
刚刚,微软全新一代自研AI芯片Maia 200问世
刚刚,微软全新一代自研AI芯片Maia 200问世一觉醒来,我们看到了微软自研 AI 芯片的最新进展。 微软原定于 2025 年发布的下一代 AI 芯片 Maia 200,终于在今天问世!根据微软官方介绍,Maia 200 作为一款强大的 AI 推理加速器,旨在显著改善 AI token 生成的经济性。
来自主题: AI资讯
9731 点击 2026-01-27 13:01
 搜索
搜索
一觉醒来,我们看到了微软自研 AI 芯片的最新进展。 微软原定于 2025 年发布的下一代 AI 芯片 Maia 200,终于在今天问世!根据微软官方介绍,Maia 200 作为一款强大的 AI 推理加速器,旨在显著改善 AI token 生成的经济性。
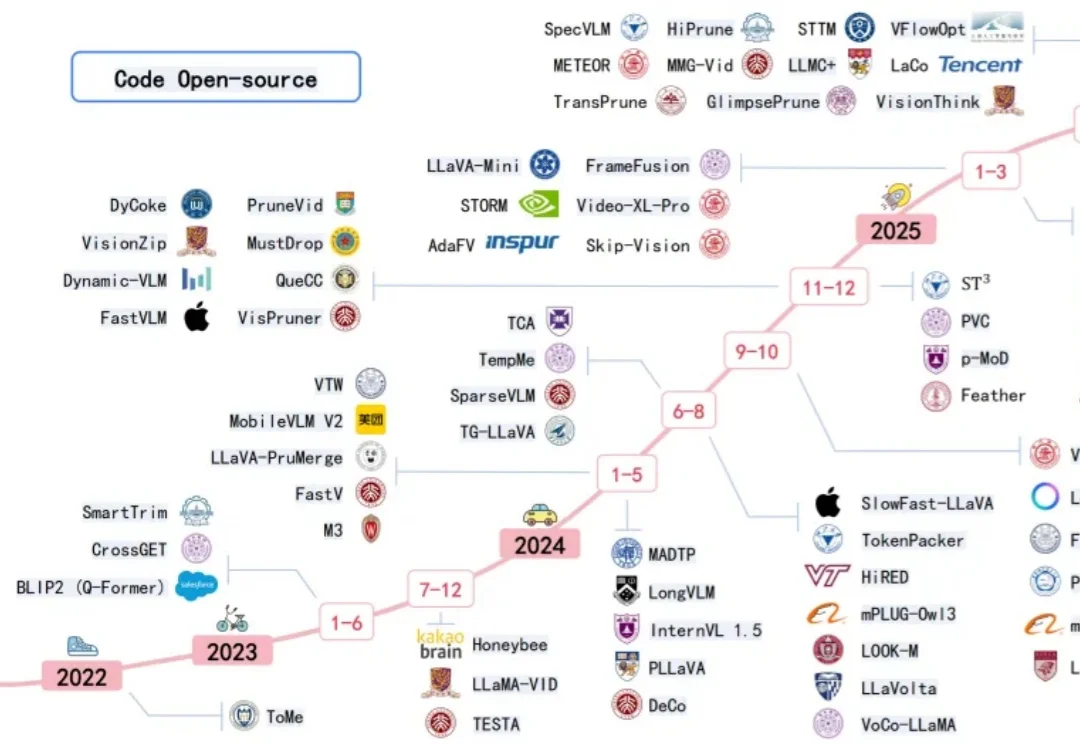
近年来多模态大模型在视觉感知,长视频问答等方面涌现出了强劲的性能,但是这种跨模态融合也带来了巨大的计算成本。高分辨率图像和长视频会产生成千上万个视觉 token ,带来极高的显存占用和延迟,限制了模型的可扩展性和本地部署。

2025 年 6 月发售,累计销量超 12 万台,其中 12 月单月销量超 5 万台。单日 Token 消耗量已超百亿,在火山引擎 AI 硬件榜单中位列第一。在退货率普遍居高不下的硬件领域,净退货率保持在 10% 以下。

