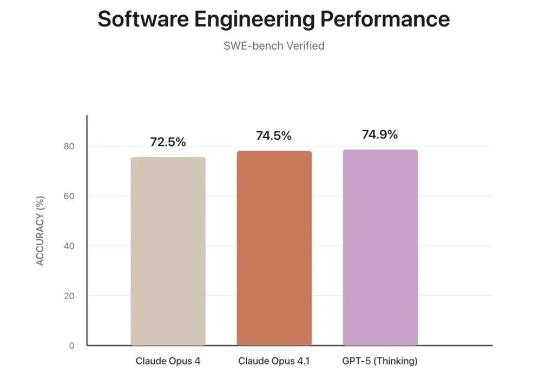
GPT-5编程成绩有猫腻!自删23道测试题,关键基准还是自己提的别急着用GPT-5编程了,可能它能力没有你想象中那么强。 有人发现,官方测试编程能力用的SWE-bench Verified,但货不对板,只用了477个问题。
来自主题: AI资讯
8767 点击 2025-08-12 17:07
 搜索
搜索
别急着用GPT-5编程了,可能它能力没有你想象中那么强。 有人发现,官方测试编程能力用的SWE-bench Verified,但货不对板,只用了477个问题。
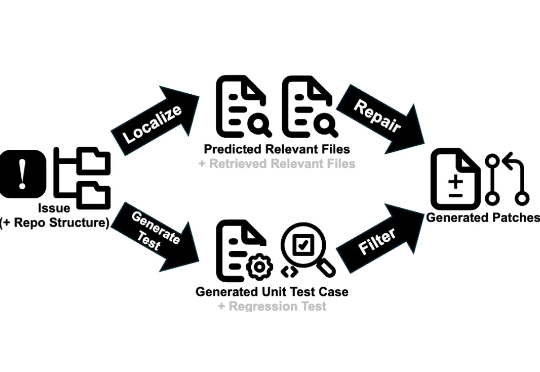
近日,一项由北京大学、字节跳动 Seed 团队及香港大学联合进行的研究,提出了一种名为「SWE-Swiss」的完整「配方」,旨在高效训练用于解决软件工程问题的 AI 模型。研究团队推出的 32B 参数模型 SWE-Swiss-32B,在权威基准 SWE-bench Verified 上取得了 60.2% 的准确率,在同尺寸级别中达到了新的 SOTA。
