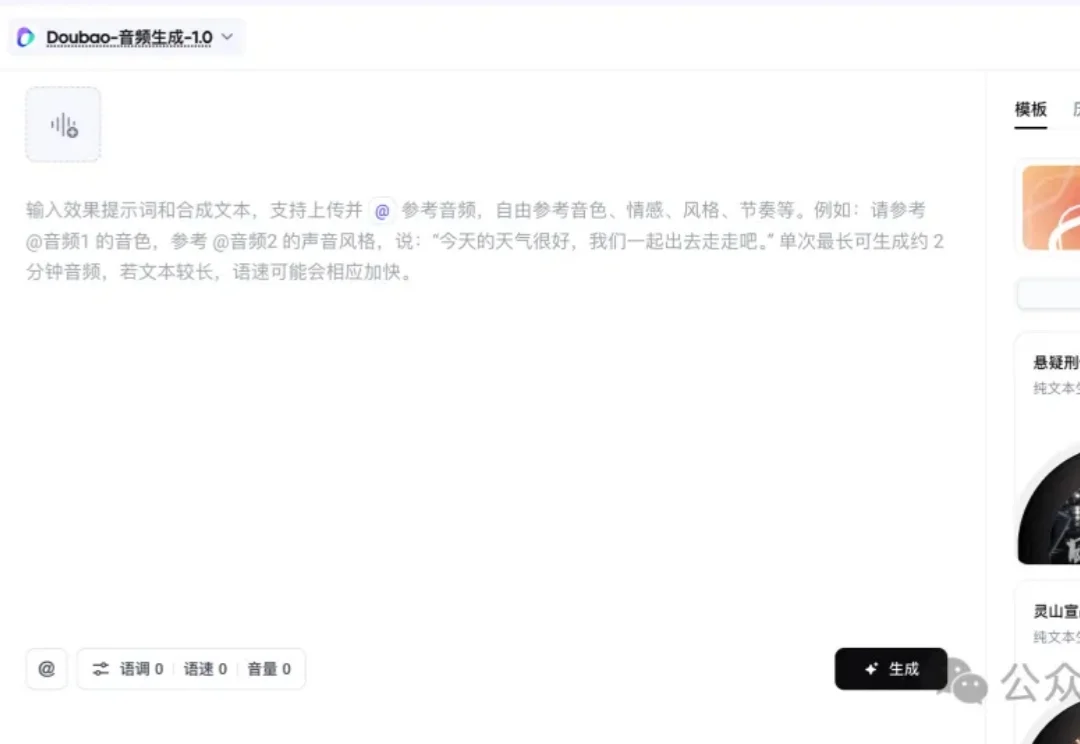
实测豆包音频生成模型:语音模型的Seedance2.0时刻来了!
实测豆包音频生成模型:语音模型的Seedance2.0时刻来了!火山引擎今天上线了全新的语音模型—— 豆包音频生成模型 1.0(Seed-Audio 1.0)。
来自主题: AI产品测评
7985 点击 2026-06-24 10:29
 搜索
搜索
火山引擎今天上线了全新的语音模型—— 豆包音频生成模型 1.0(Seed-Audio 1.0)。
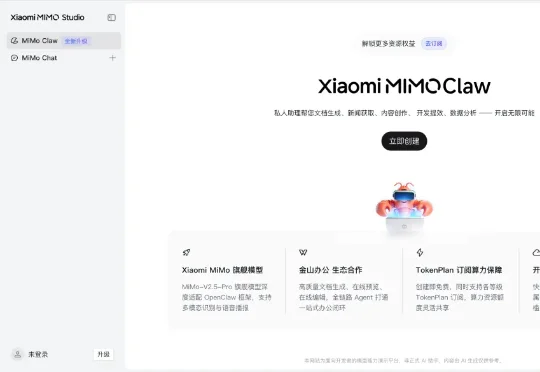
昨晚,小米正式上线了Xiaomi MiMo Claw,一款云端Claw类产品,搭载与OpenClaw框架深度适配的MiMo-V2.5-Pro旗舰模型,同时联动了金山办公生态,实现一站式办公,现在可以在MiMo Studio上进行体验。
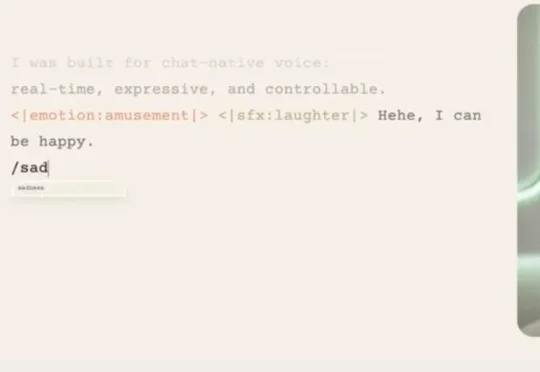
