
英特尔:CPU的痛就像送外卖
英特尔:CPU的痛就像送外卖英特尔,真是越来越会玩了—— 因为它把优化CPU这件事的痛点,直接搞得像送外卖似的:
来自主题: AI资讯
7790 点击 2026-04-20 14:05
 搜索
搜索
英特尔,真是越来越会玩了—— 因为它把优化CPU这件事的痛点,直接搞得像送外卖似的:

Claude Code 今天上了个新功能叫 /ultraplan,做的事情很好理解:在动手写代码之前,先在网页上给你看一份完整的实施方案。你可以读,可以改,甚至可以在方案里给 Claude 留评论。觉得没问题了,点一下「批准」,Claude 才开始动手。
告别Token老虎,给大模型来了个“减脂增肌”。
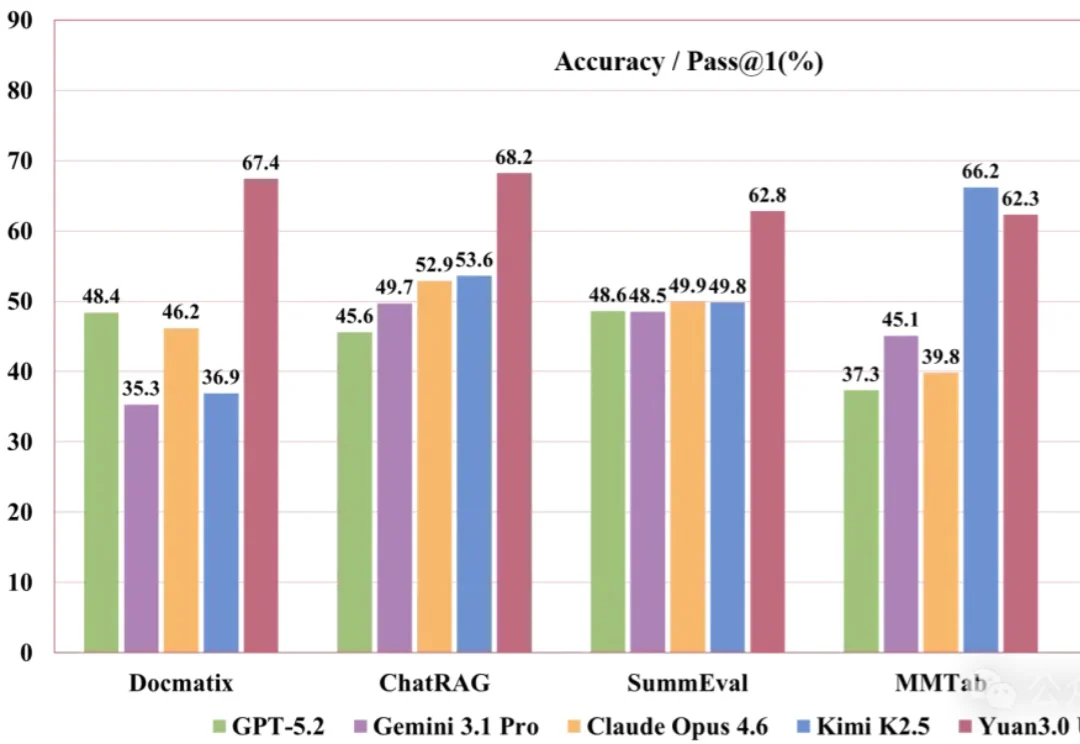
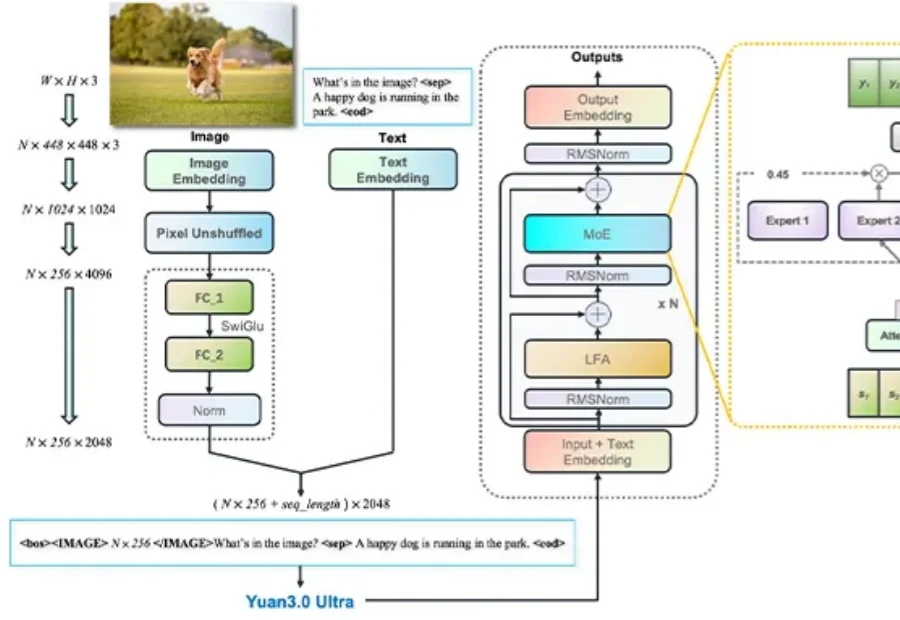
刚刚,YuanLab.ai团队正式开源发布源Yuan3.0 Ultra多模态基础大模型。
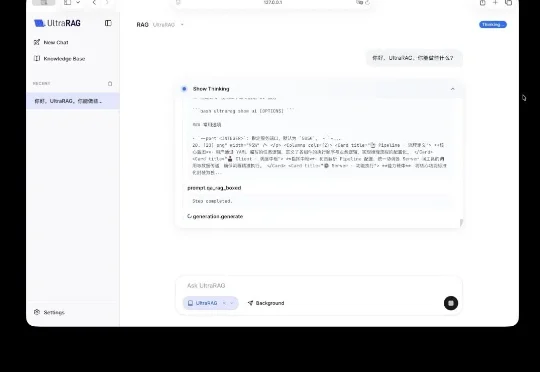
今天,清华大学 THUNLP 实验室、东北大学 NEUIR 实验室、OpenBMB 、面壁智能与 AI9Stars 联合发布 UltraRAG 3.0 ,针对上述痛点,为科研工作者与开发者打造更懂开发者的技术框架,具备 3 大核心优势:

英特尔发布年度旗舰AI PC芯片——第三代酷睿Ultra系列处理器(代号Panther Lake)。这是首款基于Intel 18A制程(1.8nm级)的计算平台,将AI PC引入埃米时代,端侧AI算力多达180TOPS。
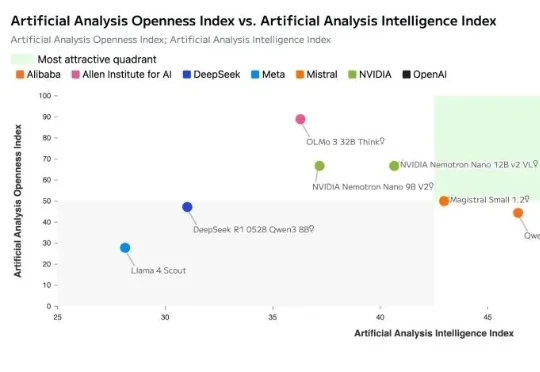
就在刚刚,英伟达正式开源发布了其新一代AI模型:NVIDIA Nemotron 3。Nemotron 3 系列由三种型号组成:Nano、Super 和 Ultra。官方介绍其具备强大的智能体、推理和对话能力。

太劲爆了!不过半月,谷歌DeepMind终于放出了IMO最强金牌模型——Gemini 3 Deep Think。今天,Gemini 3 Deep Think已在Gemini App上线,所有Ultra用户即可体验。
就在刚刚,DeepSeek 又悄咪咪在 Hugging Face 上传了一个新模型:DeepSeek-Math-V2。顾名思义,这是一个数学方面的模型。它的上一个版本 ——DeepSeek-Math-7b 还是一年多以前发的。当时,这个模型只用 7B 参数量,就达到了 GPT-4 和 Gemini-Ultra 性能相当的水平。相关论文还首次引入了 GRPO,显著提升了数学推理能力。

一位在互联网上近乎「隐形」的27岁创始人,却同时赢得奥特曼与孙正义的重注,豪言要打造一个「现代贝尔实验室」。