昨天深夜,月之暗面发布了开源代码模型Kimi-Dev-72B。这个模型在软件工程任务基准测试SWE-bench Verified上取得了60.4%的成绩,创下开源模型新纪录,超越了包括DeepSeek在内的多个竞争对手。
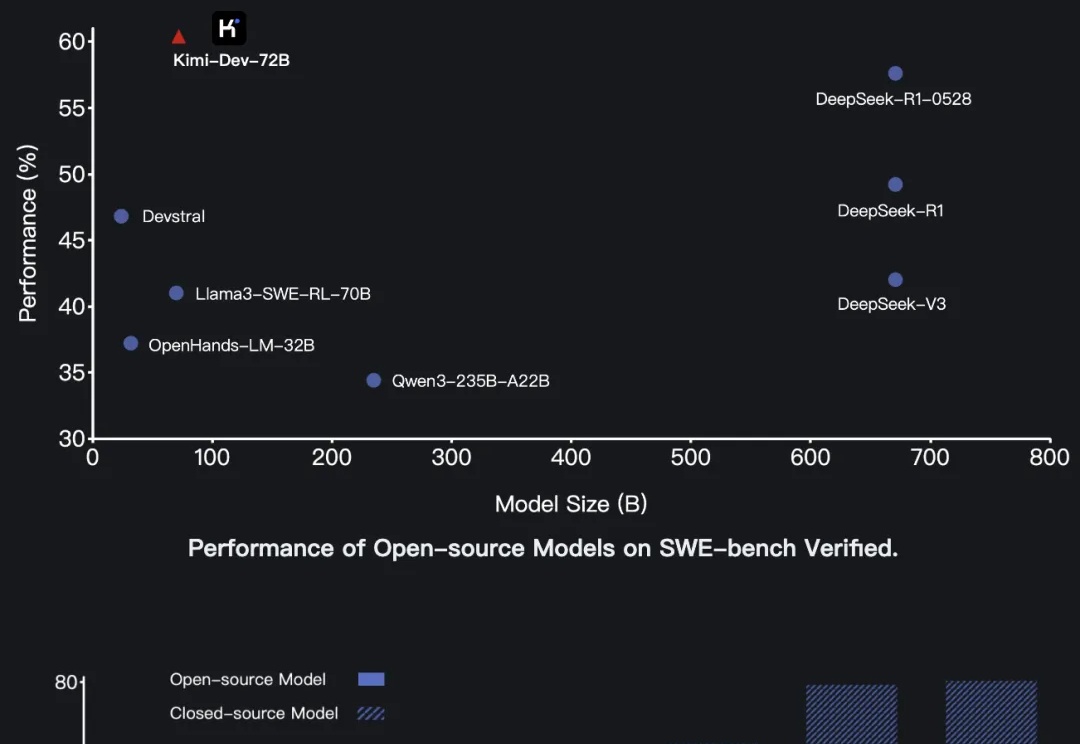
深夜,沉寂已久的Kimi突然发布了新模型—— 开源代码模型Kimi-Dev,在SWE-bench Verified上以60.4%的成绩取得开源SOTA。

视频内容的快速增长给视频检索技术,特别是细粒度视频片段检索(VCMR),带来了巨大挑战。VCMR 要求系统根据文本查询从视频库中精准定位视频中的匹配片段,需具备跨模态理解和细粒度视频理解能力。
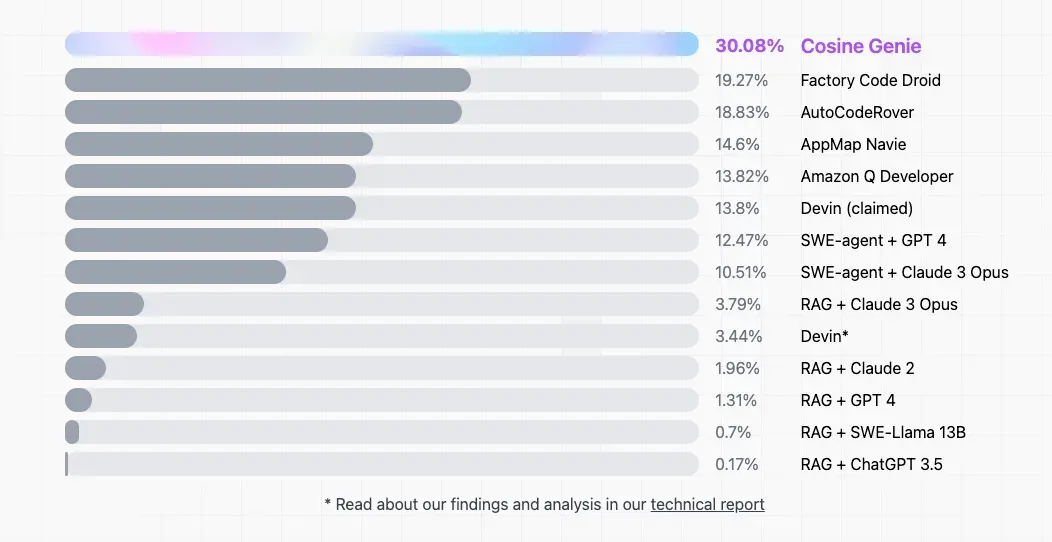
一直以来,大模型的编程能力都备受关注,超强 AI 程序员 Devin 的问世更是将「AI 能否替代程序员」这一话题推上了风口浪尖。最近,Devin 也迎来了新对手 —— 初创公司 Cosine 推出的自主 AI 程序员 Genie。该公司表示,Genie 的表现轻松超越了 Devin,在第三方基准测试 SWE-bench 上的得分为 30%,而 Devin 的得分仅为 13.8%。