GUI智能体训练迎来新范式!半在线强化学习让7B模型媲美GPT-4o
GUI智能体训练迎来新范式!半在线强化学习让7B模型媲美GPT-4o浙江大学与通义实验室Mobile-Agent团队在UI-R1的基础上,推出全新研究成果——UI-S1,提出了一种名为半在线强化学习(Semi-online Reinforcement Learning)的创新训练范式。
来自主题: AI技术研报
8529 点击 2025-09-24 09:49
 搜索
搜索
浙江大学与通义实验室Mobile-Agent团队在UI-R1的基础上,推出全新研究成果——UI-S1,提出了一种名为半在线强化学习(Semi-online Reinforcement Learning)的创新训练范式。
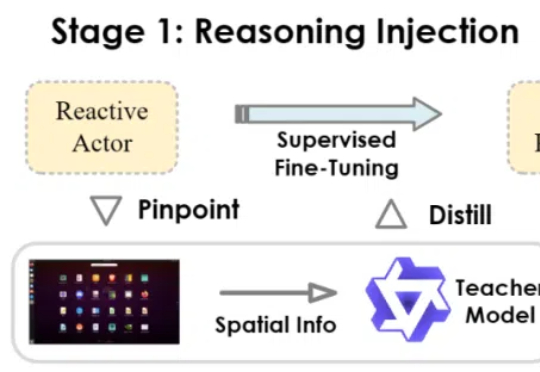
当前,多模态大模型驱动的图形用户界面(GUI)智能体在自动化手机、电脑操作方面展现出巨大潜力。然而,一些现有智能体更类似于「反应式行动者」(Reactive Actors),主要依赖隐式推理,面对需要复杂规划和错误恢复的任务时常常力不从心。
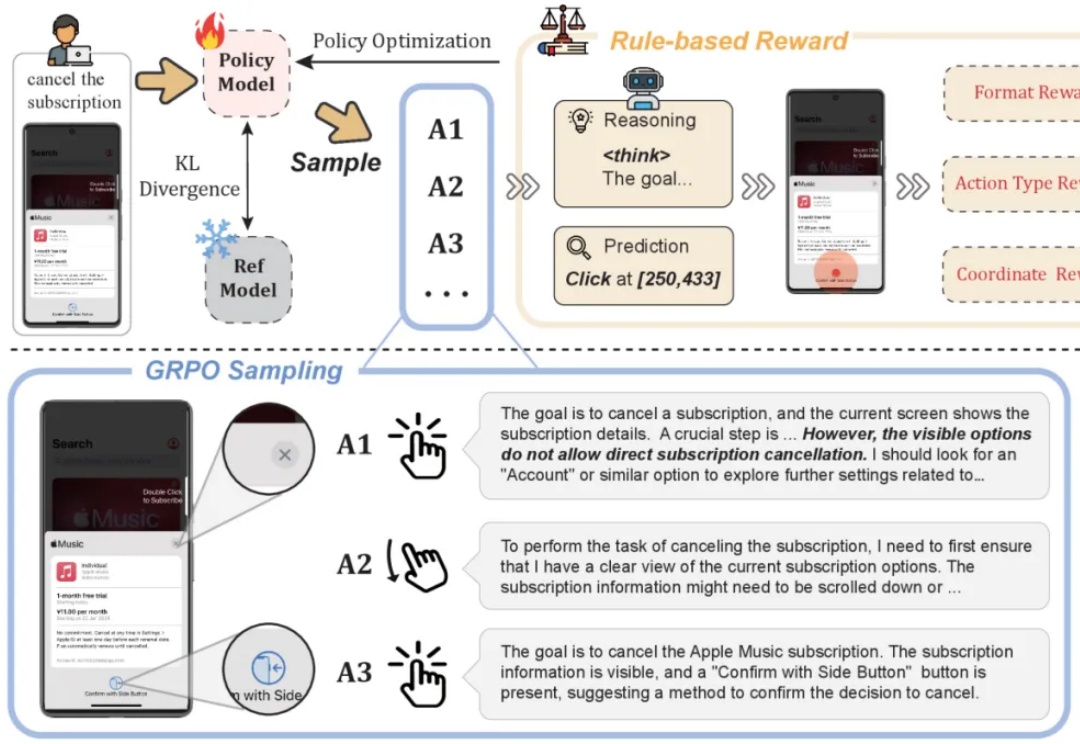
基于规则的强化学习(RL/RFT)已成为替代 SFT 的高效方案,仅需少量样本即可提升模型在特定任务中的表现。