Boson AI 与 SGLang-Omni 团队宣布,SGLang-Omni 已完成对 Higgs Audio v3 TTS 的端到端 Serving 支持。作为一家成立于 2023 年的 AI 基础设施公司,李沐与 Alex Smola共同创立了 Boson AI,聚焦大模型时代的系统与基础设施创新。
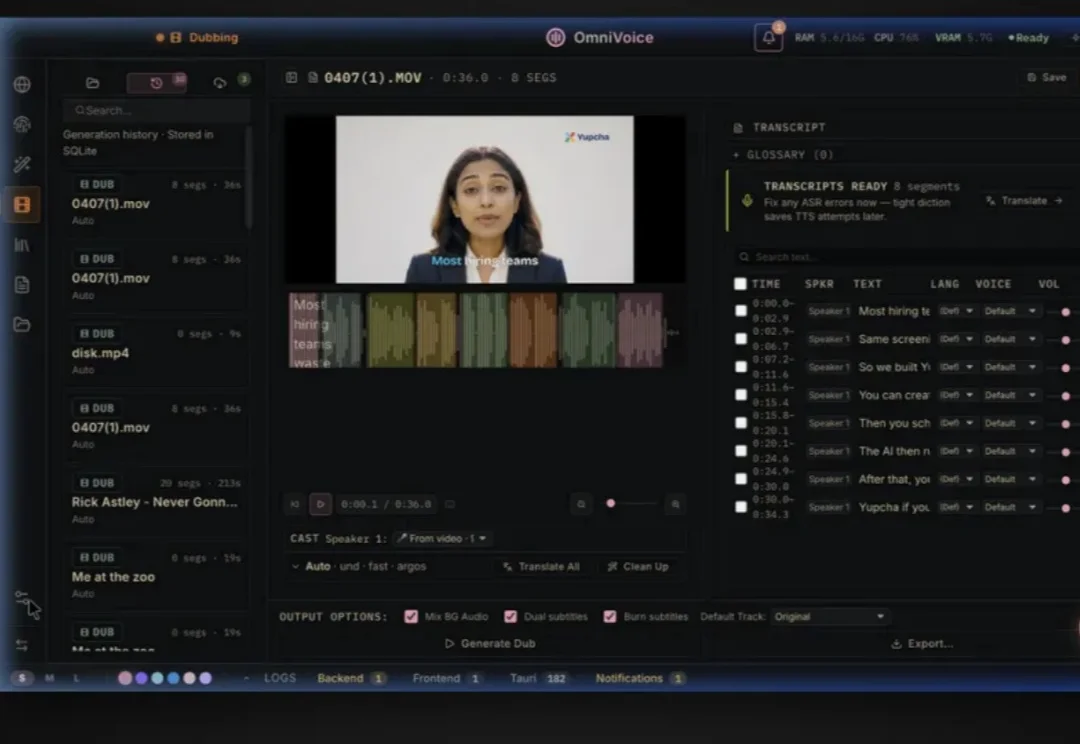
ElevenLabs的声音克隆和长文本音频生成质量确实很好,但也太贵了。
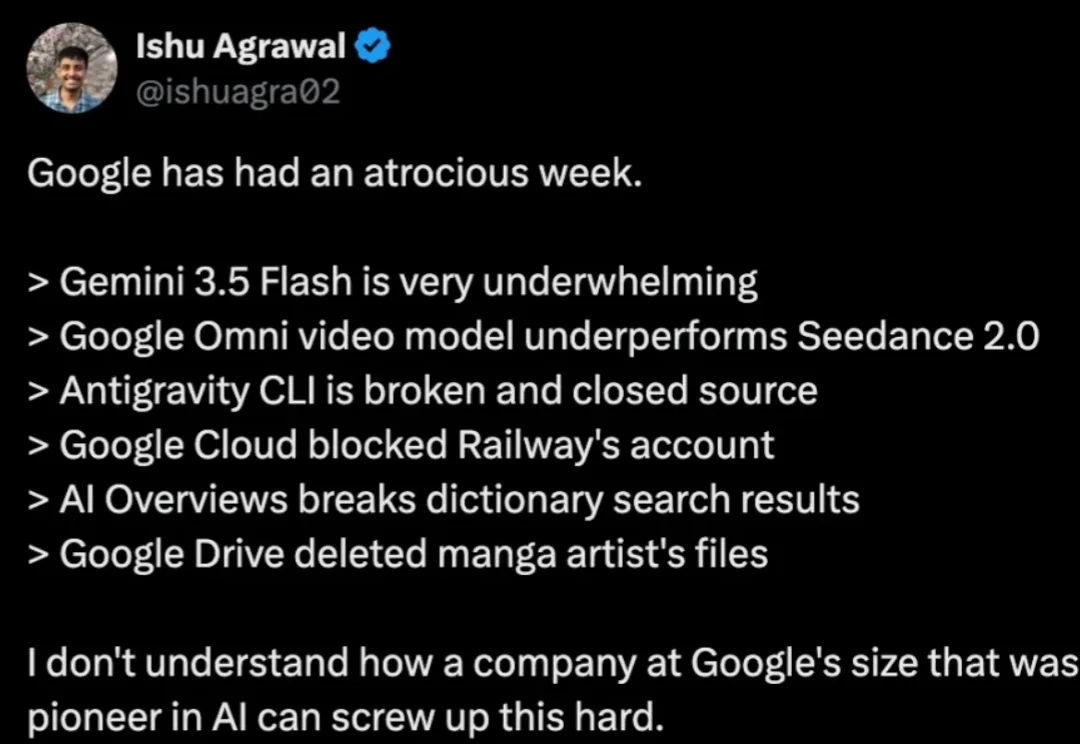
最近,谷歌的日子不太好过。
很多人以为,AI视频的终点是“生成一段让人惊艳的画面”。

a16z Speedrun SR006里有60家公司,57%做B2B。只有一家做Audio。我们和它的创始人Artin聊了45分钟,发现它踩中的东西比看起来大得多。SUN — AI-native audio learning, built around youAI让音频内容的生成成本暴跌80倍,但没有人把这件事变成一个主动为你服务的消费级学习产品