在当前的AI Research浪潮中,Autonomous Agents已经改变了我们获取信息的方式——从被动接收到主动检索。

在2026年的世界经济论坛上,微软 CEO 萨提亚·纳德拉(Satya Nadella)与贝莱德 CEO 拉里·芬克(Larry Fink)进行了一场对话。
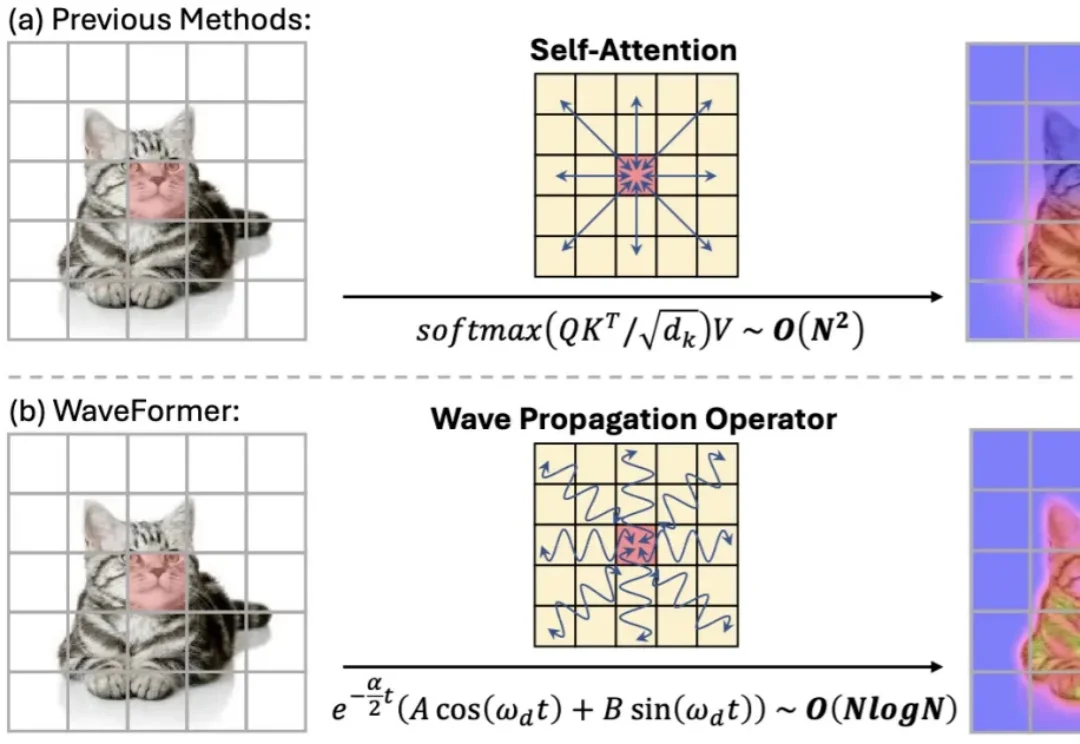
“全局交互” 几乎等同于 self-attention:每个 token 都能和所有 token 对话,效果强,但代价也直观 —— 复杂度随 token 数平方增长,分辨率一高就吃不消。现有方法大多从 “相似度匹配” 出发(attention),或从 “扩散 / 传导” 出发(热方程类方法)。但热方程本质上是一个强低通滤波器:随着传播时间增加,高频细节(边缘、纹理)会迅速消失,导致特征过平滑。
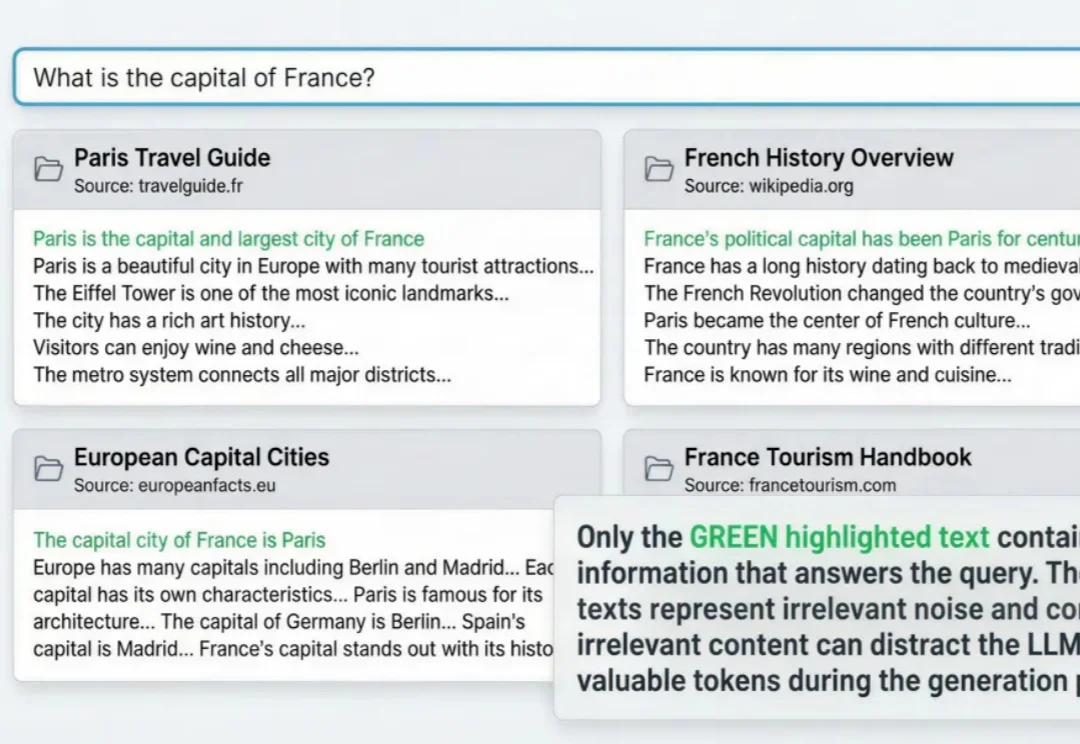
RAG与agent用到深水区,一定会遇到这个问题: 明明架构很完美,私有数据也做了接入,但项目上线三天,不但token账单爆了,模型输出结果也似乎总差点意思。
哈喽,大家好,我是刘小排。 使用Claude Code最大的痛点是什么?其实不是贵,而是封号。因为就算使用Claude Max Plan 每月$200美金,虽然看上去贵,但是一个月能轻松用上价值数千美金甚至上万美金的token,是很便宜的。

几天前,DeepSeek 毫无预兆地更新了 R1 论文,将原有的 22 页增加到了现在的 86 页。新版本充实了更多细节内容,包括首次公开训练全路径,即从冷启动、训练导向 RL、拒绝采样与再微调到全场景对齐 RL 的四阶段 pipeline,以及「Aha Moment」的数据化验证等等。

当大模型竞争转向后训练,继续为闲置显卡烧钱无异于「慢性自杀」。如今,按Token计费的Serverless模式,彻底终结了算力租赁的暴利时代,让算法工程师真正拥有了定义物理世界的权利。