《读佳》获知,Soul推出AI语音创作平台“AudioFactory”,基于生成式人工智能模型技术为用户提供丰富、多样的AI功能服务,包括但不限于播客AI生成、语音生成合成、AI生成文案等,具体以播客生成、音色克隆等AI语音功能为主,或为其冲击港股IPO再添技术筹码。

阶跃星辰今日发布新一代自动语音识别模型StepAudio 2.5 ASR。该模型面向语音转写与长音频处理场景,在架构上引入Multi-Token Prediction(多Token预测)以提升推理效率,并通过扩展上下文窗口强化长内容识别能力。
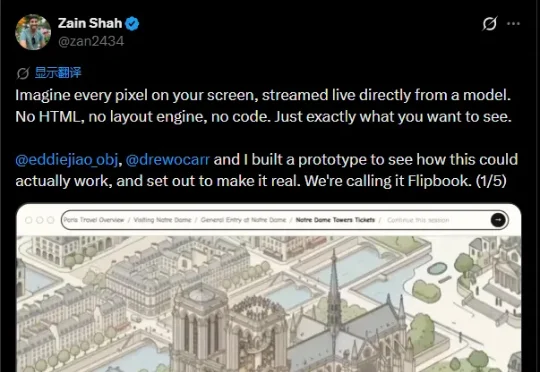
想象一下:你打开浏览器,没有代码、没有 HTML、没有 CSS 布局引擎。屏幕上每一帧画面,都是 AI 模型实时生成的像素视频流。满满的科幻降临既视感!这就是 Zain Shah(前 OpenAI、YC 校友)和团队刚刚发布的 Flipbook 原型。